软工实践寒假作业(2/2) (福州大学)
目录
一、阅读《构建之法》并提问
二、WordCount编程
| 这个作业属于哪个课程 | 2021春软件工程实践S班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | ①仔细阅读教材并思考,提出自己对教材的疑惑之处。②初步学习git和github,编写一个词频统计的程序,并将两者运用结合实践,完成一个简单“小项目”。 |
| 作业正文 | ...... |
| 其他参考文献 | ...... |
一、阅读构建之法并提问
问题①
第二章3.2单元测试
描述:单元测试,指对软件中的最小可测试单元进行检查和验证
其实在我阅读之后会有一点点的疑惑。
既然我们学会了单元测试之后,那么应该在什么时候进行测试呢?
又比如像C++、java这类面向对象的语言,我们是应该每构造玩一个函数之后再测试还是在每一个类完成之后统一测试?
如果每完成一个很小模块就进行测试不久会很繁琐且费事吗?但是如果在整合小模块之后再测试,虽然会减小工作量,但是万一出错的话不就很难查找到问题所在吗?这两者之间该怎么权衡呢?
问题②
第三章 3.1个人能力的衡量与发展
描述:团队的软件流程TSP,TSP的提出希望团队成员绝对理性地工作从而反对个人灵感和激情,在大多数人看来这是一个“合格甚至优秀的队员”所必须具备的素质。
但是在我看来,个人灵感和激情也是必须的。因为互联网的一直都在飞速发展,所以我觉得在工作时应该保持激情,才能不断学习新出现的知识。当然也需要灵感,我们在思考一些问题的时候会被一些些问题给“卡住”,也许这时候一点点灵感就可以打通我们的思路。这些东西也许会在我们的工作起到锦上添花的作用,何乐而不为。
问题③
第三章 3.4技能的反面
描述:在这一节中作者提到了一个“玩魔方”的例子。告诉了我们记口诀“熟能生巧”和积极思考、灵活变通之间的区别和联系。
其实我觉得这是一个很矛盾的又很简单的问题,我们应当不断的实践和练习,达到炉火纯青的地步,然后我们思维变得熟练,方法也就变多了。
不过像“将六面魔方还原然后再将其打乱成原样”一般地两者都精通自然是好,但是鱼和熊掌不可兼得,那么在我们学生时代结合当代的软件开和未来的就业形势,当前我们更需要哪一种技能来提升自己呢?
问题④
第五章 5.3.6渐进式交付流程MVP和MBP
描述:MVP更强调更早获得用户反馈,为此可以在产品完成前就发布,强调产品的核心价值,为了突出核心功能,别的辅助功能可以不考虑或者用别的平台提供的服务来代替。
在MVP模式下,用户的反馈显得非常重要。不断完善功能的过程很冗长,这样不就会使得软件开发周期很长吗?而且如果市场反馈不是很积极的话,该软件的开发就十分被动和艰难,甚至有可能会消失,遇到这样的情况该怎么处理呢?
问题⑤
第十一章 11.5.5小强地狱
描述:小强地狱讲的是开发人员可以忽视一定量的bug,优先保证核心功能的实现。
然而在我看来这是一种不太好的开发模式,开发人员往往会受到心理惯性的作用从而导致bug的堆积,测试人员处于长时间空档期或者突然一大堆东西需要测试,很浪费时间和精力。
而且经历过修改bug的我们都知道,这是一件很容易让人心态崩掉的事,所以会降低开发人员的工作积极性。
所以在软件开发的过程中,同时进行一些简单的数据测试,同时修改bug,通过了之后再拿到测试人员处进行更精密的测试,找出更棘手的bug,再统一修改,而不是一昧地开发。这是不是一种更好的开发模式呢?
(目前接触的不多,所以不太了解,可能这样的想法会比较天真)
小故事
关于微软的操作系统windows这个名字的起源的故事
“Windows”为何叫做 Windows?
早在 1975 年 Bill Gates 和 Paul Allen 成立 Microsoft 后,就有意打造可以适合全世界家庭使用的个人计算机。在推出 MS-DOS 后,他们着手一项代称为“Interface Manager 接口管理器”的系统,由于采用图形化管理接口,最终选择了“Windows”这个最适合描述系统特性的名词,作为新系统的名称。Windows 1.0 也在 1983 年正式推出,当时仍是个依附 MS-DOS 上的操作接口,不过已经可以完成在 MS-DOS 中无法使用的多窗口操作。
https://www.cnblogs.com/guanghe/p/10256331.html
二、WordCount编程
2.1Github项目地址
https://github.com/hanxiaotao57/PersonalProject-Java
2.2PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 50 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 20 |
| Development | 开发 | 470 | |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 120 |
| · Design Spec | · 生成设计文档 | 10 | 20 |
| · Design Spec | · 生成设计文档 | 10 | 20 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| · Design | · 具体设计 | 60 | 30 |
| · Coding | · 具体编码 | 240 | 480 |
| · Code Review | · 代码复审 | 30 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 60 | 100 |
| · Test Report | · 测试报告 | 30 | 30 |
| · Size Measuremen | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 60 |
| 合计 | 630 | 1150 |
2.3解题思路描述
①统计字符个数
对文件以字符为单位进行遍历,筛选出符合要求的字符(包括特殊字符),并对字符数量进行加一即可。
②统计文件单词总数
首先创建一个HashMap<String,Integer>以单词为键,单词数量为值。然后对文件进行按行遍历将其构造成一个字符串,并通过正则表达式配合Patten、Matcher类对构造出的字符串进行匹配,然后将单词转化为小写,找出相应的单词之后对其值加一。
③统计文件行数
原先很单纯地以为直接按行读取就可以得到行数,后来发现空白行中换行符、回车符等也会被换做一行。
所以在询问同学和网上查询资料之后发现使用正则表达式配合Patten、Matcher类可以避免这个问题。
④统计词频,并输出词频最高的十个单词
之前已经使用HashMap来储存相应的单词及词频,因此只需要对HashMap中储存的数据按照题目要求进行相应的排序,并最终输出到文件中即可。
2.4代码规范制定链接
https://github.com/hanxiaotao57/PersonalProject-Java/blob/main/221801103/codestyle.md
2.5设计与实现过程
我将所有函数都设置为静态函数,并按照功能划分
- 获取文件流
public static BufferedReader GetFileInputStream(String fileName)
简单地获取文件流。
- 统计文章字符数
public static int CharsCount(String fileName)
{
int count=0;
BufferedReader targetFile=GetFileInputStream(fileName);
int ch;
try
{
while((ch=targetFile.read())!=-1)
{
if(ch>=0&&ch<=127)
{
count++;
}
}
targetFile.close();
}
catch(Exception e)
{
e.printStackTrace();
}
return count;
}
获取文章字符流,然后通过判断文章每一个字符是否在ascii范围内,是则加一。
- 统计文章行数
StringBuilder builder = new StringBuilder();
try
{
int c;
while ((c = targetFile.read()) != -1)
{
builder.append((char) c);
}
targetFile.close();
}
catch (IOException e)
{
e.printStackTrace();;
}
String str=builder.toString();
Pattern linePattern = Pattern.compile("(^|\n)\\s*\\S+");
Matcher matcher = linePattern.matcher(str);
while (matcher.find())
{
count++;
}
首先将字符流构造成为字符串,然后用正则表达式来匹配符合条件的地方,每发现一处则行数加一。
- 统计单词词频
刚开始想到的是用Vector或ArrayList来储存单词及词频,后来仔细一想当词量很大的时候,数组的查找和更新就会有很大的开销,故而选择使用HashMap<String,Integer>来存储。
HashMap<String,Integer> wordHash=new HashMap<String,Integer>();
像上面一样字符流构造字符串。然后同样是通过使用正则表达式配合Pattern、Matcher两个类对字符串进行匹配。
Pattern wordPattern = Pattern.compile("(^|[^A-Za-z0-9])([A-Za-z]{4}[A-Za-z0-9]*)");
Matcher matcher=wordPattern.matcher(str);
while(matcher.find())
{
word=matcher.group(2).toLowerCase();//转化为小写
if(wordHash.containsKey(word))
{
int num=wordHash.get(word);
num++;
wordHash.put(word, (Integer)num);
}
else
{
wordHash.put(word, 1);
}
}
然后到单词排序部分最开始是想使用HashMap配合ollections.sort()和Comparator类进行排序
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>()
{
//降序排序
@Override
public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2)
{
//return o1.getValue().compareTo(o2.getValue());
return o2.getValue().compareTo(o1.getValue());
}
});
但是这样只能满足对值进行排序,没办法对结果进行保留(暂时想不到怎么做),如果再使用一个排序对键进行排序(字典序排序),值就又乱掉了。所以问了一个同学,他教我使用Stream.sort()排序。
//java8特性,利用stream.sorted()进行排序
wordHash = wordHash.entrySet().stream()
.sorted(
Map.Entry.<String, Integer>comparingByValue()
.reversed()
.thenComparing(Map.Entry.comparingByKey()))
.limit(10)//将词数限制在10个之内
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (e1, e2) -> e1, LinkedHashMap::new));
//将map.entrySet()转换成list
List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String,Integer>>(wordHash.entrySet());
将排序结果储存在ArrayList中
- 统计单词词频
public static void OutputFile(String inputFileName,String outputFileName)
这个函数将调用上面全部方法,并经结果输出到目标文件中。
2.6性能改进
①在读取写入I/O时使用缓冲数据流,提高读写效率。
②在读写文件时尽可能的减少读取文件的次数(即尽可能将每种需求的实现过程对文件仅仅读取一次)。
③在刚开始的时候想的是将文件按行读取并处理,但是后来发现这样做会使得代码中出现两层嵌套循环,文件很大的时候会极大降低效率。所以将文件按字符流读取,并使用StringBuilder类将文件内容转化为一个很长的字符串。既方便处理有降低了运行时间。
2.7单元测试
由于我设计的函数的参数是文件名所以测试数据和结果只能在文件中所以只能从文件输出结果来判断。
- 正误判断
输入文件内容
![]()
输入文件内容
![]()
下面一个是我统计的一篇英文文章的结果,由于文章内容太多就不放截图了
![]()
- 单元测试代码
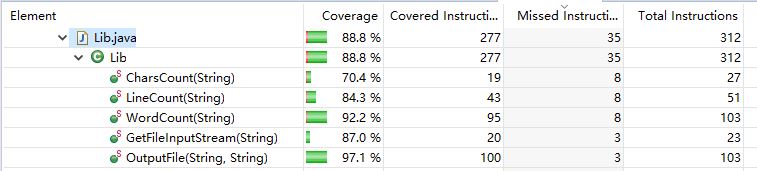
@Before public void setUp() throws Exception { } @Test public void testLineCount() { String fileName="C:\\Users\\韩小韬\\Desktop\\test.txt"; Assert.assertEquals(510,Lib.CharsCount(fileName)); Assert.assertEquals(100,Lib.WordCount(fileName)); Assert.assertEquals(10,Lib.LineCount(fileName)); } - 测试覆盖率截图
![]()
- 如何优化覆盖率?
- 减少不必要的判断。在刚开始设计了一个判断文件是否存在的if语句,后来发现try...catch语句就已经算是文件存在的判断了,所以这个是多余的。
- 消除重复代码。此次作业中多个方法中都有将文件内容转化为字符流再转化为字符串的操作,将这一操作封装起来,然后需要的时候调用就可以。
- 简化逻辑。没什么好说的,就是简化逻辑......



2.8异常处理说明
这次作业中很少出现异常,出现了一两次I/O异常或数组越界异常。发现异常后这些比较简单的异常就交由开发者处理。
2.9心路历程与收获
这次作业对我来说却是是比较困难的,因为之前没参加过什么竞赛或者项目,所以在学习git和github这些东西的时候确实非常吃力,要到处问同学,上网查找资料,曾一度感觉非常烦躁。但是后来通过一点一点的学习,开始逐渐掌握了这些技能。也许之前确实是因为没有勇敢地报名参加活动和比赛,没有动力去学自己才会如此地差劲。或许对我来说,以一个个目的和任务作为导向,我才会去琢磨那些从没学过的知识吧。
在将内容写入文件的时候,因为自己使用的是BufferedWriter类,文件里面一直都没有内容,苦恼了很久很久。后来才发现自己忘记flush()了,所以在编程中我们要注意很多很多的细节,有时候一个很小很简单的错误会浪费我们很多的时间和精力。
在这次学习中学会了较为系统的测试,可以再测试中不断完善代码功能,提高运行效率,让我发现软件不再是单纯地写代码枯燥的事情,还可以进行分析进行测试。
这次不仅让我重新认识到适合自己的学习的方法,同时也学会了许多的技能。比如刚开始我在统计单词的时候想的是通过编写一个函数来判断是否为正确的单词,后来去网上查资料后发现用一个简单的正则表达式(后来有去网上做了简单学习)加上Java里面封装的一些类和方法进行配合就可以做到,十分简单方便。还学会了github的初步使用(其实之前学过一点点,但是后面放弃了(@_@))。相信这些技能、想法和思考会在我今后的学习生活中成为我的强劲助力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号