
SQL练习——LeetCode解题和总结(1)

只用于个人的学习和总结。
178. Rank Scores
一、表信息
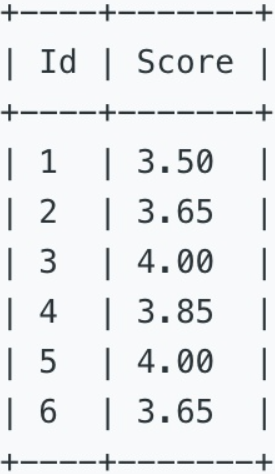
二、题目信息
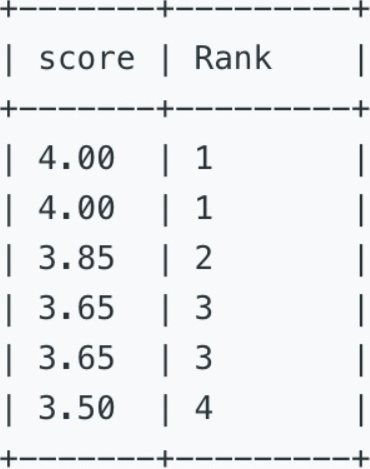
对上表中的成绩由高到低排序,并列出排名。当两个人获得相同分数时,取并列名次,且名词中无断档。
Write a SQL query to rank scores. If there is a tie between two scores, both should have the same ranking. Note that after a tie, the next ranking number should be the next consecutive integer value. In other words, there should be no "holes" between ranks.
For example, given the above Scores table, your query should generate the following report (order by highest score):
三、参考SQL
(1)方法一:直接表内连接
1 select s1.Score,count(distinct s2.Score) as 'Rank' 2 from Scores s1 3 inner join Scores s2 4 on s1.Score<=s2.Score 5 group by s1.id 6 order by count(distinct s2.Score);
分组字段和查询字段不一致,可以在嵌套一层select。
解题思路:
1、欲得到排名,肯定用count进行统计,一个表肯定不行;
2、连接条件:得到大于或等于某个数的集合,比如大于等于3.50的集合就是{3.50,3.65,4.00,3.85,4.00,3.65}
3、分组:得到大于或等于某个数的6个集合组
4、去重统计:因为是排名无断档,需要进行去重再统计,不然就变成统计集合的个数(即大于等于某个值的个数),而不是该值在集合中排名
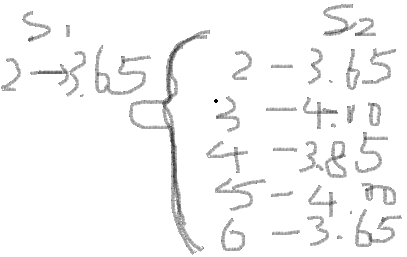
(2)方法二:窗口函数——dense_rank()(MySQL8.0)
1 SELECT Score, 2 DENSE_RANK() OVER(ORDER BY Score DESC) AS 'Rank' 3 FROM Scores;
窗口函数复习:https://zhuanlan.zhihu.com/p/135119865
180. Consecutive Numbers
一、表信息
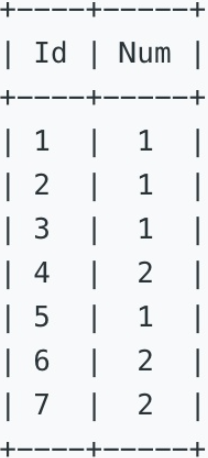
二、题目信息
找出连续出现三次及以上的数字。例如,上表中,应该返回数字 1。
Write a SQL query to find all numbers that appear at least three times consecutively. For example, given the above Logs table, 1 is the only number that appears consecutively for at least three times.
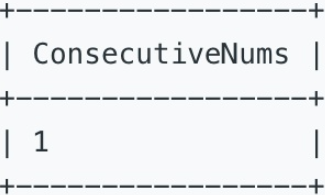
三、参考SQL
方法一:多次连接
select distinct a.num as ConsecutiveNums from Logs a inner join Logs b on a.id=b.id+1 inner join Logs c on a.id=c.id+2 where a.num=b.num and a.num=c.num;
思路总结:
1.连续三次出现,意味着ID连续、值相等。
2.多次连接时,让当前记录、下条记录、下下条记录拼接在一起
3.筛选值相等的行记录,有可能连续出现大于3次,去重即可得到该num。
方法二:窗口函数——行向下偏移lead()
select distinct Num as ConsecutiveNums from (select Num, lead(num,1) over(order by id) as next_num, lead(num,2) over(order by id) as next_next_num from Logs) t where t.Num=t.next_num and t.Num=t.next_next_num;
窗口函数lead():https://www.begtut.com/mysql/mysql-lead-function.html
181. Employees Earning More Than Their Managers[e]
一、表信息
如下 Employee 表中包含全部的员工以及其对应的经理。
The Employee table holds all employees including their managers. Every employee has an Id, and there is also a column for the manager Id.

二、题目信息
基于如上 Employee 表,查出薪水比其经理薪水高的员工姓名。
Given the Employee table, write a SQL query that finds out employees who earn more than their managers. For the above table, Joe is the only employee who earns more than his manager.

三、参考SQL
自连接:
1 select e1.Name as Employee 2 from Employee e1 3 inner join Employee e2 4 on e1.ManagerId=e2.Id 5 where e1.Salary>e2.Salary;
182. Duplicate Emails[e]
一、表信息

二、题目信息
查询重复的邮箱
Write a SQL query to find all duplicate emails in a table named Person. For example, your query should return the following for the above table:

三、参考SQL
方法一:自己写的
select Email from Person group by Email having count(*)>1;
方法二:官方答案
1 SELECT Email FROM 2 (SELECT Email, COUNT(id) AS num 3 FROM Person 4 GROUP BY Email) AS tmp 5 WHERE num > 1;
183. Customers Who Never Order[e]
一、表信息
假设一个网站上包含如下两张表:顾客表和订单表
Suppose that a website contains two tables, the Customers table and the Orders table.
表一:Customers

表二:Orders
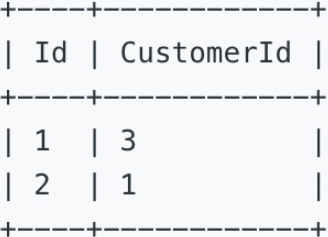
二、题目信息
找出没有下过订单的顾客姓名。
Write a SQL query to find all customers who never order anything. Using the above tables as an example, return the following:

三、参考SQL
方法一:左外连接
1 select Name as Customers 2 from Customers c 3 left join Orders o 4 on c.Id=o.CustomerId 5 where o.Id is null;
方法二:子查询(官方方法)
select Name as Customers from Customers where Id not in( select CustomerId from Orders );
184. Department Highest Salary[M]
一、表信息
表一:Employee
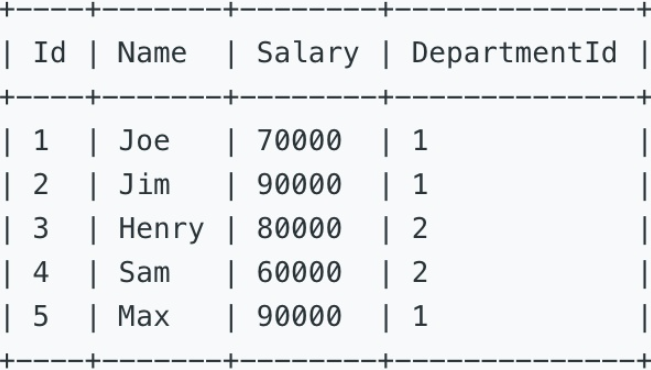
表二:Department
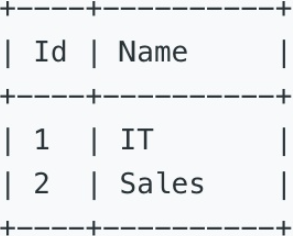
二、题目信息
查询每个部门中,薪水最高的员工姓名及其薪水。
Write a SQL query to find employees who have the highest salary in each of the departments. For the above tables, your SQL query should return the following rows (order of rows does not matter).

三、参考SQL
方法一:窗口函数——dense_rank()
select d.Name as Department,t.Name as Employee,t.Salary from ( select *, dense_rank() over(partition by DepartmentId order by Salary DESC) as ranking from Employee ) t inner join Department d on t.DepartmentId=d.Id where ranking=1;
同一层select下,字段别名不用能与条件筛选!!!执行顺序问题from——.....——where——.....——select——.....
思路:
1.用dense_rank()不断档的方式,给各个部门分组的工资大小排名
2.取排名为1的都是最大工资
方法二:关联子查询
1 select 2 d.Name as Department, 3 t.Name as Employee, 4 t.Salary 5 from Department d 6 inner join 7 (select Name,DepartmentId,Salary 8 from Employee e 9 where (e.DepartmentId,Salary) in 10 (select DepartmentId,max(Salary) 11 from Employee 12 group by DepartmentId) 13 ) t 14 on d.Id=t.DepartmentId;
in可以进行多属性值(column1_name, column2_name,....)进行筛选,一一对应所筛选的字段。
思路:
1.找出部门中最大的工资
2.让原始表中各部门的工资等于最大工资,罗列出所有最大工资。
3.内连接查询相关信息
185. Department Top Three Salaries[h]
经典topN问题:记录每组最大的N条记录,既要分组,又要排序。
一、表信息
表一:Employee
表二:Department
二、题目信息
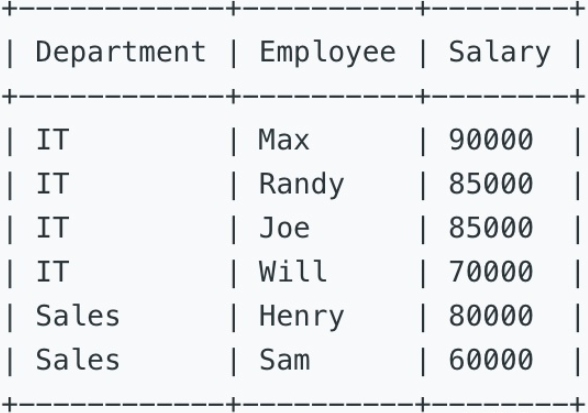
查询各部门薪水排名前三名的员工姓名及薪水。
Write a SQL query to find employees who earn the top three salaries in each of the department. For the above tables, your SQL query should return the following rows (order of rows does not matter).
三、参考SQL
方法一:窗口函数——dense_rank()
1 select 2 d.name as Department, 3 e.name as Employee, 4 Salary 5 from Department d 6 inner join 7 ( 8 select name,Salary,DepartmentId, 9 dense_rank() over(partition by DepartmentId order by Salary desc) as ranking 10 from Employee 11 ) e 12 on d.Id=e.DepartmentId 13 where ranking<=3;
思路:
1.用dense_rank(),按照部门分组并降序排列,不间断编上排名
2.筛选排名小于等于3的记录,就是前三工资的记录。
(ps:用窗口函数做,思路和上题差不多,区别只是后面筛选的条数)
方法二:自连接分组筛选
1 select 2 d.name as Department, 3 e.name as Employee, 4 Salary 5 from Department d 6 inner join 7 ( 8 select e1.Id,e1.DepartmentId,e1.name,e1.Salary 9 from Employee e1 10 inner join Employee e2 11 on e1.DepartmentId=e2.DepartmentId 12 and e1.Salary<=e2.Salary 13 group by e1.Id 14 having count(distinct e2.Salary)<=3 15 ) e 16 on d.Id=e.DepartmentId;
思路:
1.关键是要找出各部门前三工资的记录:
自连接,连接条件为部门相等,工资比我大或者相等;
按员工分组,则组记录为比我大或者相等全部员工记录;
统计组记录条数,少于等于3条,则表示我一定是工资第三的,这里有一点注意,不能用count(*),因为和我工资相等的员工除了我本身,还有可能有其他员工,如果不去重,就会导致记录条数大于3(假设我刚好是第三),从而筛选掉,这不是想要的结果;
2.再按需求做相关查询即可
(ps这题的自连接条件思路和178题差不多)
196. Delete Duplicate Emails[E]
一、表信息

二、题目信息
删除邮件重复的行,当有重复值时,保留Id最小的行。
Write a SQL query to delete all duplicate email entries in a table named Person, keeping only unique emails based on its smallest Id. For example, after running your query, the above Person table should have the following rows:

三、参考SQL
方法一:子查询
1 delete from Person 2 where Id not in( 3 select Id from 4 ( 5 select min(Id) AS Id 6 from Person 7 group by Email 8 ) t 9 );
思路:
1.子查询找出不用删除的邮箱Id集合(重复邮箱的最小Id加上邮箱不重复的Id):邮箱分组,取最小Id即可。
2.删除时,判断Id不在此集合即可
(ps:MySQL不让同时对统一表进行修改和查询操作,所以需要外层嵌套一层辅助表;min(Id)要记得起别名)
方法二:自连接
1 delete p1 from Person p1 2 inner join Person p2 3 on p1.Email=p2.Email 4 and p1.Id>p2.Id;
思路:
1.邮箱相等进行连接得到的集合为:(1)邮箱相等,Id也相等。即不重复的(2)邮箱相等,p1.Id>p2.Id(3)邮箱相等,p1.Id<p2.Id
2.把邮箱相等,p1.Id>p2.Id提取出来,删除端即可。这样就保留了小和不重复的。
(ps:联级删除也有这种语法——delete 表名 from .....)
197. Rising Temperature[E]
一、表信息
二、题目信息
以下图为例,找出比前一天温度高的id。
Write an SQL query to find all dates' id with higher temperature compared to its previous dates (yesterday).
Return the result table in any order.
The query result format is in the following example:
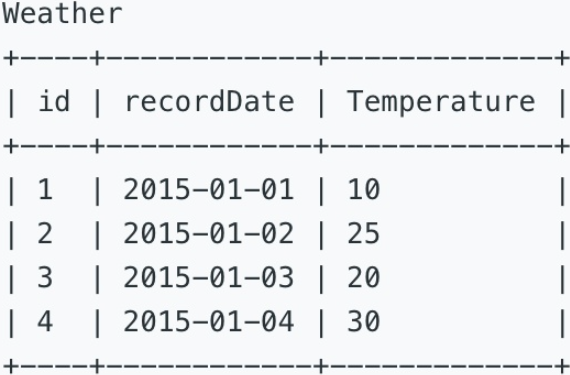

三、参考SQL
1 select w1.id as Id from Weather w1 2 inner join Weather w2 3 on datediff(w1.recordDate,w2.recordDate)=1 4 where w1.temperature>w2.temperature;
思路:
1.自内连的笛卡尔积中,去取出间隔相差一天的记录,用datadiff()函数。
2.再筛选出温度比上一天高ID即可。
(ps;日期不能进行简单的相加相减,最好使用日期函数。https://www.w3school.com.cn/sql/sql_dates.asp)
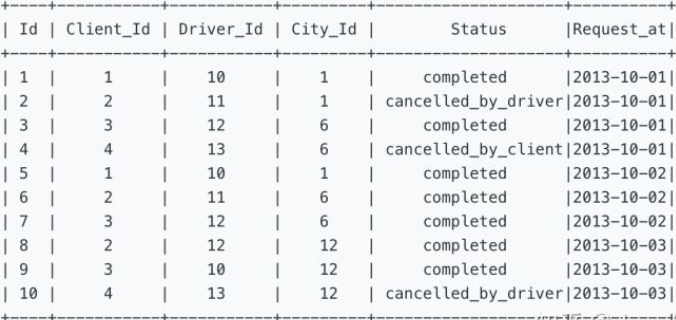
262. Trips and Users[H]
一、表信息
表一:Trips
该表包含全部出租车信息的记录。每一条记录有一个 Id,ClientId 和 Drive_Id 都是与 Users 表联结的外键。Status 包含 completed, cancelled_by_driver, 和 cancelled_by_client 三种状态。
The Trips table holds all taxi trips. Each trip has a unique Id, while Client_Id and Driver_Id are both foreign keys to the Users_Id at the Users table. Status is an ENUM type of (‘completed’, ‘cancelled_by_driver’, ‘cancelled_by_client’).
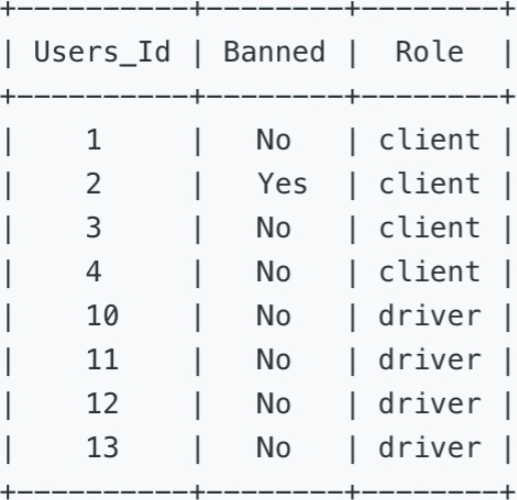
表二:Users
该表包含全部的用户信息。每一个用户都有一个 Id,Role有三种状态:client, driver 以及 partner。
The Users table holds all users. Each user has an unique Users_Id, and Role is an ENUM type of (‘client’, ‘driver’, ‘partner’).
二、题目信息
找出2013年10月1日至2013年10月3日期间,每一天 未被禁止的 (unbanned) 用户的订单取消率。
Write a SQL query to find the cancellation rate of requests made by unbanned users (both client and driver must be unbanned) between Oct 1, 2013 and Oct 3, 2013. The cancellation rate is computed by dividing the number of canceled (by client or driver) requests made by unbanned users by the total number of requests made by unbanned users.
取消率的计算方式如下:(被司机或乘客取消的非禁止用户生成的订单数量) / (非禁止用户生成的订单总数)
For the above tables, your SQL query should return the following rows with the cancellation rate being rounded to two decimal places.
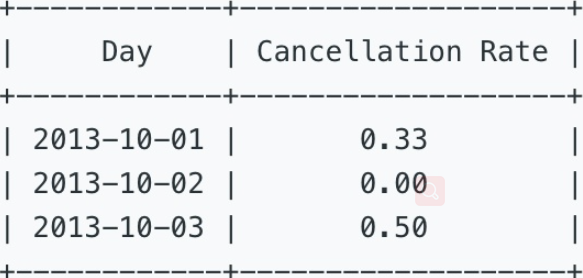
三、参考SQL
方法一:子查询筛选出有效订单记录
SELECT Request_at AS 'Day', round( count( CASE t_Status WHEN 'completed' THEN NULL ELSE 1 END ) / count( * ), 2 ) AS 'Cancellation Rate' FROM ( SELECT Request_at, Status as t_Status FROM Trips WHERE Client_Id NOT IN ( SELECT Users_Id FROM Users WHERE Banned = 'Yes' ) AND Driver_Id NOT IN ( SELECT Users_Id FROM Users WHERE Banned = 'Yes' ) ) t WHERE Request_at BETWEEN '2013-10-01' AND '2013-10-03' GROUP BY Request_at
思路:
1.重要一点是筛选出有效订单记录集合:顾客和司机都是未被禁止的!
子查询:
Client_Id NOT IN ( SELECT Users_Id FROM Users WHERE Banned ='Yes' )
AND Driver_Id NOT IN ( SELECT Users_Id FROM Users WHERE Banned = 'Yes')
2.在上一步基础上,统计每天分组被取消的订单,用case when语句:当订单是complated完成状态时,返回null,这样count就不会计数。
方法二:连接查询筛选出有效订单记录集合
计算订单取消率还可以用avg(Status!='completed'):
https://leetcode-cn.com/problems/trips-and-users/solution/ci-ti-bu-nan-wei-fu-za-er-by-luanz/
511. Game Play Analysis I[E]
一、表信息
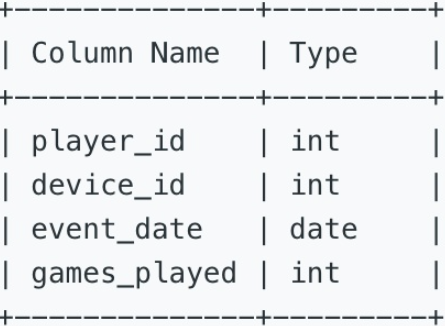
该Activity表记录了游戏用户的行为信息,主键为(player_id, event_date)的组合。每一行记录每个游戏用户登录情况以及玩的游戏数(玩的游戏可能是0)。
(player_id, event_date) is the primary key of this table. This table shows the activity of players of some game. Each row is a record of a player who logged in and played a number of games (possibly 0) before logging out on some day using some device.
二、题目信息
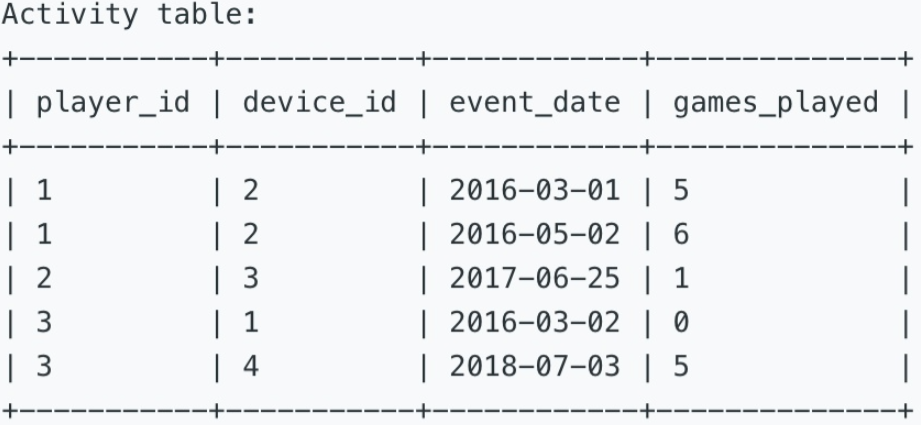
查询每个用户首次登陆的日期
Write an SQL query that reports the first login date for each player.
The query result format is in the following example:

三、参考SQL
1 SELECT 2 player_id, 3 MIN( event_date ) AS first_login 4 FROM 5 Activity 6 GROUP BY 7 play_id 8 ORDER BY 9 play_id;
512. Game Play Analysis II[E]
一、表信息
同上题
二、题目信息
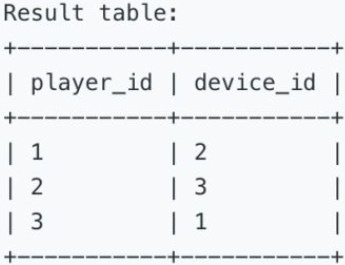
查询每个用户首次登陆的日期所使用的设备。
Write a SQL query that reports the device that is first logged in for each player.
三、参考SQL
方法一:内连接+子查询
1 SELECT 2 a.player_id, 3 a.device_id 4 FROM 5 Activity AS a 6 INNER JOIN ( SELECT player_id, MIN( event_date ) AS first_login FROM Activity GROUP BY player_id ORDER BY player_id ) AS b 7 ON a.player_id = b.player_id AND a.event_date = b.first_login 8 ORDER BY 9 a.player_id;
思路:
1.通过子查询查出表b:每个玩家最早登录的日期
2.再进行内连接(或者where筛选都可以)。
方法二:窗口函数dense_rank()
1 SELECT 2 player_id, 3 device_id 4 FROM 5 ( SELECT player_id, device_id, RANK ( ) OVER ( PARTITION BY player_id ORDER BY event_date ) AS rnk FROM Activity ) AS tmp 6 WHERE 7 rnk = 1;
思路:
1.player_id分组,event_date升序,不间断排名
2.取排名为1即为玩家最早登录的信息记录
534. Game Play Analysis III[M]——分组累加和
一、表信息
同上
二、题目信息
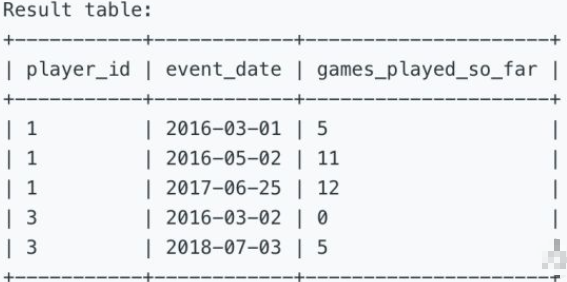
按照日期,查询每个用户到目前为止累积玩的游戏数。
Write an SQL query that reports for each player and date, how many games played so far by the player. That is, the total number of games played by the player until that date. Check the example for clarity.
三、参考SQL
方法一:窗口函数sum()
1 SELECT 2 player_id, 3 event_date, 4 SUM( games_played ) over ( PARTITION BY player_id ORDER BY event_date ) AS games_played_so_far 5 FROM 6 activity;
思路:
1.player_id分组,event_date升序
2.对分组后的games_played进行累计求和
方法二:内连接后分组统计
1 SELECT 2 a1.player_id, 3 a1.event_date, 4 SUM( a2.games_played ) AS games_played_so_far 5 FROM 6 activity a1 7 INNER JOIN activity a2 ON a1.event_date >= a2.event_date 8 AND a1.player_id = a2.player_id 9 GROUP BY 10 a1.player_id, 11 a1.event_date;
思路:
1.对于这种需要分组累计统计的(求和、计数也好),内连接的连接条件一般都是非等值连接,让主表的某个字段的值对应连接从表的同样字段的多个值

这样对主表的该字段进行分组后,就可以对从表的某个字段进行统计操作。
2.涉及到需要分组两次的话,还要注意连接条件要加多一个等值判断,避免组内的字段的值连接到其他组的字段值


没有进行组内的等值连接条件的限定,不同组的值乱连接匹配。导致最后分组统计结果不正确。
3.得到连接总表后,按要求进行统计即可。
550. Game Play Analysis IV[M]
一、表信息
同上题
二、题目信息
查询首次登录后第二天也登录的用户比例。
Write an SQL query that reports the fraction of players that logged in again on the day after the day they first logged in, rounded to 2 decimal places. In other words, you need to count the number of players that logged in for at least two consecutive days starting from their first login date, then divide that number by the total number of players.
The query result format is in the following example:
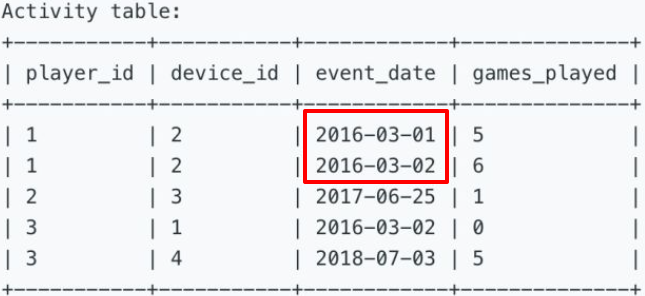

三、参考SQL
方法一:内连接(统计连续两天登录)
1 SELECT 2 ROUND( 3 COUNT( CASE datediff( a1.event_date, a2.event_date ) WHEN 1 THEN 1 ELSE NULL END ) / COUNT(DISTINCT a1.player_id),2) AS fraction 4 FROM 5 activity a1 6 INNER JOIN activity a2 7 ON a1.player_id = a2.player_id 8 AND a1.event_date >= a2.event_date;
思路:
1.内连接的条件和思路和上题一样
2.统计连续两天登入,只需要同一用户,登录日期相差一天即可。(注意:这里不是统计首次登录第二天也登录的记录,而是只要连续两天登录的记录,因为开始日期可能不是最小日期)
方法二:子查询+外连接(统计统计首次登录第二天也登录)
SELECT ROUND( COUNT( DISTINCT t.player_id ) / COUNT( DISTINCT a1.player_id ), 2 ) AS fraction FROM activity a1 LEFT JOIN ( SELECT player_id, MIN( event_date ) AS first_login FROM activity GROUP BY player_id ) t ON a1.player_id = t.player_id AND DATEDIFF( a1.event_date, t.first_login ) = 1;
思路:
1.先用子查询查出每个用户登录的最早时间first_login
2.左外连接:id相等,和最早登录时间相差一天。得到的表为:第二天用户也登录的记录会和first_login连接,第二天不登录用户irst_login则为null(不是相差一天)
3.统计第二天登录的用户:COUNT( DISTINCT t.player_id ),null值不统计;不能用COUNT( t.player_id is not null )
(PS:原则上 t.player_id记录是唯一的,除非一个用户第二天登录会产生多条记录,而不是记录最后一次登录)
方法三:窗口函数_FIRST_VALUE()
1 SELECT 2 ROUND(COUNT(DISTINCT t.player_id)/COUNT(DISTINCT a1.player_id),2) AS fraction 3 FROM activity a1 4 LEFT JOIN (SELECT player_id,first_value(event_date) over(partition by player_id ORDER BY event_date) AS first_login FROM activity) t 5 ON a1.player_id=t.player_id 6 AND DATEDIFF(a1.event_date,t.first_login)=1
569. Median Employee Salary[H]
一、表信息
下面的员工表包含全部的员工ID,公司名称以及每个员工的薪水。
The Employee Table holds all employees. The employee table has three columns: Employee Id, Company Name, and Salary.
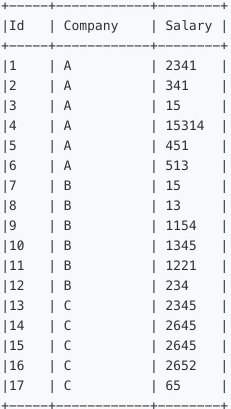
二、题目信息
找出各公司薪水的中位数。不用SQL内建函数。
Write a SQL query to find the median salary of each company. Bonus points if you can solve it without using any built-in SQL functions.
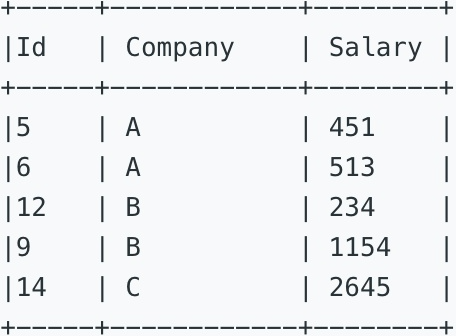
三、参考SQL
方法一:根据中位数最原始的定义
1 SELECT 2 e1.Id, 3 e1.company, 4 e1.salary 5 FROM 6 (SELECT Id,company,salary,@rnk:=IF(@pre=company, @rnk:=@rnk+1,1) AS rnk,@pre:=company 7 FROM employee,(SELECT @rnk:=0, @pre:=NULL) AS init 8 ORDER BY company,salary,Id 9 ) e1 10 INNER JOIN 11 (SELECT company,COUNT(*) AS cnt FROM employee GROUP BY Company 12 ) e2 13 ON e1.company=e2.company 14 WHERE e1.rnk IN (cnt/2+0.5,cnt/2,cnt/2+1);
思路:
中位数定义:奇数个数字时,中位数是中间的数字;偶数个数字时,中位数中间两个数的均值(这里只列出两个数,不求值)。即,数列总个数为N,则:
-
N为奇数,中位数排序编号是(N+1)/2=N/2+0.5
-
N为偶数,中位数排序编号是N/2和N/2+1
由于一个数列N总个数不是奇就是偶(互斥),所以(N/2+0.5)和(N/2、N/2+1)也是互斥,两个元组的元素不可能同时为整数,也就是说无论数列总个数N是奇还偶,都可以直接这样判断:
中位数位置序号 IN (N/2+0.5,N/2,N/2+1)
基于上述可以得到大致的思路:
1.对薪水进行分组排序(不间断连续),用自定义变量方法或者MySQL8.0的ROW_NUMBER()窗口函数
2.求总个数cnt,count(*)
3.筛选出中位数的位置序号e1.rnk IN (cnt/2+0.5,cnt/2,cnt/2+1)
其他方法:
https://www.cnblogs.com/qcyye/p/13451067.html
https://zhuanlan.zhihu.com/p/257081415
570. Managers with at Least 5 Direct Reports[M]
一、表信息
下面员工表中包含各部门员工信息及其对应的经理。
The Employee table holds all employees including their managers. Every employee has an Id, and there is also a column for the manager Id.
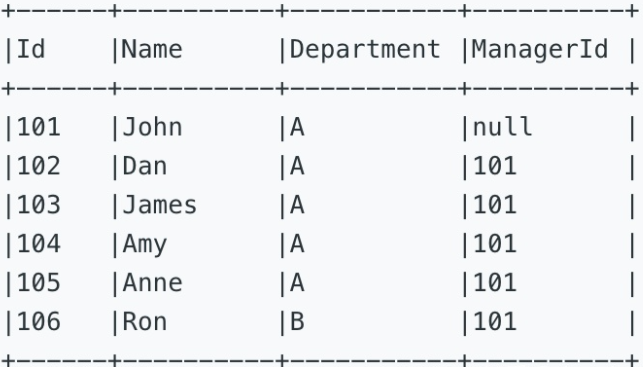
二、题目信息
查询出至少管理5个员工的经理的名称。
Given the Employee table, write a SQL query that finds out managers with at least 5 direct report. For the above table, your SQL query should return:
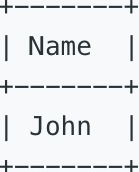
三、参考SQL
方法一:子查询
1 SELECT NAME 2 FROM 3 employee 4 WHERE 5 Manager_id IN ( SELECT Manager_id FROM employee GROUP BY Manger_id HAVING COUNT( * ) >= 5 );
571. Find Median Given Frequency of Numbers[H]
一、表信息
下表记录了每个数字及其出现的频率。
The Numbers table keeps the value of number and its frequency.

二、题目信息
根据每个数字出现的频率找出中位数。
Write a query to find the median of all numbers and name the result as median. In this table, the numbers are 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 3, so the median is (0 + 0)/2 = 0.
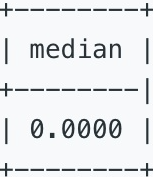
三、参考SQL
参考答案:
https://www.e-learn.cn/topic/3843270
574. Winning Candidate[M]
一、表信息
表一:Candidate
该表中包含候选人的id和姓名。
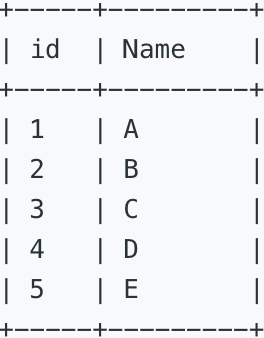
表二:Vote
该表中id是自增列,CandidateId 对应 Candidate 表中的id。
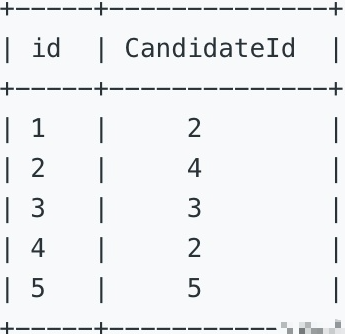
二、题目信息
找到当选者的名字。注意:本题目中不考虑平票的情况,也就是说只有一个当选者。
Write a sql to find the name of the winning candidate, the above example will return the winner B.
Notes: You may assume there is no tie, in other words there will be only one winning candidate.

三、参考SQL
方法一:子查询
1 SELECT NAME 2 FROM 3 candidate 4 WHERE 5 id = ( SELECT candidateid FROM vote GROUP BY candidateid ORDER BY COUNT( * ) DESC LIMIT 1 );
1.题目要求当选者只有一个,也就是获票数最高只有一个
2.求分组最高:按candidateid分组,统计每个人票数,降序排列取第一行记录
3.只有一个,让‘id=’即可筛选出来。
(ps:多个票数相等的话,要用‘id in’,但是直接对limit字句的子查询用‘id in’会报错误:This version of MySQL doesn't yet support 'LIMIT & IN/ALL/ANY/SOME subquery',需要再嵌套一层子查询https://blog.csdn.net/sjzs5590/article/details/7337552)
方法二:内连接
1 SELECT 2 c.NAME 3 FROM 4 candidate c 5 INNER JOIN ( SELECT candidateid FROM vote GROUP BY candidateid ORDER BY COUNT( * ) DESC LIMIT 1 ) t 6 ON c.id = t.candidateid;
拓展:假若有多个票数相等的怎么办?加多一个投票(6,5),即vote表变成;
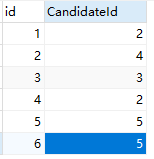
则查询结果为:
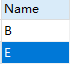
思路:
1.分组统计票数,然后用窗口函数dense_rank()对票数进行不间断连续排名
2.排名为1的即是票数最高的
1 SELECT 2 NAME 3 FROM 4 candidate 5 WHERE 6 id IN 7 ( 8 SELECT 9 candidateid 10 FROM 11 ( 12 SELECT 13 candidateid, 14 dense_rank ( ) over ( ORDER BY poll DESC ) AS ranking 15 FROM 16 ( SELECT candidateid, COUNT( * ) AS poll FROM vote GROUP BY candidateid ) t1 17 ) t2 18 WHERE 19 ranking = 1 20 );
小结:到目前为止dense_rank()窗口函数已完成如下问题
- 直接对某字段排名,取topN——只有一个组。178题
- 先分组,再对分组后的某字段进行组内排名——取组内topN。185题
- 先分组,再对分组进行统计,再对统计后的结果进行排名——取组某个统计属性(组的条数、组的某个字段和、平均等等)的topN。本题拓展
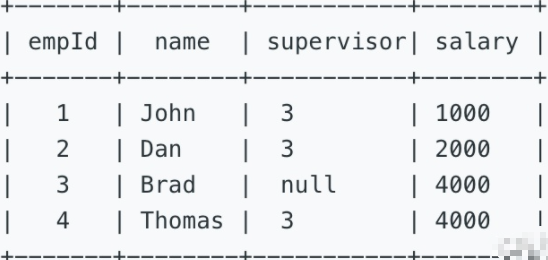
577. Employee Bonus[e]
一、表信息
表一:Employee
Employee表中,empId 是主键。
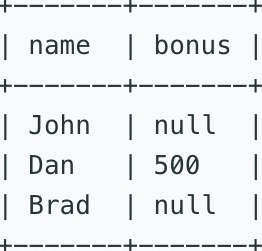
表二:Bonus
Bonus 表中 empId 是主键。

二、题目信息
选出奖金小于1000元的员工姓名及其获得的奖金数。
Select all employee's name and bonus whose bonus is < 1000.
三、参考SQL
方法一:左连接
1 SELECT 2 e.NAME, 3 b.bonus 4 FROM 5 Employee e 6 LEFT JOIN Bonus b ON e.empId = b.empId 7 WHERE 8 b.bonus < 1000 9 OR b.bonus IS NULL;
思路:
1.奖金少于1000:包括没奖金为null,和有奖金但<1000
2.Bonus 表只记录有奖金的,自然想到左外连接
方法二:子查询
1 SELECT 2 a.NAME, 3 b.bonus 4 FROM 5 Employee AS a 6 LEFT JOIN Bonus AS b ON a.empId = b.empId 7 WHERE 8 a.empId NOT IN ( SELECT empId FROM Bonus WHERE bonus >= 1000 );
思路:
奖金少于1000有两种情况,但奖金大于等1000只有一种情况
578. Get Highest Answer Rate Question[M]
一、表信息
下面 survey_log 表中包含id, action, question_id, answer_id, qnum, timestamp。其中id代表用户编号,action 为 "show", "answer", 以及 "skip" 中的一个值,当 action 值为 "answer" 时,answer_id 则不是空值,否则 answerid 为空值。q_num 是该问题出现的顺序
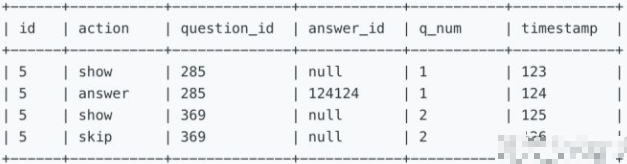
二、题目信息
找到回答率最高的问题编号。其中,回答率 = (action 为 answer 的次数)/(action 为 show 的次数)。
Write a sql query to identify the question which has the highest answer rate.
Note:The highest answer rate meaning is: answer number's ratio in show number in the same question.
三、参考SQL
个人理解题目:大概类似于知乎的问题推送。系统或其他用户广播式的推送(show)某个问题给若干个同一画像用户群体,收到推送用户可能只是浏览skip,或者回答answer。统计回答率最高的问题,可以知道该用户群体喜欢什么样类型的问题,下次推送时,可以为这类用户群体多推送该类问题。最终达到问题被回答最大化,提高问题回答率。甚至可以给用户做基础分类或分类优化,如果用户开始没有主动选择便签的话。
方法一:分组+按需统计+按需排序后截取
1 SELECT question_id AS survey_log 2 FROM 3 (SELECT 4 question_id, 5 SUM(IF(action='answer',1,0)) as answer_num, 6 SUM(IF(action='show',1,0))as show_num 7 -- SUM(case when action="answer" THEN 1 ELSE 0 END) AS num_answer, 8 -- SUM(case when action="show" THEN 1 ELSE 0 END) AS num_show, 9 FROM survey_log 10 GROUP BY question_id) t 11 ORDER BY answer_num/show_num DESC 12 LIMIT 1;
思路:
1.在子查询中,通过对问题进行分组,统计问题被show了多少次,被answer了多少次(不能对用户分组,题目的表只是一部分,同一个问题可能会show多个用户,但不是每个都会answer,研究的对象是某个问题)
2.外层查询,常见的降序取最大值。
方法二:简化版
1 SELECT question_id AS survey_log 2 FROM 3 survey_log 4 GROUP BY question_id 5 ORDER BY COUNT(answer_id)/COUNT(IF(action='show',1,NULL)) DESC 6 LIMIT 1
思路:answer_id只有在问题被回答了才有信息。count不会统计为NULL的值。
579. Find Cumulative Salary of an Employee[H]
一、表信息
下面的 Employee 表包含了员工一年中薪水的情况。
The Employee table holds the salary information in a year.
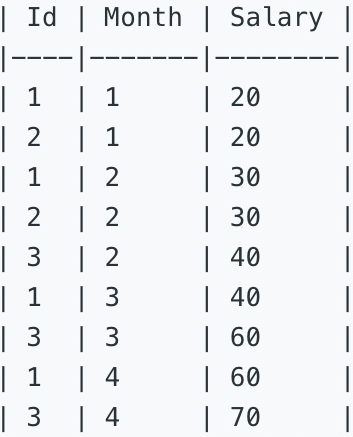
二、题目信息
查询出每个员工三个月的累积工资,其中不包含最近一个月,且按照员工id升序排列,月份降序排列。
Write a SQL to get the cumulative sum of an employee's salary over a period of 3 months but exclude the most recent month.
The result should be displayed by 'Id' ascending, and then by 'Month' descending.
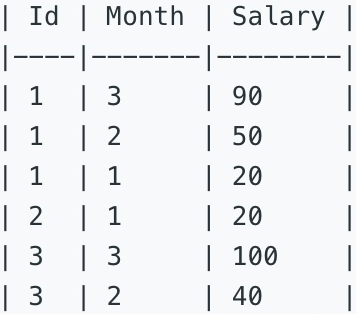
三、参考SQL
方法一:窗口函数sum()和dense_rank()
1 SELECT Id,MONTH,cum_sum AS Salary 2 FROM 3 ( 4 SELECT *,dense_rank ( ) over ( PARTITION BY id ORDER BY cum_sum DESC ) AS ranking 5 FROM 6 ( SELECT id, MONTH, SUM( Salary ) over ( PARTITION BY Id ORDER BY month ) AS cum_sum FROM employee_579 ) t1 7 ) t2 8 WHERE 9 ranking <> 1 10 ORDER BY Id,MONTH DESC;
思路:(分组——统计——排名——筛选)
1.子查询t1:窗口聚合函数sum,按员工id分组,month降序进行工资累加,起别名为cum_sum
2.为了剔除最后一个月(最近一个月)的工资累加记录,子查询t2:用dense_rank()对cum_sum进行降序不间断连续排名,则最后一个月记录排名为1
3.加多一层查询筛选掉最后一个月记录的数据(ranking<>1),最后按需查询显示即可
(PS:假如最近一个月工资为0,那么用dense_rank()排名就会出现两个1,所以最好用row_number()函数吧。没试过,应该逻辑没错的!)
觉得太丑的话,可以用with as 语句进行美化:
1 WITH s AS 2 (SELECT Id, month, Salary, 3 Sum(Salary) OVER (PARTITION BY Id ORDER BY Month) as SumSal, 4 ROW_NUMBER() OVER (PARTITION BY id ORDER BY id ASC, month DESC) rn 5 FROM employee_579) 6 7 SELECT Id,Month,SumSal as Salary 8 FROM s 9 WHERE rn > 1;
方法二:官方答案
1 SELECT E1.id, E1.month, 2 (IFNULL(E1.salary, 0) + IFNULL(E2.salary, 0) + IFNULL(E3.salary, 0)) AS Salary 3 FROM 4 ( 5 SELECT id, MAX(month) AS month FROM Employee 6 GROUP BY id 7 HAVING COUNT(*) > 1 8 ) AS maxmonth 9 LEFT JOIN Employee AS E1 10 ON (maxmonth.id = E1.id AND maxmonth.month > E1.month) 11 LEFT JOIN Employee AS E2 12 ON (E2.id = E1.id AND E2.month = E1.month - 1) 13 LEFT JOIN Employee AS E3 14 ON (E3.id = E1.id AND E3.month = E1.month - 2) 15 ORDER BY id ASC, month DESC;
思路:
1.分组求最大月份(最近一个月),只有一个月的having掉,因为最近一个不统计
2.第一个left,连接条件的目的是想把最大月份给筛选掉
3.后面几个left则是为了,为累加做准备,形成金字塔类型表结构:
E1.salary E2.salary E3.salary ..........
第一月 NULL NULL
第一月 第二月 NULL
第一月 第二月 第三个月
.........
然后,就可以这样进行计算了(IFNULL(E1.salary, 0) + IFNULL(E2.salary, 0) + IFNULL(E3.salary, 0)) AS Salary,只想说,真秒!虽然我不会。。。。
580. Count Student Number in Departments[M]
一、表信息
表一:Student
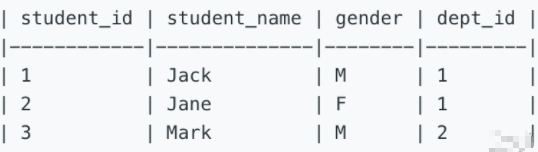
表二:Department

二、题目信息
查询每个部门下的学生数,要列出所有部门,即使该部门没有学生。结果按学生数降序、部门名称升序排列。
三、参考SQL
1 SELECT a.dept_name, COUNT(b.student_id) AS student_number FROM department AS a 2 LEFT JOIN student AS b 3 ON a.dept_id = b.dept_id 4 GROUP BY a.dept_name 5 ORDER BY student_number DESC, a.dept_name;
思路:左连接注意从表主表;分组时,注意分段字段和查询字段一致
584. Find Customer Referee[E]
一、表信息
customer表中包含顾客编号、顾客名称、以及推荐人编号。
Given a table customer holding customers information and the referee.
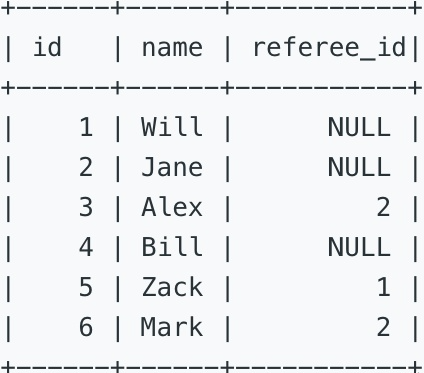
二、题目信息
找出不是被2号顾客推荐来的顾客姓名。
Write a query to return the list of customers NOT referred by the person with id '2'.
For the sample data above, the result is:
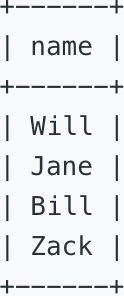
三、参考SQL
方法一:子查询
1 SELECT name FROM customer WHERE 2 id NOT IN 3 (SELECT id FROM customer WHERE referee_id = 2);
(ps:子查询如果有limit等字句,记得要多加一层查询)
方法二:OR IS NULL
1 SELECT name FROM customer 2 WHERE referee_id <> 2 OR referee_id IS NULL;
(PS:由于 SQL 的三值逻辑,如果条件只是 WHERE referee_id <> 2,则返回不出 referee_id 为 null 的顾客。此外,如果将条件写成 referee_id = NULL 同样也是错误的,因为判断空值必须使用 IS NULL/IS NOT NULL。)
方法三:IFNULL()函数
SELECT name FROM customer WHERE IFNULL(referee_id, 0) <> 2;
(PS:关于各种null函数——https://blog.csdn.net/pan_junbiao/article/details/85928004)
方法四:连环判断NULL函数——coalesce()
1 SELECT name FROM customer 2 WHERE COALESCE(referee_id, 0) <> 2;
(PS:关于此函数——https://blog.csdn.net/weixin_38750084/article/details/83034294)
585. Investments in 2016[M]
一、表信息
二、题目信息
三、参考SQL
586. Customer Placing the Largest Number of Orders[E]
一、表信息
下图中的订单表orders包含了订单号,顾客编号,下单日期,要求日期,发货日期,状态,以及评论。

二、题目信息
找出下单数最多的顾客,列出customer_number。注意:结果只有一个值,不会存在多个值,也就是默认最大值只有一个。
三、参考SQL
方法一:
1 SELECT 2 customer_number 3 FROM 4 orders 5 GROUP BY 6 customer_number 7 ORDER BY 8 COUNT( * ) DESC 9 LIMIT 1;
思路:
分组后,在order by 后使用聚合函数进行排序,这种用法可以节省很多SQL语句。
方法二:
1 SELECT customer_number FROM orders 2 GROUP BY customer_number 3 HAVING COUNT(customer_number) >= ALL 4 (SELECT COUNT(customer_number) FROM orders GROUP BY customer_number);
595. Big Countries[e]
一、表信息
World表中包含世界各国家、所属洲、国土面积、人口数以及GDP信息。

二、题目信息
找到国土面积大于300万平方公里或人口数超过2500万的国家,并显示器人口数和国土面积。
A country is big if it has an area of bigger than 3 million square km or a population of more than 25 million.
Write a SQL solution to output big countries' name, population and area.
For example, according to the above table, we should output:
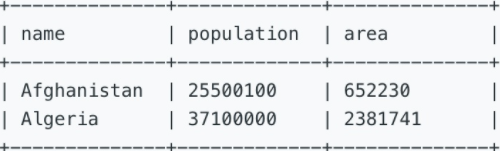
三、参考SQL
1 SELECT name, population, area FROM World 2 WHERE area > 3000000 3 OR population > 25000000;
596. Classes More Than 5 Students[E]
一、表信息
courses表中包含学生 id 和 课程名称。
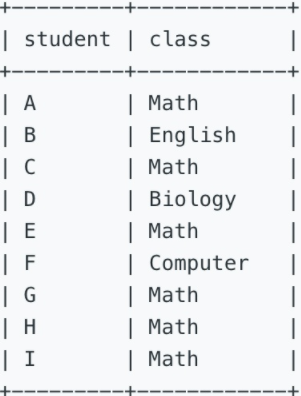
二、题目信息
列出至少有5名学生的课程名称。注意:每个学生只算作一次。
Please list out all classes which have more than or equal to 5 students.
Note: The students should not be counted duplicate in each course.
For example, the table:

三、参考SQL
方法一:
1 select class from courses 2 group by class 3 having count(distinct student)>=5;
思路:
直接在having用聚合函数进行筛选合适的组(课程)
方法二:子查询
1 select class 2 from 3 ( 4 select count(distinct student) as num,class 5 from courses 6 group by class 7 ) t 8 where num>=5;
注意事项:
1.where不能直接用聚合函数进行筛选,需要起别名num
2.子查询派生表要起别名t
597. Friend Requests I: Overall Acceptance Rate[E]
一、表信息
In social network like Facebook or Twitter, people send friend requests and accept others’ requests as well. Now given two tables as below:
表一:friend_request好友请求
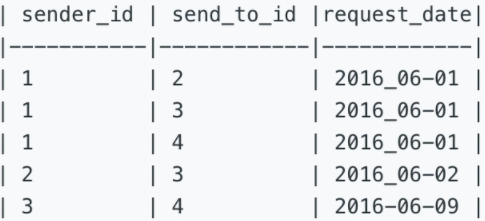
表二:request_accepted申请请过

二、题目信息
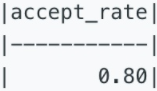
找出申请通过率,结果保留两位小数。
Write a query to find the overall acceptance rate of requests rounded to 2 decimals, which is the number of acceptance divides the number of requests.
注意:
- 接受的申请不单来源于 friend_request 表。因此,只需对两张表分别进行计数,然后求出通过率即可。即通过率=接受请求的总数/请求数量
- 邀请人对同一个人可能不止发送过一次邀请;接受人也可以多次接受同一个邀请。因此要移除重复记录。
- 如果完全没有邀请记录,则结果返回0.00。
针对如上的两张表,结果应该返回0.80。
三、参考SQL
1 SELECT 2 ROUND( 3 IFNULL( 4 (SELECT COUNT(DISTINCT requester_id,accepter_id) FROM request_accepted597) 5 / 6 (SELECT COUNT(DISTINCT sender_id,send_to_id) FROM friend_request597) 7 ,0) 8 ,3) 9 AS accept_rate;
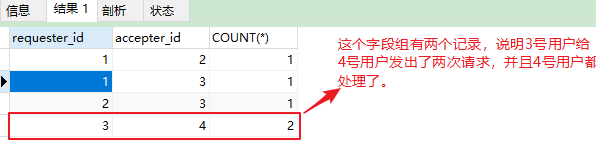
思路:
1、用两个子查询分别在两个表中计算接受的请求总数、发出的请求总数;
2、求两者比率即可
(PS:去重统计数量的时候,两个字段相同才是真的重复,平时count函数里面一般就只加一个字段进行去重)
还可以用group by进行统计,看看那个字段组重复,比如,
1 SELECT requester_id,accepter_id,COUNT(*) FROM request_accepted597 GROUP BY requester_id,accepter_id;
601. Human Traffic of Stadium[H]
一、表信息
某城市建了一个新的体育馆,每天有许多人来参观。下表记录了该自增编号、参观日期以及参观人数的信息。
X city built a new stadium, each day many people visit it and the stats are saved as these columns: id, visit_date, people
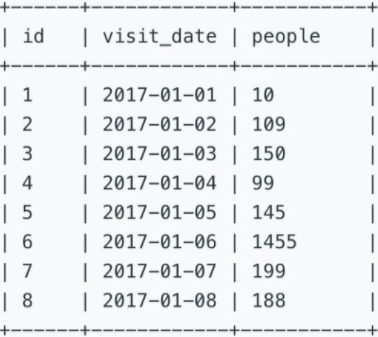
二、题目信息
找出连续至少三条记录体育馆参观人数至少为100人的情况。
Please write a query to display the records which have 3 or more consecutive rows and the amount of people more than 100(inclusive).
注意:每一天只有一行记录,且参观日期随编号列增加。
Note: Each day only have one row record, and the dates are increasing with id increasing.
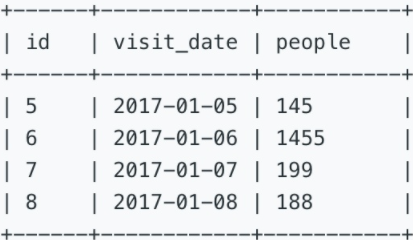
三、参考SQL
方法一:
1 SELECT s1.* FROM 2 stadium601 s1 3 LEFT JOIN stadium601 s2 4 ON s1.id=s2.id-1 5 LEFT JOIN stadium601 s3 6 ON s2.id=s3.id-1 7 WHERE s1.people>=100 8 AND (s2.people>=100 OR s2.people IS NULL) 9 AND (s3.people>=100 OR s3.people IS NULL) 10 ORDER BY s1.id;
思路:
1、连续两次左连接,连接条件为id-1,相当于与把表向上平移一个单位,把三天的记录拼接到一行记录,得到下面的表:
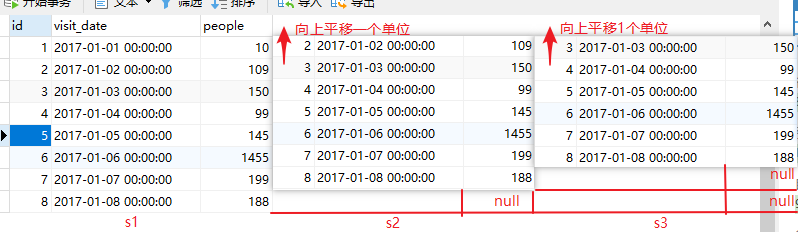
2、筛选:我们注意到,连接后得到的表中。s1的people字段不可能为null,若s3的people字段为null,说明该行记录为倒数第二行,若s2的people字段为null,说明该行记录为最后一行,这就是为什么用左连接的原因。所以,筛选的时候要注意s2.people和s3.people可以为null的情况。
3、查出s1.*记录即可
(PS:这种连续出现的问题,连接条件应该考虑让表向上平移一个1单位,类似题有180题。真实的业务场景大概就是找出满足某个条件的某个时间段,比如用户的活跃时间周期、商场火爆周期等等)
方法二:
1 WITH 2 tmp AS ( 3 SELECT a.visit_date AS date1, 4 b.visit_date AS date2, 5 c.visit_date AS date3 6 FROM stadium601 AS a 7 LEFT JOIN stadium601 AS b 8 ON b.id = a.id + 1 9 LEFT JOIN stadium601 AS c 10 ON c.id = a.id + 2 11 WHERE a.people >= 100 12 AND b.people >= 100 13 AND c.people >= 100 14 ), 15 16 tmp1 AS ( 17 SELECT date1 AS total_date FROM tmp 18 UNION 19 SELECT date2 AS total_date FROM tmp 20 UNION 21 SELECT date3 AS total_date FROM tmp 22 ) 23 24 SELECT * FROM stadium601 25 WHERE visit_date IN 26 (SELECT * FROM tmp1);
思路:
1、注意id-1和id+1的链接效果,一个往上平移,一个往下平移。不要想当然id+1是下移!!!
2、注意union的用法:
1 SELECT column_list 2 UNION [DISTINCT | ALL] 3 SELECT column_list 4 UNION [DISTINCT | ALL] 5 SELECT column_list
默认是distinct,结果集是去重的,而 all是不去重的!
602. Friend Requests II: Who Has the Most Friends[M]
一、表信息
卡卡卡卡卡卡,怎么博客园编辑器那么卡。大概是图片太多了。
二、题目信息
三、参考SQL
