经典神经网络对比
| LeNet-5(1998) | AlexNet(2012) | VGGNet(2014) | GoogLeNet(2014) | ResNet(2015) | DenseNet(2017) | |
| 输入层 | 32*32*1 | 224*224*3 | 224*224*3 | 224*224*3 | 224*224*3 | |
| 卷积层 | 3 | 5 | 13 | |||
| 卷积核 | 5*5 | 11*11,5*5,3*3 | 3*3,1*1 | 5*5,3*3,1*1 | 7*7,3*3,1*1 | 3*3,1*1 |
| 池化层 | 2 | 3 | 5 | |||
| 池化核 | 2*2 | 3*3 | 2*2 | 3*3;全局平均池化:7*7 | 3*3 | 2*2 |
| 全连接层 | 2 | 3 | 3 | |||
| 输出层 | 10(0-9每个数字的概率) | 1000(ImageNet图像分类) | 1000(ImageNet图像分类) | 1000(ImageNet图像分类) | 1000(ImageNet图像分类) | |
| 网络层次 | 5 | 8 | 16 or 19 | 22 | 152 | 121 |
| 结构 | 3卷积(2池化)+2全连接 | 5卷积(3池化)+3全连接 | 5卷积组(5池化)+2全连接图像特征+1全连接分类特征 | 2单独卷积层(2池化)+9inception结构+1全局平均池化+1全连接(softmax) | “瓶颈残差模块”:依次由1*1,3*3,1*1三个卷积层堆积而成,提高计算效率 |
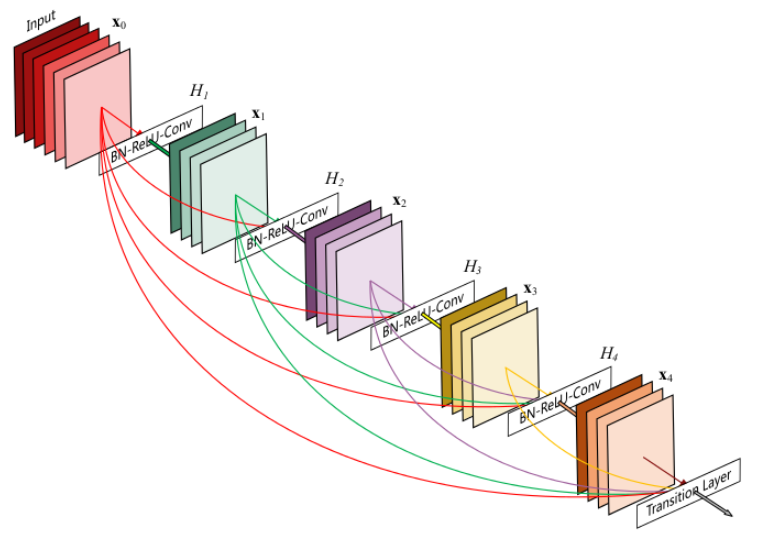
dense block:BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3); 每个DenseBlock的之间层由BN−>Conv(1×1)−>averagePooling(2×2)组成 |
| 特点 |
CNN开山之作,定义了CNN 的基本组件,确立了其基本 架构 |
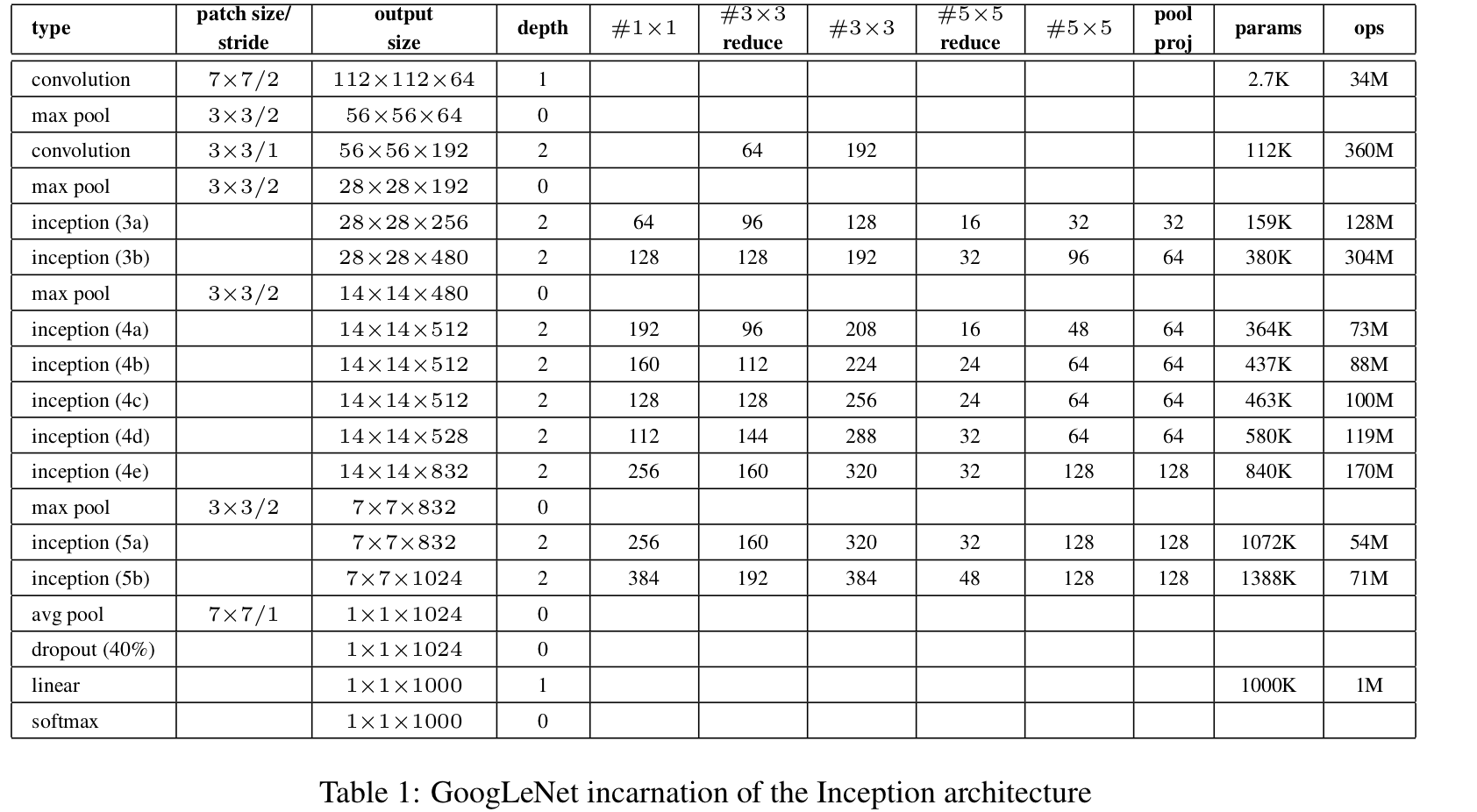
原始图片为256*256,使用了数据增广随机剪裁为224*224;拥有更深的网络,使用多CPU训练,RELU,dropout,LRN,局部响应归一化 | 采用了Pre-training的方式(先训练一部分网络,确保这部分网络稳定后,再在这基础上逐渐加深;卷积层使用了更小的filter尺寸和间隔,增加了非线性表达能力,减少了参数量 | 引入Inception结构代替单纯的卷积+激活传统操作,中间层增加辅助LOSS单元(目的是计算损失时让低层的特征也有很好的区分能力),帮助网络收敛,最后的全连接层全部替换为全局平均池化,减少参数,精度更高,训练更快 |
层数非常深; |
密集连接,缓解了梯度消失的问题,加强特征传播,鼓励特征复用,极大地减少了参数量,减少了计算量;缺点:内存占用非常高 |
| 结构图 | 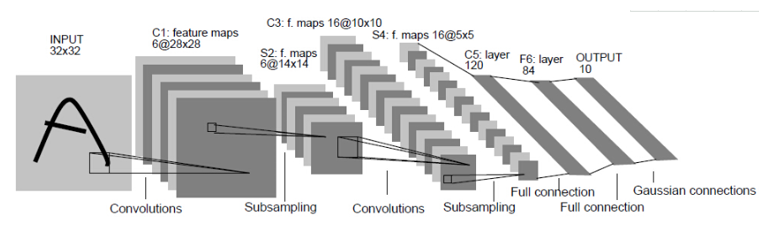 |
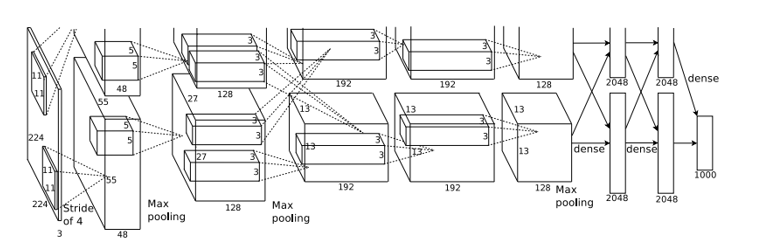 |
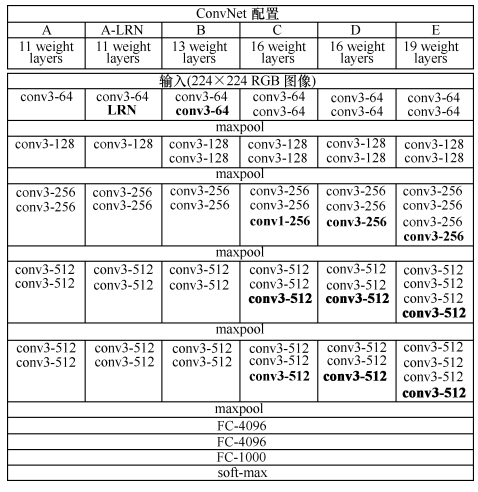 |
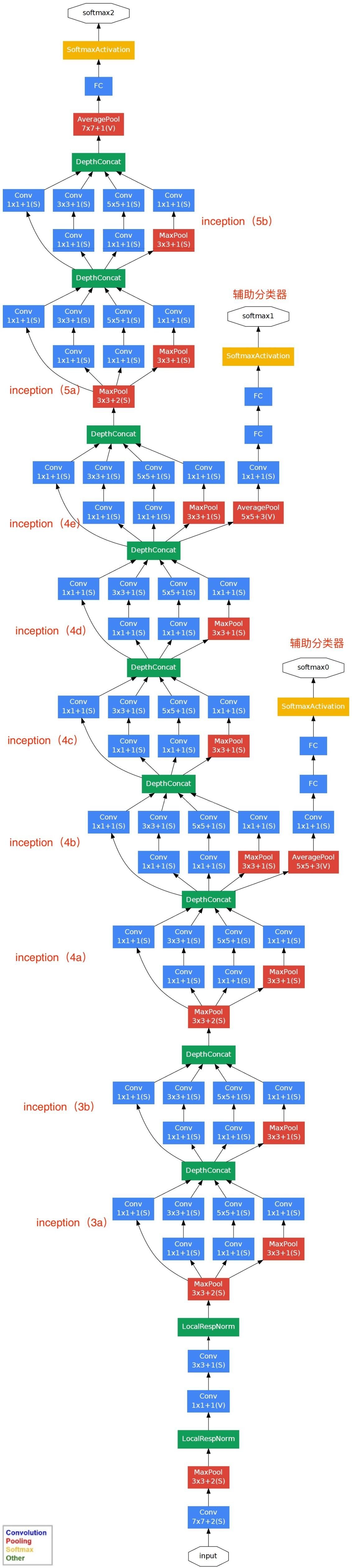 |
 |
 |
 |
 |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号