

多线程之Fork/Join使用
Fork/Join框架是Java7提供了的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务(每个小任务之间相互不影响),最终汇总每个小任务结果后得到大任务结果的框架。通过工作窃取的算法来降低线程的等待和竞争,和线程的利用率。
工作窃取算法
工作窃取算法:通过此算法降低线程等待和竞争。工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。
那么为什么需要使用工作窃取算法呢?
假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行(当一个工作线程中没有任务时,会从其他工作线程的队列尾部获取一个任务)。
同时要知道,Fork和Join是两种动作,Fork是拆分,Join是合并.
要想实现通过ForkJoin提高效率那应该怎么做?
1.首先通过ForkJoinPool来执行fork/join任务.这个ForkJoinPool和线程池类似
2.创建一个fork/join任务,将这个放入ForkJoinPool中
3.然后通过ForkJoinPool提交任务
常见使用场景
- 大数据计算
拓展
Java 8 stream 并行流 底层也是ForkJoin实现
new ForkJoinPool(num)
它使用了一个无限队列来保存需要执行的任务,而线程的数量则是通过构造函数传入,如果没有向构造函数中传入希望的线程数量,那么当前计算机可用的CPU数量会被设置为线程数量作为默认值。
使用:
public class ForkJoinExample {
//java8 parallStream
//针对一个数字,做计算。
private static final Integer MAX=200;
static class CalcForJoinTask extends RecursiveTask<Integer> {
private Integer startValue; //子任务的开始计算的值
private Integer endValue; //子任务结束计算的值
public CalcForJoinTask(Integer startValue, Integer endValue) {
this.startValue = startValue;
this.endValue = endValue;
}
@Override
protected Integer compute() {
//如果当前的数据区间已经小于MAX了,那么接下来的计算不需要做拆分
if(endValue-startValue<MAX){
System.out.println("开始计算:startValue:"+startValue+" ; endValue:"+endValue);
Integer totalValue=0;
for(int i=this.startValue;i<=this.endValue;i++){
totalValue+=i;
}
return totalValue;
}
CalcForJoinTask subTask=new CalcForJoinTask(startValue,(startValue+endValue)/2);
subTask.fork();
CalcForJoinTask calcForJoinTask=new CalcForJoinTask((startValue+endValue)/2+1,endValue);
calcForJoinTask.fork();
return subTask.join()+calcForJoinTask.join();
}
}
public static void main(String[] args) {
CalcForJoinTask calcForJoinTask=new CalcForJoinTask(1,10000);
ForkJoinPool pool=new ForkJoinPool();
ForkJoinTask<Integer> taskFuture=pool.submit(calcForJoinTask);
try {
Integer result=taskFuture.get();
System.out.println("result:"+result);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
https://blog.csdn.net/tyrroo/article/details/81390202
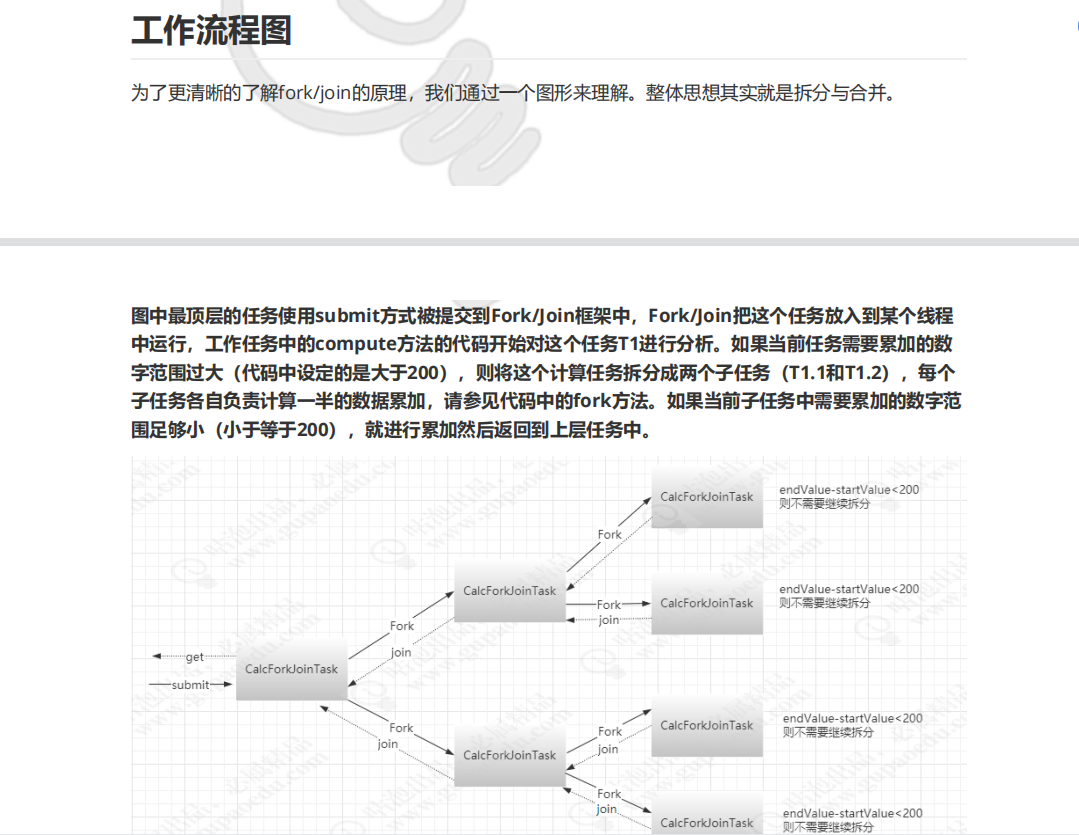

原理总结:
ForkJoinPool ForkJoin 线程池。
ForkJoinTask 要被执行拆分的任务,通过几次 继承ForkJoinTask 的子类。从写 compute 方法 进行拆分。
1. 把最顶层的任务(ForkJoinTask)使用
CalcForJoinTask calcForJoinTask=new CalcForJoinTask(1,10000);
ForkJoinPool pool=new ForkJoinPool();
ForkJoinTask<Integer> taskFuture=pool.submit(calcForJoinTask);
submit方式被提交到Fork/Join框架中pool.submit(calcForJoinTask) 。
2. 通过顶层任务的重写的compute 方法进行业务拆分,如果需要拆分就调用
fork 进行拆分 然后放到当前线程的任务执行的双向等待队列中去。
CalcForJoinTask subTask=new CalcForJoinTask(startValue,(startValue+endValue)/2);
subTask.fork();
3. 通过subTask.join() join方法Join方法的主要作用是阻塞当前线程并等待获取结果。
4. 当某一个线程下的任务都执行完了(获取当前线程的阻塞任务。从头部依次获取并执行),他会去别的线程的阻塞队列中的尾部,获取阻塞的任务进行执行(工作窃取法)。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构