性能监控命令vmstat详解【杭州多测师】【杭州多测师_王sir】
vmstat命令:用来获得有关进程、虚存、页面交换空间及 CPU活动的信息。这些信息反映了系统的负载情况。
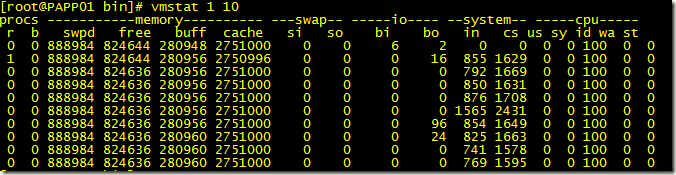
vmstat 命令的输出
vmstat 1 10
实例解读一:
CPU状态的监控指标主要有以下几个参数获得:
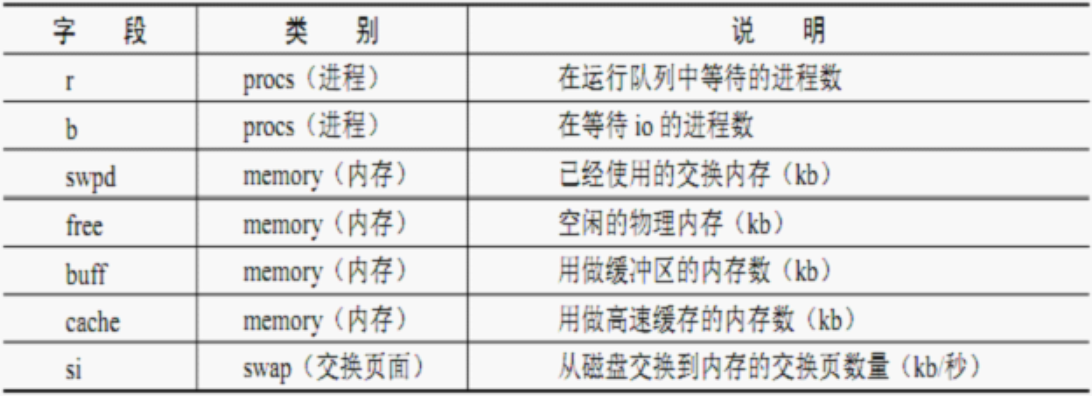
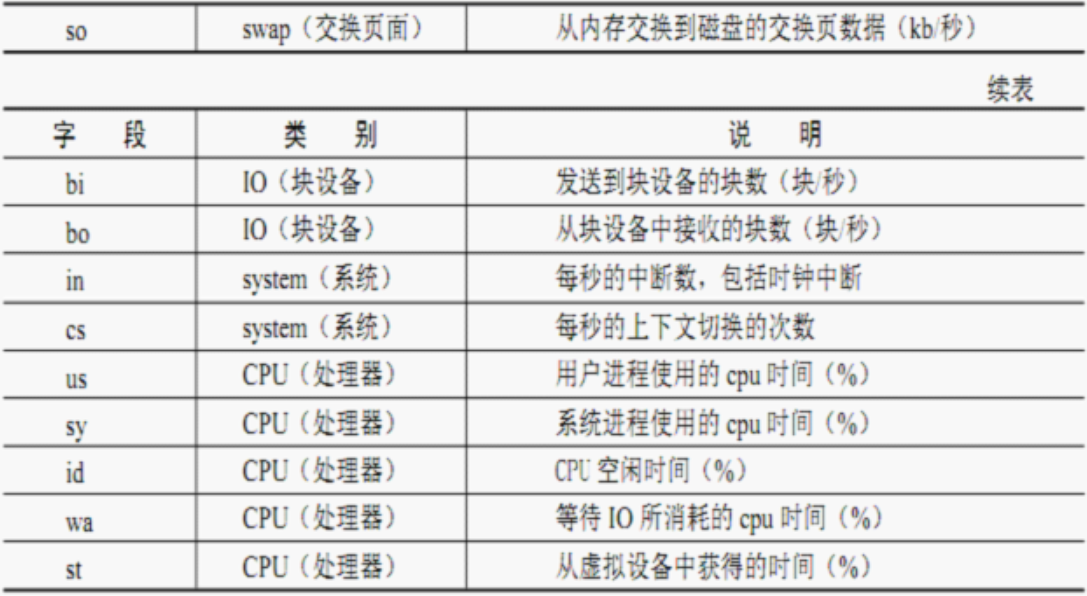
r:在运行队列中等待的进程数
b:在等待IO的进程数
cs:每秒的上下文切换的次数
us:用户进程使用的CPU时间(%)
sy:系统进程使用的CPU时间(%)
id:CPU空闲时间(%)
wa:等待IO所消耗的CPU时间(%)
由上面的命令输出中可以看到:
1. IO等待的CPU时间(wa)非常高,而实际运行用户和系统进程的CPU时间却不高
2. 存在等待IO的进程(b>0)
由此可以得出结论:系统目前CPU使用率高是由于IO等待所造成的,并非由于CPU资源不足。用户应检查系统中正在进行IO操作的进程,并进行调整和优化。
正常的CPU状态图,可以与上图作比较:

实例解读二:大量的算术运算
本程序会进入一个死循环,不断的进行求平方根的操作,模拟大量的算术运算的环境.
root@debian6:~# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 0 772300 42420 175356 0 31 5 138 22 14 0 0 99 0
1 0 0 772292 42420 175356 0 0 0 0 45 22 5 0 95 0
1 0 0 772284 42420 175356 0 0 0 0 276 15 100 0 0 0
1 0 0 772284 42420 175356 0 0 0 0 298 12 100 0 0 0
1 0 0 772284 42420 175356 0 0 0 0 273 11 100 0 0 0
1 0 0 772284 42420 175356 0 0 0 0 278 16 100 0 0 0
由于不断地在做算术运算,从上面可以看出:
1. r表示在运行队列中等待的进程数,上面的数据表示r=1,一直有进程在等待,
2. in表示每秒的中断数,包括时钟中断,运行队列中有等待的进程(看参数r的值),中断数in就上来了
3. us表示用户进程使用的cpu时间,随着r=1,用户的cpu占用时间直接达到了100%
4. id表示cpu的空闲时间,一开始的时候id很高,达到95%,后来程序开始跑,cpu一直处于繁忙状态(看参数r,us的值),id就一直为0,等程序终止,id就是上去了
实例解读三:大量的系统调用
本脚本会进入一个死循环,不断的执行cd命令,从而模拟大量系统调用的环境
root@debian6:~# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 0 772300 42500 175364 0 30 5 136 22 14 0 0 99 0
0 0 0 772300 42500 175364 0 0 0 0 27 14 0 0 100 0
1 0 0 772220 42500 175364 0 0 0 0 213 2482 6 70 24 0
1 0 0 772204 42500 175364 0 0 0 0 283 3298 8 92 0 0
1 0 0 772204 42500 175364 0 0 0 0 281 3343 5 95 0 0
结论:随着程序不断调用cd命令,运行队列有等待的进程r(看参数r),每秒的中断数in(看参数in),下文切换的次数cs骤然提高(看参数cs),系统占用的cpu时间sy(看参数sy)也不断提高,cpu空闲时间id(看参数id)一直为0。
当程序终止的时候,r,in,cs,sy数据都下来了,id上去了,表示系统已经空闲下来了。
实例解读四:大量的io操作
我们用dd命令,从/dev/zero读数据,写入到/tmp/data文件中,如下:
dd if=/dev/zero of=/tmp/data bs=1M count=1000
root@debian6:~# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 0 772176 42564 175352 0 30 5 134 23 14 0 0 99 0
0 0 0 772176 42564 175352 0 0 0 0 35 15 0 1 99 0
1 0 0 687220 42564 257976 0 0 4 0 181 23 0 55 45 0
root@debian6:~# dd if=/dev/zero of=/mnt/date1 bs=1M count=1000
1000+0 records in
1000+0 records out
1048576000 bytes (1.0 GB) copied, 6.31404 s, 166 MB/s
root@debian6:~# dd if=/dev/zero of=/mnt/data1 bs=1M count=1000
1000+0 records in
1000+0 records out
1048576000 bytes (1.0 GB) copied, 2.19338 s, 478 MB/s
1. bo写数据到磁盘的速率,bi是从磁盘读的速度
2. dd不断的向磁盘写入数据,所以bo的值会骤然提高,而cpu的wait数值也变高,说明由于大量的IO操作,系统的瓶径出现IO设备上
3. 由于对文件系统的写入操作,cache也从175352KB提高到了952236KB,又由于大量的写中断调用,in的值也从35提高到638,上下文切换cs的值从23到了611
接下来我们还用dd命令,这回从/tmp/data文件读,写到/dev/null文件中,如下:
dd if=/tmp/test1 of=/dev/null bs=1M
root@debian6:~# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 0 15568 11444 972748 0 25 11 135 23 14 0 0 100 0
0 0 0 15568 11444 972760 0 0 0 0 16 13 0 0 100 0
1 1 0 14692 11444 973084 0 0 46396 0 432 687 0 13 57 30
1 1 0 14568 11444 973228 0 0 129152 0 1103 1917 0 22 0 78
root@debian6:~# dd if=/mnt/data1 of=/dev/null bs=1M
1000+0 records in
1000+0 records out
1048576000 bytes (1.0 GB) copied, 5.1614 s, 203 MB/s
1. dd不断的从/tmp/data磁盘文件中读取数据,所以bi的值会骤然变高,最后我们看到b(在等待io的进程)也由0变成了1甚至到2
2. dd读的时候,in中断数和cs上下文切换很高,还有就是等待IO所消耗的cpu时间wa相当高
3. 因此,这时的性能瓶颈在读上面,有程序在发生大量读的请求。
实例解读五:大量的占用内存
本程序会不断分配内存,直到系统崩溃
root@debian6:~# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 0 880944 70656 51692 0 0 125 13 27 35 0 2 97 1
0 0 0 880944 70656 51692 0 0 0 0 17 12 0 0 100 0
1 0 0 733344 70656 51692 0 0 0 0 259 339 2 52 46 0
1 0 0 312240 70656 51692 0 0 0 0 484 674 2 98 0 0
1 0 0 152776 70656 51692 0 0 0 0 417 469 0 100 0 0
0 2 0 12396 68868 45748 0 0 0 0 410 444 1 97 0 2
1 0 652 605960 60932 39120 0 908 0 908 141 130 0 34 0 66
0 0 524 903632 60932 39136 0 0 0 0 32 14 0 3 97 0
0 0 524 903632 60932 39136 0 0 0 0 13 8 0 0 100 0
0 0 524 903632 60932 39136 0 0 0 0 13 9 0 0 100 0
0 0 524 903632 60932 39136 32 0 32 0 14 12 0 0 99 1
结论:我们看到cache迅速减少,而swpd迅速增加,这是因为系统为了分配给新的程序,而从cache(文件系统缓存)回收空间,当空间依然不足时,会用到swap空间.
而于此同时,si/so也会增加,尤其是so,而swap属于磁盘空间,所以bo也会增加

 浙公网安备 33010602011771号
浙公网安备 33010602011771号