
cluster集群基本概念
cluster集群种类:
1,LB(Load Balance)负载均衡集群:
弱点:当横向扩展到一定机器后,发现在怎么横向加机器也没有效果的时候,瓶颈就卡在分发的服务器上了,也就是LB机器上了,如何解决呢?功能拆分吗,一个功能一个LB集群。
2,HA(High Availability)高可用集群:有多个LB,一旦主LB挂断,副LB马上取而代之。副LB怎么知道主LB是否还或者呢,主LB每间隔一段时间(1秒或者半秒)向副LB集群发送还活着的信息,副LB接到了主LB还或者的信息,就知道了它还或者。如果多次副LB没有接收到主LB的活着的信息,则取而代之。那么副LB怎么取代主LB呢,把主LB的IP设置成自己机器的IP,并启动和主LB同样的服务。
3,HP(High performance)集群
- 向量机:通过在一台机器上增加硬(比如加100个CPU)件的方式提高性能。
- 并行处理集群:横向扩展
- 需要一个分布式文件系统
- 将大任务切割为小任务,分别进行处理的机制
上面3种集群的各自用途:
-
LB用于高并发
-
HA用于高稳定
-
HP用于海量数据分析(大数据分析,比如分析中国15亿人),复杂的科学计算,模拟核弹爆炸,天气预报
集群节点间的文件同步:
rsync:远程文件拷贝命令
inotify :内核监控文件发生变化后,会发信号给用户进程。
所以使用rsync+inotify ,可以实现,各个服务器机器见的静态文件的同步。
health check:
试想一下,如果LB下的某个机器坏掉了,会发生什么情况?LB分发到这台机器上的请求,这台机器不能处理了。所以LB需要知道地下的机器哪些挂掉了,哪些又从挂掉的状态恢复成正常状态了,这就是health check。如果发现它挂掉了,则不往它这里分发请求了。如果它又恢复了,则继续往它这里分发请求。
DAS和NAS
DAS:direct attached storage
以块为单位请求文件
NAS:network attached storage
以整个文件为单位请求文件
DAS的传输速度根据设备类型的不同,最少也能320Mbps,最高的能6Gbps;
而百兆以太网的速度为12.5Mbps,千兆125Mbps。
所以DAS的性能更好。如果多台主机同时使用DAS设备,是通过线连接到DAS设备上的,DAS设备相当于一块硬盘,里面没有操作系统,所以主机1写DAS上的文件A,主机B也写DAS上的文件A,文件A就会错乱。主机1的进程1写DAS上的文件A,主机1的进程2写DAS上的文件A,主机1的操作系统会提供锁机制。
主副切换时,会产生split-brain:脑裂
主服务器由于太忙了,没来得及给副服务器发送心跳信息,这时副服务器取代了主服务器,
但是在主服务器还有一些数据没有写到DAS设备上,数据就丢失了。
如何解决呢,防止主服务器是假死,所以补上一刀,直接拔掉主服务器的电源。
只要主服务器和副服务器都插在一个电源管理器上的话,副服务器发送关闭主服务器的命令给电源管理器械就行了。
stonith:shoot the other node in the head爆头。
隔离机制:fencing
1,节点级别:stonith
2,资源级别:切断某个主机能够访问DAS的接口
如果只有主服务器和一个副服务器,它们2个就会来回强着当主服务器,为了避免split-brain,我们就需要至少3台服务器或者奇数个服务器作为一个集群。
- 其中一台接受不到另外2台的心跳了,自动把自己下线
- 其中2台都接受不到另外一条的心跳了,杀死它。
LB集群
-
Hardware
- F5(最好?),BIG IP
- Citrix,Netscaler
- A10(最便宜)
-
Software
-
四层
- LVS(Linux Virtual Server)国人发明的
-
七层
-
nginx
http ,smtp,pop3,imap
-
haproxy
http,tcp(mysql,smtp)
-
-
四层和七层的区别:4层是在IP和端口上做负载均衡,7层是在特定的应用层协议上做负载均衡。
-
四层的LVS说明
LVS不能和iptables一起使用,LVS是工作在内核区域的。
iptables/netfilter
LVS
- ipvsadm:用户区。管理集群服务的命令行工具
- ipvs:在内核区
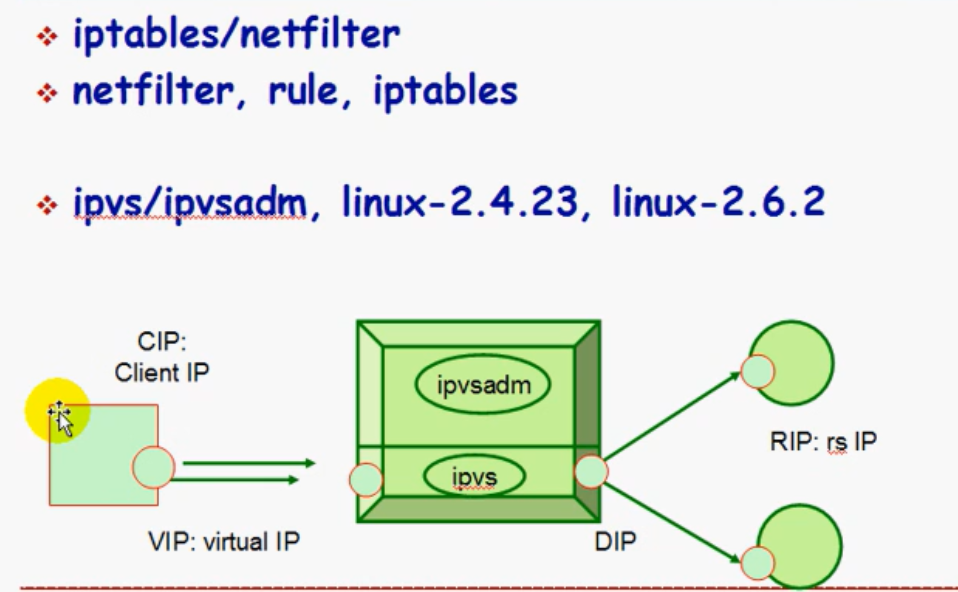
IP地址的名词解释:
- CIP:客户端的IP
- VIP:负载均衡机器(director)的公网IP,也就是客户端发送请求里的目标IP。
- DIP:转发请求时,使用的IP
- RIP:集群节点机器的IP
LVS种类:
1,NAT
- 集群主机必须和负载均衡主机在同一个内网了,而且DIP必须是RIP们的网关
- RIP是私有IP
- DIP位于CIP和RIP之间,即负责CIP过来接收请求,然后把目标IP从VIP修改为RIP,然后RIP机器处理完成后,把相应再发回DIP机器(director),然后DIP再把目标IP从RIP修改回VIP。所以director的负载很重
- 支持端口映射,RIP的服务的端口可以是任意的
- real server可以是任意操作系统,但是director必须是Linux系统
- 确定director是最容易形成性能瓶颈的。最多挂10 real server
,DR:直接路由。被使用最多

-
集群节点必须和director在同一个物理网络中(同一个物理网络是什么意思???)
-
director只负责接收请求,而不负责响应;相应报文直接发给CIP
-
实际过来的是,请求端IP为CIP,目标端IP为VIP。
-
每台RIP机器配2个IP,一个是VIP但必须是隐藏的,负责IP就会冲突了;另一个是RIP
-
当CIP的请求发送到了VIP,然后director不修改目标IP,所以目标IP还是VIP,它修改MAC地址,把目标IP携带的MAC地址修改为RIP的,real server处理完后,把相应报文用隐藏的VIP发送给CIP,这样一来就不用经过director了。
VIP是配置到网卡别名上,并且是隐藏的,不用于接受请求,只用于发送相应。
-
RIP可以使用公网IP,实现便捷的远程管理。也可以是私有IP
-
集群节点一定不能将网关指向DIP
-
director不支持端口映射
-
RIP机器上可以使用大多数操作系统,前提是支持IP隐藏功能。
-
DR模式可以带动更多的real server,至少100以上。
理由:只负责接收请求,而不负责响应;请求报文很小,响应报文很大,director不处理响应报文了,所以性能提高很大。
3,TUN模式
解决real server 分布在不同的国家,不同的城市
- director通过隧道协议把原CIP和目标VIP作为报文发给realserver,发的时候,使用DIR-》RIP
- RIP要有公网IP,realserver的OS必须支持隧道协议
- 其余的和DR模式一样
调度算法:静态调度,动态调度
(active)活动连接数:正在传输数据
(inactive)非活动连接数:传输数据完成了,但是连接还没有断开。
静态调度(固定调度):调度器不管realserver的活动连接数和非活动连接数,按照事先指定好的算法调度。所以就有可能把某个realserver累死了,有的闲死了。
-
rr:轮询(平均呼叫)
-
wrr:weight 加权轮询(性能好的realserver多叫,不好的少叫)
-
sh(source hash 原地址hash):只要是同一个CIP来的请求,都给固定的realserver。
感觉很奇怪,这不就破坏了负载均衡的机制了吗,为什么会有这样的算法?
http协议是无状态的短链接,所以server处理完会给浏览器发送一个身份信息,来标识这个client,
浏览器会把这个信息保存在本地的cookie中。早期cookie里有太多的敏感信息,会泄露用户的信息,
所以浏览器保存了最少量的信息,变成了轻cookie,原来的信息放到了server端,存到了server的内存中,叫session。就是为了找到原来的session,才需要把同一个CIP导向到原来的real server。
如果各个节点的real server可以同步session的话,sh调度算法就没有使用的必要了。
-
dh(destination hash 目标地址hash):和sh算法类似。用于缓存服务器集群。保证缓存命中率的提高。
动态调度:调度器要考虑realserver的活动连接数和非活动连接数
- lc(最少连接):计算:active × 256 + inactive,结果最小的realserver,作为这次的目标realserver
- wlc:加权lc。计算:(active × 256 + inactive)/weight,结果最小的realserver,作为这次的目标realserver。wlc被使用最多
- sed(最短期望延迟)计算:(active+1) × 256/weight,结果最小的realserver,作为这次的目标realserver
- np(never queue 永不排队):只要有个realsever没有被分到,就分给它一个再说。
- lblc(基于本地的最少连接):相当于动态的dh,不考虑active数
- lblcr(基于本地的带复制功能的最少连接):考虑active数
c/c++ 学习互助QQ群:877684253


 浙公网安备 33010602011771号
浙公网安备 33010602011771号