[知乎作答]·关于在Keras中多标签分类器训练准确率问题
[知乎作答]·关于在Keras中多标签分类器训练准确率问题
本文来自知乎问题 关于在CNN中文本预测sigmoid分类器训练准确率的问题?中笔者的作答,来作为Keras中多标签分类器的使用解析教程。
一、问题描述
关于在CNN中文本预测sigmoid分类器训练准确率的问题?
对于文本多标签多分类问题,目标标签形如[ 0 0 1 0 0 1 0 1 0 1 ]。在CNN中,sigmoid分类器训练、测试的准确率的判断标准是预测准确其中一个标签即为预测准确还是怎样。如何使sigmoid分类器的准确率的判断标准为全部预测准确即为预测准确。有什么解决方案?
二、问题回复
问题中提出的解决多标签多分类问题的解决方法是正确的。但是要注意几点,keras里面使用这种方式的acc是二进制acc,会把多标签当做单标签计算。
什么意思呢?举个例子,输入一个样本训练,共有十个标签,其中有两个为1,而你预测结果为全部是0,这时你得到准确率为0.8。最后输出的ac是所有样本的平均。可以看出这个准确率是不可信的。
解决方法如下:重写acc评价指标,笔者自己写了一个多标签分类的acc,一个样本里,只有全部标签都对应上才acc为1,有一个不对就为0。
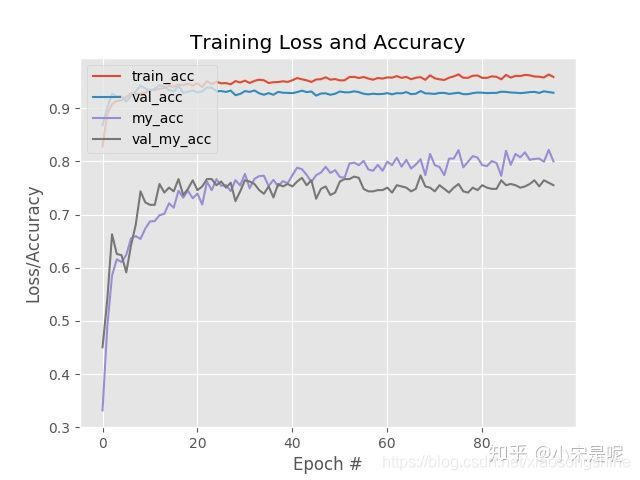
![]()
acc是keras输出acc,my_acc是多标签acc,因为使用了数据增强,valacc更高。
由于每个label的比例不同,又测试不同权重重写loss来对比。发现通过调整合适权重可以,相同参数下可以达到更优效果。
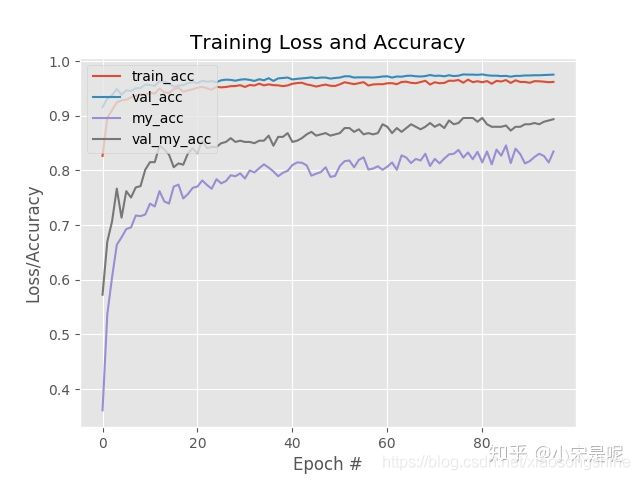
![]()
设置合适的权重值,val_acc上升了,val多标签acc也达到了更高。

