
你知道CPU结构也会影响Redis性能吗?
啦啦啦,我是卖身不卖艺的二哈,ε=(´ο`*)))唉错啦(我是开车的二哈),我又来了,铁子们一起开车呀!
今天来分析下CPU结构对Redis性能会有影响吗?
在进行Redis性能分析的时候,通常我们会考虑下面这些方面,如:
1. 缩短 key 的长度
2. 禁止使用 keys *
我们都知道 keys *, 在使用的时候 Redis 会处于阻塞状态,导致其它任何命令在你的 Redis 实例中都无法执行。这个情况在 Redis 数据量大的时候就很明显,严重影响系统的运行。(一般我们用 scan 来代替)
3. 进行数据压缩
在把数据存入 Redis 中,我们一般不会使用完整全名的数据,一般会进行适当的数据压缩,这样可以提高 Redis 性能,方便我们数据的储存。
4. 设置过期时间
我们对一些不是永久性需要的数据,可以进行键的过期时间设置,这样到时间后,数据就会自动清除,节省我们 Redis 存储空间(内存)。
5. 使用回收策略
为数据设置相关的过期回收策略,节省内存的开销,提高 Redis 运行的性能。( Redis 目前有8种回收策略,有兴趣可以查看 redis.conf ,多了LFU)。
6. 适当使用 bit (位图)
适当使用 bit,可节省我们 Redis 存储的成本,即内存的大小。
7. 对所存储的数据字段进行优化
如:我们只需要在 Redis 存储关键信息即可,详细信息存储到磁盘上即可。
8. 使用管道进行数据操作
对于命令执行操作,我们要使用管道 pipeline,这样可以节省 Redis 传输过程的成本,提高 Redis 的性能。我们知道如果不适用管道,命令是一个一个进行操作,如果我们加上管道,这样由原来的单条命令变成多条命令进行传输操作,节省多次传输过程的网络开销。
N .... (还有很多很多~~)
但是,我们可能有时候会真正忽略 Redis 运行的前提条件,单核 CPU 和多核 CPU 对 Redis 性能影响也是相差甚远。在计算机组成原理中,我们都知道 CPU 是计算机的核心构成之一,中央处理器(Central Processing Unit),是计算机系统的运算和控制中心。一个CPU处理器中一般包含有多个运行核心(物理核),运行核心我们也叫作物理核,一般包含一级缓存(L1 Cache)和二级缓存(L2 Cache)。其架构图如下所示:
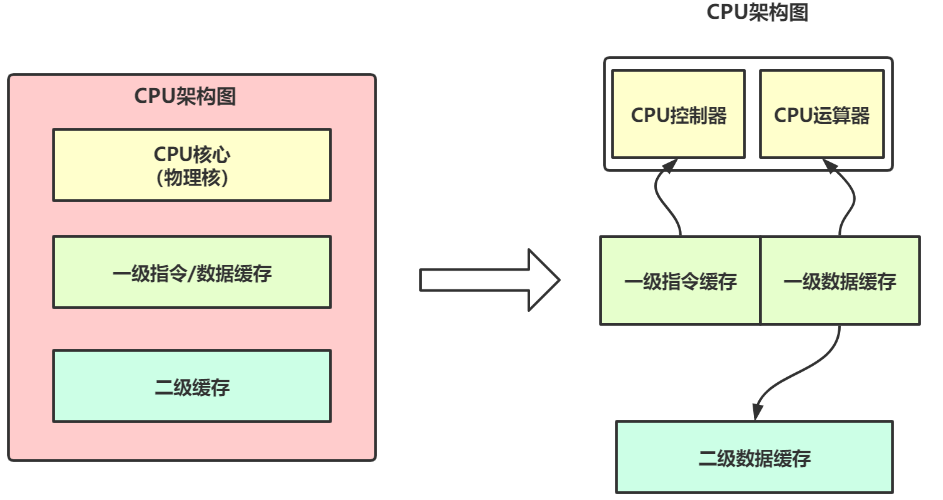
对于 L1 缓存和 L2 缓存,在每个物理核上都是独自拥有的,访问速度非常快,基本都在 ns 级别。我们设想如果把数据运行的指令放在这两个缓存上,那么可以大大提高计算机的访问性能。这样我们可以设想这样一个情形:
如果,我们把 Redis 实例的数据和指令绑定到一个 CPU 核上,那么当 Redis 频繁执行数据访问和操作时,都是基于CPU 上的缓存进行操作,那么性能是不是大大的提高了,没错,事实就是如此。但是,我们电脑一般都是多核 CPU 的,在进行数据访问和操作时,系统不会只有一个线程在进行操作,是有很多很多的线程在同时进行操作,会同时操作我们的CPU,也就是我们所说的多线程操作CPU。如果一个线程此时在CPU1上运行,后来又跑到了CPU2上运行,这时在CPU1上保留的数据和指令不在CPU2,这时要重新进行数据加载,会降低线程执行的效率,上述所发生的过程,我们也叫作上下文切换,这在操作系统内核环境下,是很常见的现象。
所以,我们要避免线程来回在CPU上进行切换,导致指令和数据进行多次加载,增加锁处理的时间。我们从CPU结构出发,如果在多核CPU上,如果我们的每个Redis实例都只在一个CPU上运行的话,那么我们离解决问题的步伐是不是又更近了一步。(问题都是一步一步的剖析,慢慢解开其真容(*╹▽╹*))。
对相关进程进行绑定,我们可以使用 taskset :
taskset 是依据线程PID(TID)查询或设置线程的CPU亲和性(Affiliation)(与哪个CPU核心绑定)。
如果有伙伴们不知道 taskset 如何使用,没关系,可以使用 man 或者 help 手册进行查看相关参数使用( man taskset 或 taskset -h )。在进行绑定的时候,我们要知道自己机器的CPU的核数( cat /proc/cpuinfo ),以方便我们准确的进行CPU绑定,不会说不知道自己CPU核数随便绑定一个超过自己CPU核数的数。
例子:假如我们要绑定CPU0这个CPU核,那么命令如下:
taskset -c 0 ./redis-server
这时,我们可以通过 Redis 的压测工具进行相关测试 redis-benchmark
例如:对 GET 、PUT 和 SET 进行测试:
redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 10000 -t get
redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 10000 -t put
redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 10000 -t set
可以发现Redis实例的性能大大提升。
Redis实例还可以和网络中断程序绑在 CPU Socket 上,这样能减小Redis 跨 Socket 访问内存的网络开销。(在网络传输过程中,这也是一个非常值得考虑优化的问题)。
这里或许会有伙伴会问了(一个cpu物理核内部不是还有逻辑核吗,我们不应该绑定在逻辑核上吗?)
这个小伙伴思考的好!别急,我先给你们维基百科(面向搜索引擎)下这些知识点:
- CPU:中央处理单元,记住:CPU不等于物理核,也不等于逻辑核。
- 物理核: 真实的cpu核,可以单独执行指令,由独立电路元件实体以及L1、L2缓存构成。
- 逻辑核(LCPU):在一个物理核内,逻辑层面的核。(内部物理核通过高速运算诞生的概念)。
- 超线程(HT):超线程可以在一个逻辑核等待指令执行的间隔(等待从cache或内存中获取下一条指令),把时间片分配到另一个逻辑核。高速在这两个逻辑核之间切换,让应用程序感知不到这个间隔,误认为自己是独占了一个核。
注意啦!!这里里面的三角关系:
一个CPU可以有多个物理核。但是如果操作系统开启了超线程,一个物理核可以分成 n 个逻辑核,n为超线程的数量。(分身)
来让我们看看单核CPU的草图:
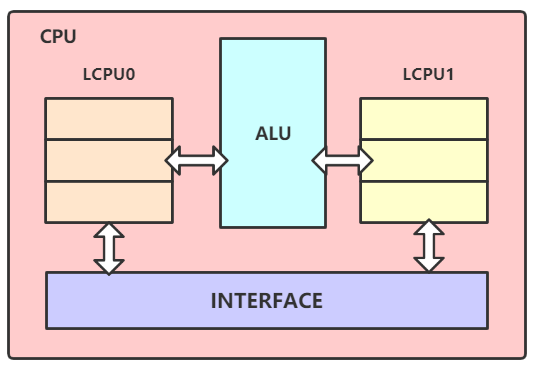
我们可以从上图看出,一个CPU核内在没有开启超线程的时候 ,内部是有两个逻辑核的,但是为什么我们不把 Redis 实例绑定在其中一个逻辑核上,而是绑定在它们的物理核上呢?把 Redis实例绑定在一个物理核上,可以让该实例的主进程、子进程、后台线程都共享这个物理核内的两个逻辑核,这样可以使这些线程和进程不必只争抢一个逻辑核,一定程度上避免的CPU竞争。(因为内部有两个供他们选择使用,不会只因为使用一个而来回切换)。
以上这些操作,都是小小的起步,如果我们还需要进一步提升Redis性能,我们需要从源码程度去解读Redis,深入研究,在必要时刻我们可以修改Redis的源码,从根源上寻找适合当前问题最佳扳手。
二哈,今天的分享就到这里啦~~,下次再见,铁子们~
如果觉得本文还不错,记得帮忙三连下,让更多的伙伴一起上车,启动我们的二哈旅行车(*^▽^*),Thanks♪(・ω・)ノ。
同时二哈最近开通了公众号呀,在这里你可以收获最新的资讯呀,千万别错过啦!
欢迎兄弟们关注关注。(虽然刚开始公众号low low 地,但是后面都会好起来的 ღゝ◡╹)ノ♡。)



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人