pandas 操作csv文件
一、读csv文件
import pandas as pd read_df = pd.read_csv('./a.csv') # 结果为DataFrame结构
下面来看常用参数:
1.filepath_or_buffer:(这是唯一一个必须有的参数,其它都是按需求选用的)
文件所在处的路径
2.sep:
指定分隔符,默认为逗号','
3.delimiter : str, default None
定界符,备选分隔符(如果指定该参数,则sep参数失效)
4.header:int or list of ints, default ‘infer’
指定哪一行作为表头。默认设置为0(即第一行作为表头),如果没有表头的话,要修改参数,设置header=None
5.names:
指定列的名称,用列表表示。一般我们没有表头,即header=None时,这个用来添加列名就很有用啦!
6.index_col:
指定哪一列数据作为行索引,可以是一列,也可以多列。多列的话,会看到一个分层索引
7.prefix:
给列名添加前缀。如prefix="x",会出来"x1"、"x2"、"x3"酱纸
8.nrows : int, default None
需要读取的行数(从文件头开始算起)
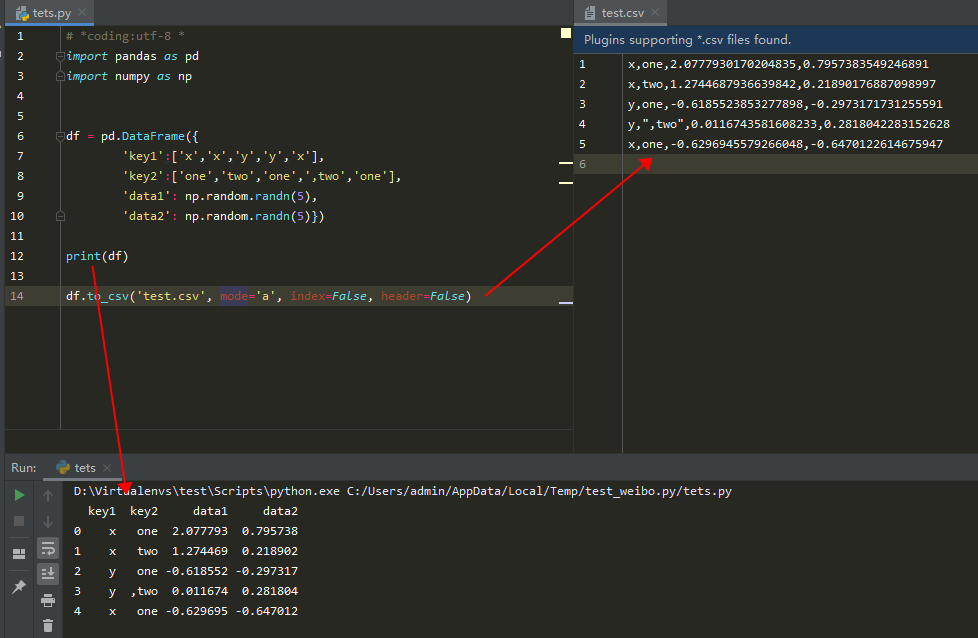
二、写入csv文件
import pandas as pd BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) data = {'index': ['index'], 'words': ['words'], 'num': ['num']} df = pd.DataFrame(data) df.to_csv(f'{BASE_DIR}/words_csv.csv', mode='a', index=False, header=False)
to_csv(path_or_buf,sep,na_rep,columns,header,index)
参数解析:
1.path_or_buf:字符串,放文件名、相对路径、文件流等;
2.sep:字符串,分隔符,跟read_csv()的一个意思
3.na_rep:字符串,将NaN转换为特定值
4.columns:列表,指定哪些列写进去
5.header:默认header=0,如果没有表头,设置header=None,表示我没有表头呀!
6.index:关于索引的,默认True,写入索引