pandas(9):排序
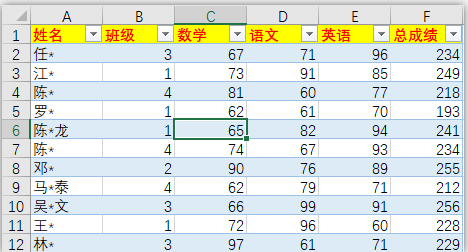
源Excel文件pandas_sort.xlsx:
一、索引排序df.sort_index()
df.sort_index(axis=0, level=None, ascending=True, inplace=False,
kind='quicksort', na_position='last', sort_remaining=True, by=None)
功能:将索引重新排序,数据也跟着索引一起变化。
参数说明:
- axis:0按照行名排序;1按照列名排序
- level:默认None,否则按照给定的level顺序排列。
- ascending:默认True升序排列;False降序排列
- inplace:默认False,否则排序之后的数据直接替换原来的数据框
- kind:排序方法,{‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’。不用太关心。
- na_position:缺失值默认排在最后
- by:按照某一列或几列数据进行排序,但by参数不建议使用。
df = pd.read_excel(r'C:/Users/asus/Desktop/Python/pandas_sort.xlsx')
df = df.set_index('姓名') # 重新设置索引
df.sort_index() # 默认行索引升序
df.sort_index(axis=1,ascending=False) # 按列名(表头),降序
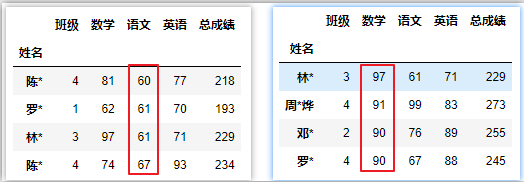
df.sort_index(by=['班级','语文'],ascending=[True,False]) # 不推荐使用
自定义排序的顺序列表函数:df.reindex()
二、数据值排序df.sort_values()
df.sort_values(by, axis=0, ascending=True, inplace=False,
kind='quicksort', na_position='last')
参数说明:
- axis:{0 or ‘index’, 1 or ‘columns’}, default 0,默认按照列排序,即纵向排序;如果为1,则是横向排序。
- by:str or list of str;如果axis=0,那么by="列名";如果axis=1,那么by="行名"。
- ascending:布尔型,True则升序,如果by=['列名1','列名2'],则该参数可以是[True, False],即第一字段升序,第二个降序。
- inplace:布尔型,是否用排序后的数据框替换现有的数据框。
- kind:排序方法,{‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’。似乎不用太关心。
- na_position:{‘first’, ‘last’}, default ‘last’,默认缺失值排在最后面。
df.sort_values('数学') # 数学升序
df.sort_values(by=['班级','数学'],ascending=[True,False]) # 班级升序,数学降序
df.sort_values(by='周*烨',axis=1,ascending=False) # '周*烨'这行降序

三、排序后,获取前N行 nsmallest() 和 nlargest()
df.nsmallest(4,columns=['语文']) # 语文成绩最低的4位同学
df.nlargest(4,columns=['数学']) # 数学成绩最高的4位同学