『深度应用』NLP机器翻译深度学习实战课程·零(基础概念)
0.前言
深度学习用的有一年多了,最近开始NLP自然处理方面的研发。刚好趁着这个机会写一系列NLP机器翻译深度学习实战课程。
本系列课程将从原理讲解与数据处理深入到如何动手实践与应用部署,将包括以下内容:(更新ing)
- NLP机器翻译深度学习实战课程·零(基础概念)
- NLP机器翻译深度学习实战课程·壹(RNN base)
- NLP机器翻译深度学习实战课程·贰(RNN+Attention base)
- NLP机器翻译深度学习实战课程·叁(CNN base)
- NLP机器翻译深度学习实战课程·肆(Self-Attention base)
- NLP机器翻译深度学习实战课程·伍(应用部署)
本系列教程参考博客:https://me.csdn.net/chinatelecom08
1.NLP机器翻译发展现状
1.1 机器翻译现状
什么是机器翻译?
说白了就是通过计算机将一种语言转化成其他语言,就是机器翻译。
这对我们同学们而言都很熟悉了,那么机器翻译背后的理论支持到底是什么呢?而且几十年前的机器翻译和现在我们天天口中说的神经网络到底有什么区别呢?
首先我们从机器翻译历史发展的角度来对它进行大致的讲述一下,机器翻译的历史大致经历了三个阶段:
- 基于规则的机器翻译(70年代)
- 基于统计的机器翻译(1990年)
- 基于神经网络的机器翻译(2014年)
基于规则的机器翻译的想法第一次出现是在70年代。科学家根据对翻译者工作的观察,试图驱使计算机同样进行翻译行为。这些翻译系统的组成部分包括:
双语词典(俄语->英文)
针对每种语言制定一套语言规则(例如,名词以特定的后缀-heit、-keit、-ung等结尾)
如此而已。如果有必要,系统还可以补充各种技巧性的规则,如名字、拼写纠正、以及音译词等。
感兴趣的同学可以去网上仔细查看一下相关的资料,这里就贴上一个大致的流程图,来表示基于规则的机器翻译的实现流程。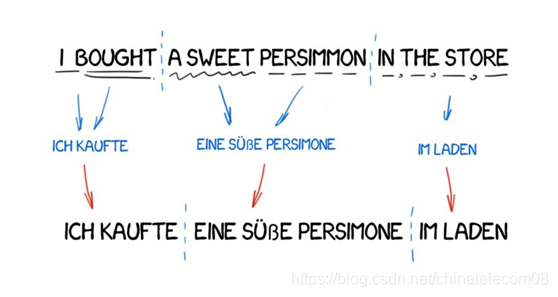
![]()
根据规则调整句子结构,然后去字典中查找对应的词片段的意思,重新组成新的句子,最后利用一些方法来对生成的句子进行语法调整。
在1990年早期,IBM研究中心的一台机器翻译系统首次问世。它并不了解整体的规则和语言学,而是分析两种语言中的相似文本,并试图理解其中的模式。
统计模型的思路是把翻译当成机率问题。原则上是需要利用平行语料,然后逐字进行统计。例如,机器虽然不知道“知识”的英文是什么,但是在大多数的语料统计后,会发现只要有知识出现的句子,对应的英文例句就会出现“Knowledge”这个字。如此一来,即使不用人工维护词典与文法规则,也能让机器理解单词的意思。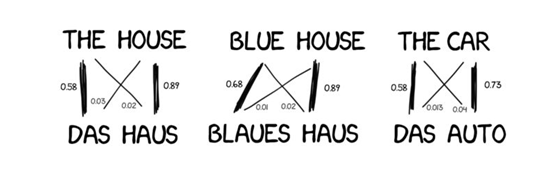
![]()
这个概念并不新,因为最早Warren Weave就提出过类似的概念,只不过那时并没有足够的平行语料以及限于当时计算机的能力太弱,因此没有付诸实行。现代的统计机器翻译要从哪里去找来“现代的罗赛塔石碑”呢?最主要的来源其实是联合国,因为联合国的决议以及公告都会有各个会员国的语言版本,但除此之外,要自己制作平行语料,以现在人工翻译的成本换算一下就会知道这成本高到惊人。
现在我们自己的系统使用的2000万语料有一大部分是来自联合国的平行语料。
https://cms.unov.org/UNCorpus/zh#format
在14年之前,大家所熟悉的Google翻译都是基于统计机器翻译。听到这,应该大家就清楚统计翻译模型是无法成就通天塔大业的。在各位的印像中,机器翻译还只停留在“堪用”而非是“有用”的程度。
神经网络并不是新东西,事实上神经网络发明已经距今80多年了,但是自从2006年Geoffrey Hinton(深度学习三尊大神之首)改善了神经网络优化过于缓慢的致命缺点后,深度学习就不断地伴随各种奇迹似的成果频繁出现在我们的生活中。在2015年,机器首次实现图像识别超越人类;2016年,Alpha Go战胜世界棋王;2017年,语音识别超过人类速记员;2018年,机器英文阅读理解首次超越人类。当然机器翻译这个领域也因为有了深度学习这个超级肥料而开始枝繁叶茂。
Yoshua Bengio在2014年的论文中,首次奠定了深度学习技术用于机器翻译的基本架构。他主要是使用基于序列的递归神经网络(RNN),让机器可以自动捕捉句子间的单词特征,进而能够自动书写为另一种语言的翻译结果。此文一出,Google如获至宝。很快地,在Google供应充足火药以及大神的加持之下,Google于2016年正式宣布将所有统计机器翻译下架,神经网络机器翻译上位,成为现代机器翻译的绝对主流。
简单介绍一下基于神经网络的机器翻译的通用框架:编码器-解码器结构。
用通俗的话来讲,编码器是将信息压缩的过程,解码器就是将信息解码回人能够理解的过程,这种过程信息的损失越少越好。
结构如下图所示:
图1 gnmt机器翻译框架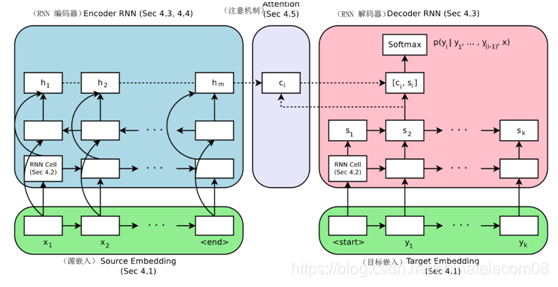
![]()
这个是16年谷歌发表的gnmt框架的结构,使用lstm+attention的机制实现,感兴趣的同学可以去查看论文或者百度相关的博客。
图2 transformer机器翻译框架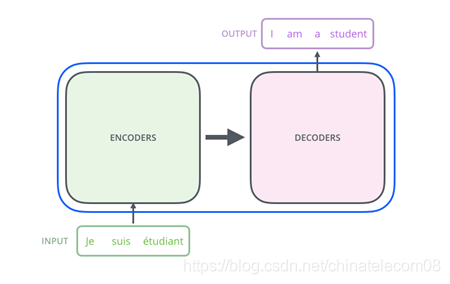
![]()
Transformer是谷歌在17年的一篇论文https://arxiv.org/pdf/1706.03762.pdf提出的具有开创性的架构,这个结构不同于之前所有的机器翻译网络结构,仅仅依靠模型的优势,就取得了state of the art的结果,优于以往任何方法的机器翻译结果。
如果想更深入的了解其中的原理,还是需要阅读一些理论性的文章。如果仅仅想搭建这样一个系统,按照下一篇实践的内容,一步步的进行操作,你就可以拥有搭建基于世界上最先进模型的机器翻译系统的能力了。
这里整理了一些机器翻译中做需要的理论性介绍,包括以下一些内容:
词嵌入向量简单介绍:https://blog.csdn.net/u012052268/article/details/77170517
机器翻译相关论文:
Sequence to Sequence Learning with Neural Networks(2014)
Attention机制的提出(2016)
谷歌基于attention的gnmt(2016)
自注意力机制:transformer(2017)
机器翻译最著名的顶级会议也是比赛就是WMT,世界上所有著名的具有机器翻译引擎技术的巨头公司都在该比赛中取得过名次,该比赛从17年开始,所有取得前几名的队伍都是通过搭建transformer模型来进行优化迭代的。
其中一些队伍提出的方法和技巧,也被各个具有机器翻译技术的公司搜集整理,尝试在自己的翻译引擎中去。
除此之外,国内外一些重要比赛解决方案,也是我们要需要参考的一些点。
http://www.statmt.org/wmt18/

