

综合设计——多源异构数据采集与融合应用综合实践
综合设计——多源异构数据采集与融合应用综合实践
| 这个项目属于哪个课程 | 2024数据采集与融合技术实践 |
|---|---|
| 组名 | 数据"融合炖" 异构 "大杂绘"队 |
| 项目简介 | 项目名称:味谱魔方 项目logo: 项目介绍: 项目介绍:智能购物菜谱助手是一款结合AI技术的智能化应用,旨在为用户提供从食材购买到菜肴烹饪的一站式服务。通过该平台,用户不仅可以完成食材的在线选购,还能根据选购的食材生成个性化菜谱。 |
| 团队成员学号 | 102202156 王贺雯 102202156 高涛 102202157 王党兵 102202119 吴佳辉 032004126 曾祥宝 |
| 项目目标 | 本系统旨在实现用户将食品加入购物车,生成对应的食谱核心功能 |
| 其他参考文献 | https://www.spkx.net.cn/CN/abstract/abstract58653.shtml |
| gitee链接 | https://gitee.com/jyppx000/data-collection-and-fusion |
一、项目系统总体技术概述
1.系统架构概述
系统分为后端管理系统、安卓、模型训练及其搭建、爬取数据、调用模型算法接口,部署等多层。
后端管理系统:管理员对安卓端的商家、客户进行管理。
安卓:
- 用户可以在安卓手机端浏览生鲜品类
- 商家可以在安卓手机端发布商品
模型训练及搭建
- 使用开源模型——ChatGLM-6B
爬取数据:核心涉及到js逆向
2.各模块技术实现
2.1 一键生成菜谱功能
目标:根据用户购物车中的食材信息,通过自己部署的 ChatGLM-6B 模型生成个性化的菜谱并展示给用户。
技术方案:
- 前端技术(安卓):
- 编程语言:使用 Java 进行安卓应用开发。
- UI 设计:采用 XML 布局来设计用户界面。
- 弹框显示:使用 AlertDialog 弹框来展示生成菜谱的过程,以增强用户体验。
- 接口请求:前端通过 RESTful API 向后端发送请求,传递购物车中的食材数据,并等待生成的菜谱内容。
- 后端技术:
- 编程语言:后端使用Java和 Spring Boot 构建 RESTful API。
- 与 ChatGLM-6B 模型集成
- API 接口:后端通过 HTTP 请求将食材数据传递给部署的 ChatGLM-6B 模型,模型返回生成的菜谱内容。
- MySQL 数据存储:使用 MySQL 数据库存储用户数据,以及菜品,名称,价格等。
流程:
- 用户选择食材:用户在安卓应用中选择食材并添加到购物车。
- 生成推荐食谱:前端通过 RESTful API 向后端发送请求,传递购物车中的食材数据。
- 后端请求 ChatGLM-6B 模型:后端接收食材数据后,将其通过 HTTP 请求传递给部署的 ChatGLM-6B 模型接口。使用 HttpURLConnection 发起 HTTP 请求。
- ChatGLM-6B 模型生成菜谱:模型根据传入的食材数据,生成详细的食谱内容(包括菜名、食材等)。
- 返回生成的食谱:后端收到模型返回的菜谱数据后,将其以 JSON 格式 返回给前端。
- 展示菜谱:前端接收到菜谱数据后,展示生成的菜谱内容,弹窗显示展示详细信息。
2.2 ChatGLM-6B 模型集成
目标:生成个性化的菜谱。
技术方案:
- 后端与模型通信
- ChatGLM-6B 模型暴露 API 接口供后端调用。
- 使用 JSON 格式在前后端和模型之间传递数据,保证数据结构一致性。
- 模型训练与调优
- 使用爬取的食谱数据,对 ChatGLM-6B 进行了微调训练
- 集成方式
- 后端调用 API:后端通过 Java 代码发送 HTTP 请求,将用户购物车数据传给模型。
- 模型生成菜谱:模型处理请求并生成菜谱后,返回包含菜谱内容的 JSON 数据,后端将该数据转发给前端展示。
流程:
- 生成请求:后端将用户的购物车数据转换为模型所需的输入格式(如食材名称、数量、价格等)。
- 调用模型接口:后端发起 HTTP 请求,传递数据到 ChatGLM-6B 模型接口,模型根据输入生成菜谱。
- 返回生成结果:模型返回的菜谱信息包含菜名、食材、步骤等内容,后端将这些数据包装为 JSON 格式 并传递给前端。
- 前端展示菜谱:前端接收到菜谱数据后,展示在界面中。
2.3 异步处理与生成过程
目标:保证菜谱生成过程不阻塞主线程,提升用户体验。
技术方案:
- 前端异步请求
- 使用 Coroutines处理后台请求,确保 UI 线程不被阻塞。
- 使用 OkHttp 发起网络请求,结合协程来处理请求,避免 UI 界面卡顿。
- 后端异步处理
- 后端通过 Spring Boot 提供的 @Async 注解实现异步调用,避免请求阻塞。
流程:
- 异步请求:前端触发请求后,后台执行异步任务生成菜谱。
- 后台生成:后端异步调用 ChatGLM-6B 模型进行菜谱生成。
- 结果返回:生成完毕后,后端将菜谱数据通过回调或轮询返回前端,前端更新界面。
二、小组分工———数据爬取
我是王党兵,学号102202157,作为项目组成员之一,我主要负责项目的数据爬取部分(爬取惠农网相关数据)
1.功能概述
负责从特定网站(https://www.cnhnb.com 相关页面)爬取农产品相关数据3000余条,涵盖水果、蔬菜、水产、畜牧养殖这几大分类。对于爬取到的数据,不仅进行文本信息的提取与保存(如商品名称、价格、厂家名称等),还会下载对应的商品图片,并能够按照分类分别存储在相应的文件夹结构中,同时保存为txt文本,可选择是否将数据保存为 CSV 格式文件,整体为后续《味谱魔方》应用提供基础的数据支撑。
2.核心流程
2.1初始化
通过类 HuiNong 的构造函数__init__初始化一些关键属性,比如是否保存CSV文件的标志csv_flag、每个类别当前的爬取数量记录count以及每个类别设定的总爬取数量total_count。
2.2请求网页源码获取
提供了两种获取网页源码的方式,一种是通过常规的 requests 库发送 GET 请求获取(get_html 方法),适用于大部分分类的页面爬取;另一种是利用 DrissionPage 库(dp_get_html 方法),针对畜牧养殖类别这种可能有特殊页面交互需求的情况进行源码获取,且在获取过程中还处理了页面异常(如页面不存在或出现异常时的重新爬取逻辑)以及翻页操作等。
2.3数据解析与存储
使用parse_html方法解析网页源码。通过xpath定位到具体的商品元素,并提取如商品图片链接、名称、价格、厂家名称等关键信息,整理到字典 item 中。之后调用save_data方法将数据按照分类存储到本地文件系统中,包括创建对应的文件夹(农产品主文件夹、各分类子文件夹以及图片子文件夹等),保存图片、将文本数据写入TXT文件,同时根据csv_flag判断是否将数据写入CSV文件。
2.4整体爬取流程控制
在main方法中,定义了要爬取的分类列表type_lst和对应的初始URL列表url_lst,然后通过循环遍历分类与URL,针对畜牧养殖类别使用 dp_get_html方法爬取,其他类别则通过拼接页码到URL实现分页爬取,在每次分页爬取时,依次调用get_html获取源码、parse_html解析数据,并进行相应的翻页和等待操作,保证数据的完整爬取。
2.5运用到的技术
| 核心技术分类 | 具体技术 | 作用说明 |
|---|---|---|
| 网络请求技术 | requests库 |
发送GET请求获取网页源码,可设置请求头模拟浏览器行为,绕过部分反爬虫机制,为后续数据解析提供原始数据 |
| 页面解析技术 | lxml库结合xpath |
将网页源码解析为etree对象后,利用xpath语法精准定位网页元素并提取如商品图片链接、名称等关键信息 |
| 自动化浏览器操作技术 | DrissionPage库(基于Chromium) |
模拟真实浏览器操作,像打开URL、点击页面元素(如翻页按钮)、获取页面加载后的源码以及处理页面异常情况,用于有复杂页面交互需求的爬取场景 |
| 数据处理与存储技术 | 文件与文件夹操作(os模块) |
判断文件夹是否存在,创建新的文件夹,构建本地合理的文件存储结构,方便按分类存储数据 |
| 数据处理与存储技术 | 字符串处理(re模块) |
利用正则表达式处理字符串,例如替换文件名中不合法的特殊字符,确保文件保存正常 |
| 数据处理与存储技术 | 数据格式存储(csv模块) |
将字典形式的数据按要求保存为CSV格式文件,先写表头再逐行写入数据,便于后续数据读取和处理 |
3.相关核心代码及爬取数据截图
1. 主要代码
3.1常规方式获取网页源码(requests 库)
点击查看代码
def get_html(self, url):
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'cache-control': 'no-cache',
'pragma': 'no-cache',
'priority': 'u=0, i',
'sec-ch-ua': '"Chromium";v="130", "Google Chrome";v="130", "Not?A_Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36'
}
response = requests.request("GET", url, headers=headers)
return response.text def get_html(self, url):
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'cache-control': 'no-cache',
'pragma': 'no-cache',
'priority': 'u=0, i',
'sec-ch-ua': '"Chromium";v="130", "Google Chrome";v="130", "Not?A_Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36'
}
response = requests.request("GET", url, headers=headers)
return response.text def get_html(self, url):
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'cache-control': 'no-cache',
'pragma': 'no-cache',
'priority': 'u=0, i',
'sec-ch-ua': '"Chromium";v="130", "Google Chrome";v="130", "Not?A_Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36'
}
response = requests.request("GET", url, headers=headers)
return response.text
3.2通过 DrissionPage 库获取网页源码(针对畜牧养殖类别等特殊情况)
点击查看代码
def dp_get_html(self, url, _type):
tab = Chromium().latest_tab
tab.get(url)
html = tab.html
if '您访问的页面不存在或出现异常' in html:
page = int(self.count / 20) + 2
print(f'{_type}从{page}重新爬取')
while self.count <= self.total_count:
self.parse_html(html, _type)
time.sleep(3)
next_ele = tab.ele('.btn-next')
next_ele.click()
tab.wait.load_start()
html = tab.html
if '您访问的页面不存在或出现异常' in html:
page = int(self.count / 20) + 2
print(f'{_type}从{page}重新爬取')
3.3数据分析部分
点击查看代码
def parse_html(self, html_str, _type):
while '您访问的页面不存在或出现异常' in html_str:
print(self.count)
html = etree.HTML(html_str)
div_lst = html.xpath('//*[@class="supply-item"]')
for div in div_lst:
item = {}
img_src = div.xpath('.//*[@class="shop-image"]/img/@src')[0].strip()
title = div.xpath('.//*[@class="shop-image"]/img/@title')[0].strip().replace('\n', '').replace('\t', '')
new_title = self.replace_special_characters(title)
price_lst = div.xpath('.//*[@class="shops-price-bg"]/*[@class="shops-price"]//text()')
price = ''.join([p.strip() for p in price_lst])
shop = div.xpath('.//*[@class="shop-btm"]//a[@class="l-shop-btm"]/text()')[0].strip()
item['title'] = new_title
item['type'] = _type
item['price'] = price
item['shop'] = shop
print(item)
self.save_data(item, _type, img_src)
3.4数据保存部分
点击查看代码
def save_data(self, data, _type, img_src):
file_name = '农产品'
if not os.path.exists(file_name):
os.mkdir(file_name)
file_path = os.path.join(file_name, _type)
self.mkdir_files(file_path)
img_path = os.path.join(file_path, '图片')
self.mkdir_files(img_path)
title = data.get('title')
img_file = os.path.join(img_path, f'{self.count}_{title}.jpg')
try:
urlretrieve(img_src, img_file)
except:
return
txt_file = os.path.join(file_path, f'{_type}.txt')
csv_file = os.path.join(file_path, f'{_type}.csv')
head = ['shop', 'type', 'price', 'title']
if not os.path.exists(txt_file):
with open(txt_file, 'w', encoding='utf-8-sig') as f:
f.write(', '.join(head) + '\n')
with open(txt_file, 'a', encoding='utf-8-sig') as f:
f.write(', '.join([data.get('shop'), _type, data.get('price'), title]) + '\n')
if self.csv_flag:
if not os.path.exists(csv_file):
with open(csv_file, 'w', encoding='utf-8-sig', newline='') as f:
csv_writer = csv.DictWriter(f, fieldnames=head)
csv_writer.writeheader()
with open(csv_file, 'a', encoding='utf-8-sig', newline='') as f:
csv_writer = csv.DictWriter(f, fieldnames=head)
csv_writer.writerow(data)
self.count += 1
3.5整体爬取流程控制(main 方法)
点击查看代码
def main(self):
type_lst = ['水果', '蔬菜', '水产', '畜牧养殖']
url_lst = [
'https://www.cnhnb.com/p/sgzw',
'https://www.cnhnb.com/p/sczw',
'https://www.cnhnb.com/p/shuic',
'https://www.cnhnb.com/supply/search/?k=%E7%95%9C%E7%89%A7%E5%85%BB%E6%AE%96',
]
for _type, url in zip(type_lst, url_lst):
self.count = 1
page = 1
if _type == '畜牧养殖':
self.dp_get_html(url, _type)
else:
while self.count <= self.total_count:
new_url = url + r"-0-0-0-0-" + str(page)
print(f'正在爬取{new_url})
html_str = self.get_html(new_url)
self.parse_html(html_str, _type)
time.sleep(3)
page += 1
2.爬取数据截图
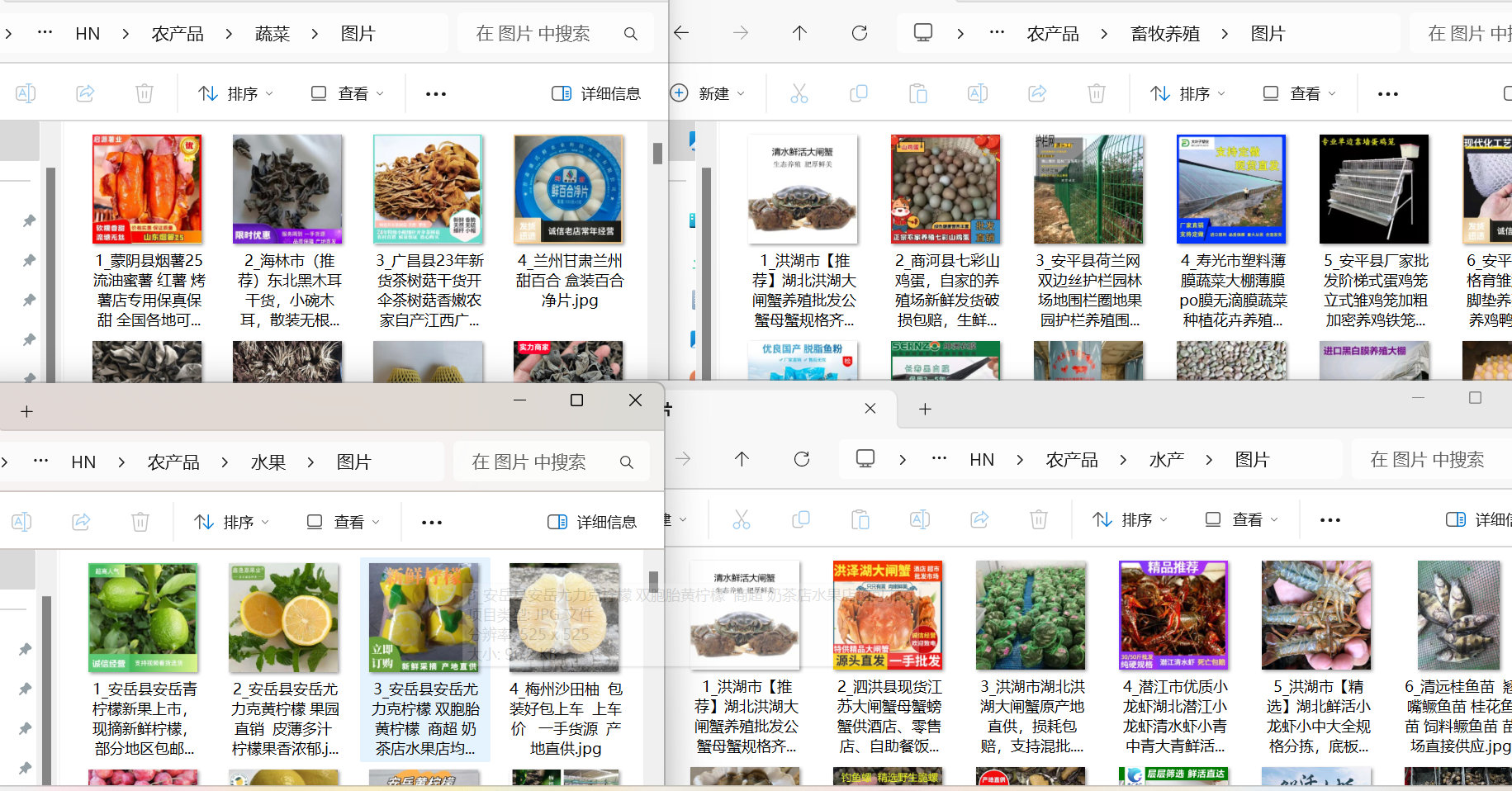
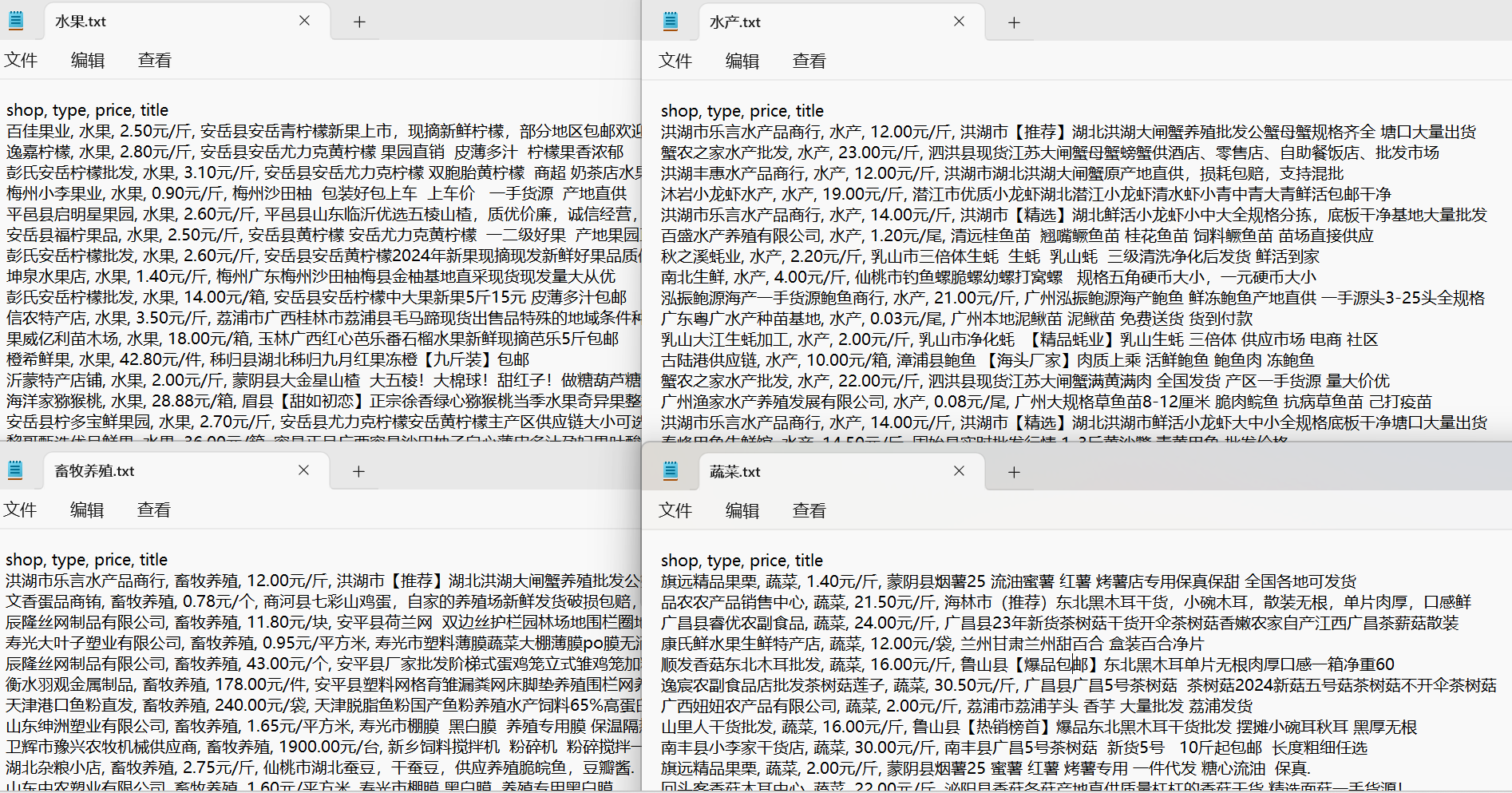
4.总结
在《味谱魔方》项目中,我主要负责数据爬取工作,这是一段充满挑战与收获的经历。
我运用requests和DrissionPage库,针对目标网站的农产品数据进行抓取,通过细致分析网页结构,结合xpath与lxml库精确提取商品信息,包括图片、名称、价格和厂家等。在数据存储方面,利用os模块构建合理的文件夹体系,借助re模块规范文件名,还根据需求用csv模块以及TXT文本保存数据。在此过程中,我遇到了网站反爬虫机制和复杂页面交互等问题,通过不断钻研和尝试,成功解决并优化了爬取流程。这不仅提升了我的技术水平,还锻炼了问题解决能力和应变能力。同时,与团队成员的紧密沟通协作,使我更深入理解项目整体需求,确保数据能有效服务于后续的智能食谱推荐功能开发,为项目的推进贡献了自己的一份力量,也让自己在专业领域获得了成长。

