

redis的五种数据结构原理分析
具体细节看 这个链接:https://blog.csdn.net/xpsallwell/article/details/84030285
我对于reids 5种类型的总结:
| 结构类型 | 结构存储的值 | 结构的读写能力 |
|---|---|---|
| String |
可以是字符串、整数或者浮点数。 底实现实现是SDS数据结构实现(简单动态字符串)根据字符串的长度。动态分配 |
对整个字符串或者字符串的其中一部分执行操作;对象和浮点数执行自增(increment)或者自减(decrement) |
| List(有序切可重复集合) | 一个quicklist(ZipList+LinkedList)链表,链表上的每个节点(就是一个ziplist,具备压缩列表的特性)都包含了一个字符串 | 从链表的两端推入或者弹出元素;根据偏移量对链表进行修剪(trim);读取单个或者多个元素;根据值来查找或者移除元素 |
| Set(无序 切不可重复集合) |
包含字符串的无序收集器,并且被包含的每个字符串都是独一无二的、各不相同 集合则通过使用散列表(hashtable)来保证自已存储的每个字符串都是各不相同的 |
添加、获取、移除单个元素;检查一个元素是否存在于某个集合中;计算交集、并集、差集;从集合里卖弄随机获取元素 |
| Hash(hash表) |
包含键值对的无序散列表 hash底层的数据结构实现有两种: 一种是ziplist, hash-max-ziplist-entries 512 // ziplist 元素个数超过 512 ,将改为hashtable编码 hash-max-ziplist-value 64 // 单个元素大小超过 64 byte时,将改为hashtable编码
|
添加、获取、移除单个键值对;获取所有键值对 |
zset(有序集合且不可重复结合) |
字符串成员(member)与浮点数分值(score)之间的有序映射,元素的排列顺序由分值的大小决定 ZSet 数据结构底层实现为 字典(dict) + 跳表(skiplist) ,当数据比较少时,用ziplist编码结构存储 zset-max-ziplist-entries 128 // 元素个数超过128 ,将用skiplist编码 zset-max-ziplist-value 64 // 单个元素大小超过 64 byte, 将用 skiplist编码
|
添加、获取、删除单个元素;根据分值范围(range)或者成员来获取元素 |
总结
本章介绍了redis的五种数据结构和它们使用的底层存储原理,为了达到节省内存和快速访问的目的每种数据结构可能有两种存储和访问结构,在必要的时候会由一种结构转换成另一种结构,但这个转换的过程会消耗系统性能和内存空间的,所以在使用的过程中需要注意这些配置参数,开发中尽量避免达到这些峰值,使得redis能够持续的提供高效的服务。
redis 数据类型
SDS类型(String)
这里可以看到key的类型是sds,实际上key是String类型,而Redis 是使用 C 语言实现的,但是 Redis 中使用的字符串却不是直接用的 C 语言中字符串的定义,而是自己实现了一个数据结构,叫做 SDS(simple dynamic String), 即简单动态字符串,五大类型的String也是用SDS。
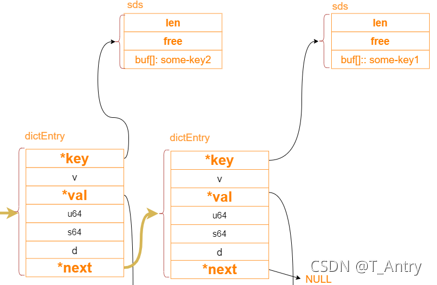
struct sdshdr{ int len; int free; char buf[]; }
len=5, 说明当前存储的字符串长度为 5。(我们不需要遍历字符串获取其长度。直接通过len 获取 时间复杂度为O1)
free=4, 4个空闲字符串长度。(可以使用free 字段实现动态扩容 )
buf 属性是一个 char 类型的数组,保存了实际的字符串信息。
可以看到 len 属性和 buf 属性的已使用部分都和第一个示例相同,但是 free 属性为 4, 同时 buf 属性的除了保存了真实的字符串内容之外,还有 5 个空的未使用空间 (’\0’结束字符不在长度中计算)

Redis 为什么要这么做呢,或者说使用 SDS 来作为字符串的具体实现结构,有什么好处呢?
C 语言的字符串定义,是使用和字符串相等长度的字符数组来存储字符串,并且在后面额外加一个字符来存储空字符’\0’
高性能获取字符串长度
从 C 语言字符串的结构图中,我们可以看到,如果我们想获取一个字符串的长度,那么唯一的办法就是遍历整个字符串。遍历操作需要 O(N) 的时间复杂度。
而 SDS 记录了字符串的长度,也就是 len属性,我们只需要直接访问该属性,就可以拿到当前 SDS 的长度。访问属性操作的时间复杂度是 O(1).
Redis 字符串数据结构的 求长度的命令 STRLEN. 内部即应用了这一特性。无论你的 string 中存储了多长的字符串,当你想求出它的长度时,可以随意的执行 STRLEN, 而不用担心对 Redis 服务器的性能造成压力。
减少修改字符串产生的内存分配次数,提高修改字符串性能 实现动态扩容。
sds 对于动态扩容也是string 无法比拟的,如sds的结构让sds可以预分配内存,甚至在原有长度类型不变的基础上,可以在原来内存使用基础上。实现动态扩容。
那么这样的好处又是啥了,如果一个string 非常长的情况下,如果要在原来的String基础上做append 操作,那么需要把内容复制到新的地址上面,
而这件事情是一件非常耗费性能的一件事,而sds正好解决这件事,尤其在将网络io数据转化为具体命令操作的时候,要经常对字符串做append操作。所以sds结构非常适合redis。
SDS 在进行修改之后,会对接下来可能需要的空间进行预分配。这也就是 free 属性存在的意义,记录当前预分配了多少空间。
分配策略:
如果当前 SDS 的长度小于 1M, 那么分配等于已占用空间的未使用空间,即让 free 等于 len.
如果当前 SDS 的长度大于 1M, 那么分配 1M 的 free 空间。
在 SDS 修改时,会先查看 free属性的值,来确定是否需要进行空间扩展,如果不需要就直接进行拼接了。
通过预分配策略,SDS 连续增长 N 次,所需要的内存分配次数从绝对 N 次,变成了最多 N 次。
惰性释放内存
当 SDS 进行了缩短操作,那么多余的空间不着急进行释放,暂时留着以备下次进行增长时使用。
听起来预分配和惰性释放本质上也是使用空间换取时间的操作,SDS 也提供了对应的 API, 在需要的时候,会自己释放掉多余的未使用空间。
zipList
压缩列表是Redis为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构。
一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值。元素之间紧挨着存储,没有任何冗余空隙。这就有点拿时间换空间的意思。
跳表 skip list
Skip list是一个分层结构多级链表,最下层是原始的链表,每个层级都是下一个层级的“高速跑道”。
跳跃表(SkipList)是一种可以替代平衡树的数据结构。跳跃表让已排序的数据分布在多层次的链表结构中,默认是将Key值升序排列的,以 0-1 的随机值决定一个数据是否能够攀升到高层次的链表中。它通过容许一定的数据冗余,达到 “以空间换时间” 的目的。
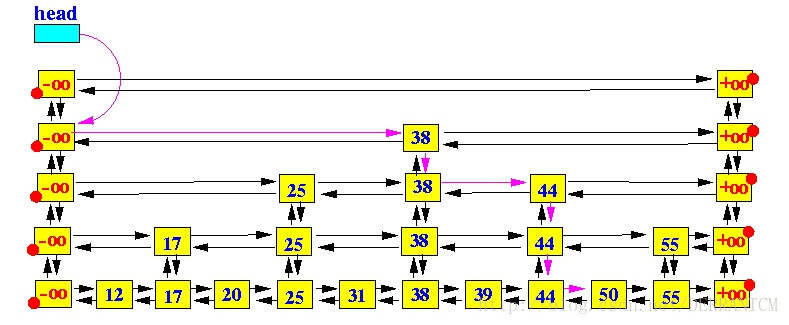
上面这张图就是一个跳跃表的实例,先说一下跳跃表的构造特征:
-
一个跳跃表应该有若干个层(Level)链表组成;
-
跳跃表中最底层的链表包含所有数据; 每一层链表中的数据都是有序的;
-
如果一个元素X出现在第i层,那么编号比 i 小的层都包含元素X;
-
第 i 层的元素通过一个指针指向下一层拥有相同值的元素;
-
在每一层中,-∞ 和 +∞两个元素都出现(分别表示INT_MIN 和 INT_MAX);
-
头指针(head)指向最高一层的第一个元素;
上面的图示使用紫色的箭头画出了在一个SkipList中查找key值50的过程。简述如下:
-
从head出发,因为head指向最顶层(top level)链表的开始节点,相当于从顶层开始查找;
-
移动到当前节点的右指针(right)指向的节点,直到右节点的key值大于要查找的key值时停止;
-
如果还有更低层次的链表,则移动到当前节点的下一层节点(down),如果已经处于最底层,则退出;
-
重复第2步 和 第3步,直到查找到key值所在的节点,或者不存在而退出查找;
dict,又称字典(dictionary)或映射(map),是集合的一种;这种集合中每个元素都是KV键值对。字典dict在各编程语言中都有体现,面向对象的编程语言如C++、Java中都称其为Map。
五种类型的应用场景
String,redis对于KV的操作效率很高,可以直接用作计数器。例如,统计在线人数等等,另外string类型是二进制存储安全的,所以也可以使用它来存储图片,甚至是视频等。
hash,存放键值对,一般可以用来存某个对象的基本属性信息,例如,用户信息,商品信息等,另外,由于hash的大小在小于配置的大小的时候使用的是ziplist结构,比较节约内存,所以针对大量的数据存储可以考虑使用hash来分段存储来达到压缩数据量,节约内存的目的,例如,对于大批量的商品对应的图片地址名称。比如:商品编码固定是10位,可以选取前7位做为hash的key,后三位作为field,图片地址作为value。这样每个hash表都不超过999个,只要把redis.conf中的hash-max-ziplist-entries改为1024,即可。
list,列表类型,可以用于实现消息队列,也可以使用它提供的range命令,做分页查询功能。 quicklist +zipList
set,集合,整数的有序列表可以直接使用set。可以用作某些去重功能,例如用户名不能重复等,另外,还可以对集合进行交集,并集操作,来查找某些元素的共同点
sortedzset,有序集合,可以使用范围查找,排行榜功能或者topN功能。
Redis的String数据结构 (推荐使用StringRedisTemplate)
//set一个值
set void set(K key, V value);
//set一个值,并设置其失效时间,最后一个参数是时间的单位可以是天,时,分,秒
set void set(K key, V value, long timeout, TimeUnit unit);
//该方法是用 value 参数覆写(overwrite)给定 key 所储存的字符串值,从偏移量 offset 开始 (就是在值的某个位子插入值的意思)
set void set(K key, V value, long offset);
//截取key所对应的value字符串get(0,-1) 获取该key下的完整value
get String get(K key, long start, long end);
//设置递增detla=》递增的值
increment Long increment(K key, long delta);
支持整数
Redis的List数据结构
#0开始位置,-1结束位置,结束位置为-1时,表示列表的最后一个位置,即查看所有。lrangemylist0-1
lpush mylist 1 lpush mylist 2 lpush mylist 3 4 5
#1 rpop mylist
//从右边插入
redisTemplate.opsForList().rightPush("oowwoo", "aaa")
redisTemplate.opsForList().rightPushAll("oowwoo", "插入一个数组")
//右边插入
template.opsForList().leftPush("listarray","bbb");
template.opsForList().leftPushAll("listarray","插入一个集合");
//把value值放到key对应列表中pivot值的右面,如果pivot值存在的话
Long rightPush(K key, V pivot, V value);
//在列表中index的位置设置value值
void set(K key, long index, V value);
Redis的Hash数据机构
这是一个类似map的结构,这个一般可以将结构化的数据,比如一个对象(前提这个对象没有嵌套其他对象)给缓存到redis,然后读写缓存的时候就可以hash 中的某个字段了。
初始数据:
//template.opsForHash().put("redisHash","name","tom");
//template.opsForHash().put("redisHash","age",26);
//template.opsForHash().put("redisHash","class","6");
//Map<String,Object> testMap = new HashMap();
//testMap.put("name","jack");
//testMap.put("age",27);
//testMap.put("class","1");
//template.opsForHash().putAll("redisHash1",testMap);
//HV get(H key, Object hashKey);
//获取值
使用:System.out.println(template.opsForHash().get("redisHash","age"));
结果:26
List<HV> multiGet(H key, Collection<HK> hashKeys);
//根据这个集合对应的key 统一去获取值
使用:List<Object> kes = new ArrayList<Object>();
kes.add("name");
kes.add("age");
System.out.println(template.opsForHash().multiGet("redisHash",kes));
结果:[jack, 28.1]
Redis的Set数据结构

#-------操作一个set-------#添加元素 sadd mySet 1 #查看全部元素 smembers mySet #判断是否包含某个值 sismember mySet 3 #删除某个/些元素 srem mySet 1 srem mySet 2 4 #查看元素个数 scard mySet
#随机删除一个元素
spop mySet
#-------操作多个set-------
#将一个set的元素移动到另外一个set
smove yourSet mySet 2
#求两set的交集
sinter yourSet mySet
#求两set的并集
sunion yourSet mySet
#求在yourSet中而不在mySet中的元素
sdiff yourSet mySet
Redis的sortedzset数据结构
Redis 有序集合和无序集合一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
public interface ZSetOperations<K,V>
ZSetOperations提供了一系列方法对有序集合进行操作:
Boolean add(K key, V value, double score);
新增一个有序集合,存在的话为false,不存在的话为true
使用:System.out.println(template.opsForZSet().add("zset1","zset-1",1.0));
结果:true
Long add(K key, Set<TypedTuple<V>> tuples);
新增一个有序集合
使用:ZSetOperations.TypedTuple<Object> objectTypedTuple1 = new DefaultTypedTuple<Object>("zset-5",9.6);
ZSetOperations.TypedTuple<Object> objectTypedTuple2 = new DefaultTypedTuple<Object>("zset-6",9.9);
Set<ZSetOperations.TypedTuple<Object>> tuples = new HashSet<ZSetOperations.TypedTuple<Object>>();
tuples.add(objectTypedTuple1);
tuples.add(objectTypedTuple2);
System.out.println(template.opsForZSet().add("zset1",tuples));
System.out.println(template.opsForZSet().range("zset1",0,-1));
结果:[zset-1, zset-2, zset-3, zset-4, zset-5, zset-6]


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构