

堆,栈,方法区,常量池,的概念
1.首先看堆,栈,方法区,常量池 的位置分布图

2、内存区域类型
1.寄存器:最快的存储区, 由编译器根据需求进行分配,我们在程序中无法控制;
2. 堆:存放所有new出来的对象;
3. 栈:存放基本类型的变量数据和对象的引用,但对象本身不存放在栈中,而是存放在堆(new 出来的对象)或者常量池中(对象可能在常量池里)(字符串常量对象存放在常量池中。);
4. 静态域:存放静态成员(static定义的);
5. 常量池:存放字符串常量和基本类型常量(public static final)。有时,在嵌入式系统中,常量本身会和其他部分分割离开(由于版权等其他原因),所以在这种情况下,可以选择将其放在ROM中 ;
6. 非RAM存储:硬盘等永久存储空间
三、栈中放的东西,图示:

三、堆存放示意图:
对于String类的对象特别说明一下:

五,对于string的特殊解释
(1)对于字符串:其对象的引用都是存储在栈中的,如果是编译期已经创建好(直接用双引号定义的)的就存储在常量池中,如果是运行期(new出来的)才能确定的就存储在堆中。对于equals相等的字符串,在常量池中永远只有一份,在堆中有多份。
例如:


1 String s1 = "china";
2 String s2 = "china";
3 String s3 = "china";
4 String ss1 = new String("china");
5 String ss2 = new String("china");
6 String ss3 = new String("china");
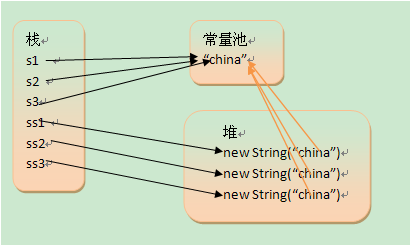
对于通过new产生一个字符串(假设为”china”)时,会先去常量池中查找是否已经有了”china”对象,如果没有则在常量池中创建一个此字符串对象,然后堆中再创建一个常量池中此”china”对象的拷贝对象。
这也就是有道面试题:String s = new String(“xyz”);产生几个对象?答:一个或两个,如果常量池中原来没有”xyz”,就是两个。
(2)对于基础类型的变量和常量:变量和引用存储在栈中,常量存储在常量池中。
例如:

1 int i1 = 9; 2 int i2 = 9; 3 int i3 = 9; 4 public static final int INT1 = 9; 5 public static final int INT2 = 9; 6 public static final int INT3 = 9;

对于成员变量和局部变量:成员变量就是方法外部,类的内部定义的变量;局部变量就是方法或语句块内部定义的变量。局部变量必须初始化。
形式参数是局部变量,局部变量的数据存在于栈内存中。栈内存中的局部变量随着方法的消失而消失。
成员变量存储在堆中的对象里面,由垃圾回收器负责回收。
下面给出一个实例:
1 class BirthDate {
2 private int day;
3 private int month;
4 private int year;
5 public BirthDate(int d, int m, int y) {
6 day = d;
7 month = m;
8 year = y;
9 }
10 省略get,set方法………
11 }
12
13 public class Test{
14 public static void main(String args[]){
15 int date = 9;
16 Test test = new Test();
17 test.change(date);
18 BirthDate d1= new BirthDate(7,7,1970);
19 }
20
21 public void change(int i){
22 i = 1234;
23 }
24 }
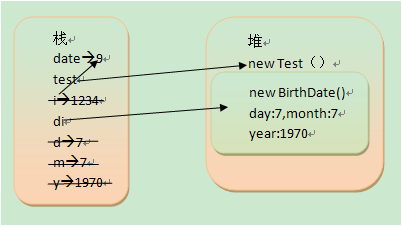
对于以上这段代码,date为局部变量,i,d,m,y都是形参为局部变量,day,month,year为成员变量。下面分析一下代码执行时候的变化:
1. main方法开始执行:int date = 9;
date局部变量,基础类型,引用和值都存在栈中。
2. Test test = new Test();
test为对象引用,存在栈中,对象(new Test())存在堆中。
3. test.change(date);
i为局部变量,引用和值存在栈中。当方法change执行完成后,i就会从栈中消失。
4. BirthDate d1= new BirthDate(7,7,1970);
d1为对象引用,存在栈中,对象(new BirthDate())存在堆中,其中d,m,y为局部变量存储在栈中,且它们的类型为基础类型,因此它们的数据也存储在栈中。day,month,year为成员变量,它们存储在堆中(new BirthDate()里面)。当BirthDate构造方法执行完之后,d,m,y将从栈中消失。
5.main方法执行完之后,date变量,test,d1引用将从栈中消失,new Test(),new BirthDate()将等待垃圾回收。
六,常量池小结
Java中的常量池,实际上分为两种形态:静态常量池和运行时常量池。
所谓静态常量池,即*.class文件中的常量池,class文件中的常量池不仅仅包含字符串(数字)字面量,还包含类、方法的信息,占用class文件绝大部分空间。
而运行时常量池,则是jvm虚拟机在完成类装载操作后,将class文件中的常量池载入到内存中,并保存在方法区中,我们常说的常量池,就是指方法区中的运行时常量池。
以下面的例子来讲解常量池:
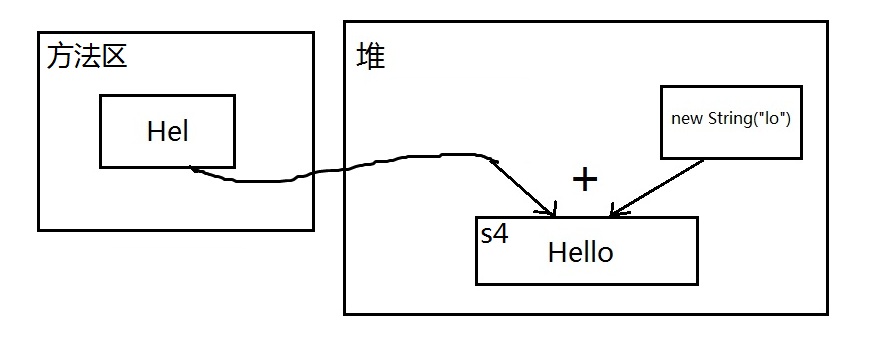
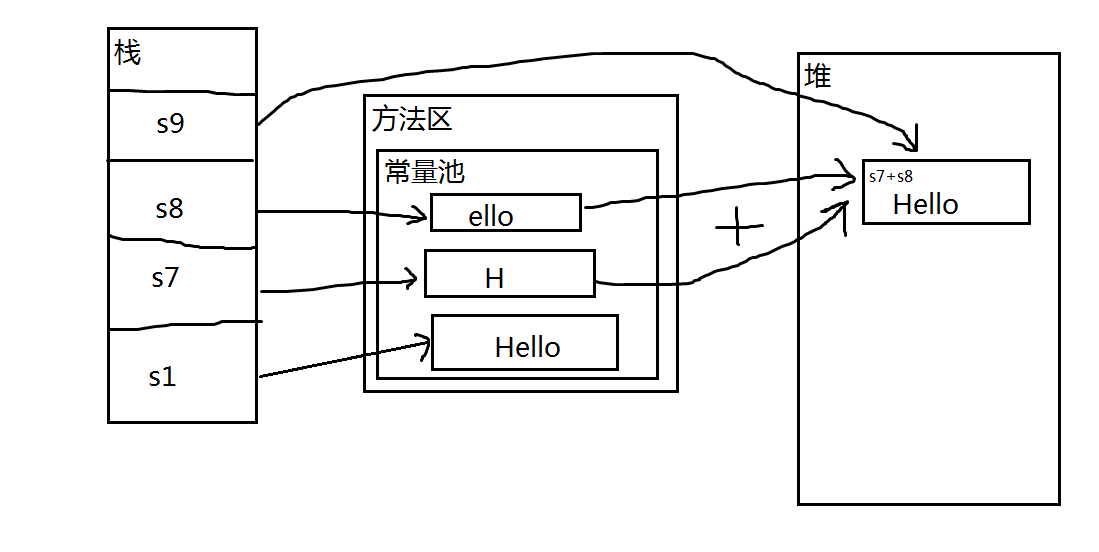
1 String s1 = "Hello";
2 String s2 = "Hello";
3 String s3 = "Hel" + "lo";
4 String s4 = "Hel" + new String("lo");
5 String s5 = new String("Hello");
6 String s6 = s5.intern();
7 String s7 = "H";
8 String s8 = "ello";
9 String s9 = s7 + s8;
10
11 System.out.println(s1 == s2); // true
12 System.out.println(s1 == s3); // true
13 System.out.println(s1 == s4); // false
14 System.out.println(s1 == s9); // false
15 System.out.println(s4 == s5); // false
16 System.out.println(s1 == s6); // true
首先说明一点,在java 中,直接使用==操作符,比较的是两个字符串的引用地址,并不是比较内容,比较内容请用String.equals()。
s1 == s2这个非常好理解,s1、s2在赋值时,均使用的字符串字面量,说白话点,就是直接把字符串写死,在编译期间,这种字面量会直接放入class文件的常量池中,从而实现复用,载入运行时常量池后,s1、s2指向的是同一个内存地址,所以相等。
s1 == s3这个地方有个坑,s3虽然是动态拼接出来的字符串,但是所有参与拼接的部分都是已知的字面量,在编译期间,这种拼接会被优化,编译器直接帮你拼好,因此String s3 = "Hel" + "lo";在class文件中被优化成String s3 = "Hello";,所以s1 == s3成立。
s1 == s4当然不相等,s4虽然也是拼接出来的,但new String("lo")这部分不是已知字面量,是一个不可预料的部分,编译器不会优化,必须等到运行时才可以确定结果,结合字符串不变定理,鬼知道s4被分配到哪去了,所以地址肯定不同。配上一张简图理清思路:
s1 == s9也不相等,道理差不多,虽然s7、s8在赋值的时候使用的字符串字面量,但是拼接成s9的时候,s7、s8作为两个变量,都是不可预料的,编译器毕竟是编译器,不可能当解释器用,所以不做优化,等到运行时,s7、s8拼接成的新字符串,在堆中地址不确定,不可能与方法区常量池中的s1地址相同。
s4 == s5已经不用解释了,绝对不相等,二者都在堆中,但地址不同。
s1 == s6这两个相等完全归功于intern方法,s5在堆中,内容为Hello ,intern方法会尝试将Hello字符串添加到常量池中,并返回其在常量池中的地址,因为常量池中已经有了Hello字符串,所以intern方法直接返回地址;而s1在编译期就已经指向常量池了,因此s1和s6指向同一地址,相等。
至此,我们可以得出三个非常重要的结论:
1、必须要关注编译期的行为,才能更好的理解常量池。
2、运行时常量池中的常量,基本来源于各个class文件中的常量池。
3、程序运行时,除非手动向常量池中添加常量(比如调用intern方法),否则jvm不会自动添加常量到常量池。
以上所讲仅涉及字符串常量池,实际上还有整型常量池、浮点型常量池等等,但都大同小异,只不过数值类型的常量池不可以手动添加常量,程序启动时常量池中的常量就已经确定了,比如整型常量池中的常量范围:-128~127,只有这个范围的数字可以用到常量池。
分类:
jvm


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?