面向高维和不平衡数据分类的集成学习研究论文研读笔记
高维不平衡数据的特征(属性)较多,类标号中的类别分布不均匀的数据。
高维数据分类难本质问题:
1.密度估计难问题;
2.维数灾难:特征数增加意味着分类所需的样本数量的增加;
3.Hughes问题:给出了一个广义上的数据测量复杂度,训练样本数量和分类精度三者间的关系即对有限样本而言,存在一个最优的数据复杂度,可使分类精度达到最优。若数据特征数很多,量过精度过高,都会导致分类精度下降。
分类中的数据不平衡有两种:类间不平衡和类内不平衡,本文研究的是类间不平衡。
数据不平衡的分类困难的本质原因:
1.不恰当的评估标准:传统的分类算法通常在假设类别平衡的前提下,采用分类准确率作为评价标准,以平均准确率最大化为目标当类别不平衡时,为达到精度最大化,往往会牺牲少数类的性能;
2.数据稀疏:数据稀缺分为两种:绝对稀缺和相对稀缺绝对稀缺是指样本数量绝对过少,导致该类信息无法在训练数据中充分表达,而相对稀缺是指少数类本身数量并不过少,只是相对大类而言,占有的比例相对过少;
3.数据碎片:采用分治类的算法,如决策树算法,将原始问题划分为多个子问题来处理对于少数类而言,本身的数据量就不充分,划分后的子空间包含的数据信息就更少,使得一些跨空间的数据规律不能被挖掘出来,形成数据碎片;
4.不恰当的归纳偏差:不恰当的归纳算法往往不利于少数类的分类学习;
5.噪声。在噪声过滤的方法中,有些是将少数类作为噪声,删除后则少数类的数量将更稀疏。另外,由于少数类和噪声难以区分,往往把噪声数据包含在训练过程中,导致一些真正的少数类无法得到好的训练。
高维数据分类有两种解决思路:
(1)在预处理阶段降维,减少特征数量;
(2)设计适用于高维数据分类的新算法。
分类前通过降维可一定程度解决高维数据引起的维数灾难常用的降维方法有两类:特征变换状语从句:特征选择。
1)特征变换:将原有特征空间进行某种形式的变换,重新产生一个低维且各维间更为独立的特征空间,包含线性变换和非线性变换两种。
2)特征选择:共从原始特征空间中选择一部分重要属性,组成新的特征空间,通过特征选择,删除一些和任务无关或者冗余的特征,简化的数据集常常会得到更精确地模型,也更容易理解。
根据特征选择中子集的选择的方式不同,特征选择算法被划分为三类:
1)过滤式(过滤器):把特征选择作为分类的一个预处理步骤,仅从特征本身出发,根据特征间的相关度选择子集,不考虑选择特征后的应用,选择过程独立于分类算法;
2)封装式(包装器):把分类算法作为选择的一个部分,研究发现,特征的最优子集依赖于分类算法的特定偏差,因此特征选择应考虑分类器的特性;
3)嵌入式(嵌入式):将特征选择过程与学习器训练过程融为一体,两者在同一优化过程中完成,即在学习器的训练过程中自动的进行了特征选择。
一般而言,封装式的方法比单个过滤方法具有更高的准确率,但是由于需要在每个子集上进行评估,更为耗时。
降维方法可以大量减少特征数量,使普通算法能够分类高维数据,但降维算法所获得的结果是单个特征子集,这将损失其他特征所带来的信息,特征子集选取的好坏对于算法的性能将有较大的影响。为解决这一问题,一些适用于高维数据分类的算法相继提出,SVM是统计学习理论基础上发展起来的分类算法,适用于解决小样本和高维数据分类,但SVM存在两个问题:(1)对大型数据集,计算量大,速度慢;(2)面对高维数据集,分类结果难以解释而基于规则的分类方法可以解决的SVM 。存在的问题,其将关联规则挖掘与分类结合,先挖掘特征属性和类属性之间的关联规则,利用这些规则进行分类但其面临:规则表示,规则剪枝以及规则选择问题。
不平衡数据分类方法可以划分为三类:
1)数据层:在训练前采用重取采样技术重构数据集,降低不平衡度,包括过采样状语从句:欠采样。
2)算法层:针对不平衡数据特点构造新算法或改造现有算法,如单类学习状语从句:代价敏感学习。
3)混合方法:将两者结合起来,如集成学习方法。
集成学习方法来源于机器学习的研究。机器学习关注的一个基本问题就是算法的泛化能力(新数据上的处理能力),提高泛化能力是机器学习永远的追求。在面临不平衡数据时,由于基分类器仍然是由假设平衡的分类算法所产生,集成学习并不能直接应用于不平衡数据集,但是集成学习提供了一个统一的框架,即可以将数据层和算法层的方法结合起来, 。更好的处理不平衡数据分类问题目前用集成学习方法分类高维数据有以下几类方法:
1)先降维,再集成学习。是一种最简单的思路,利用降维技术降低数据数量,再采用集成学习方法提高准确率的本质特征,提高分类的准确率。
2)先对集成构建的个体子集降维,最后集成投票。是对第一种方法的改进,由于子集的划分保证了多样性,不同子集上的降维结果将有所区别,在特征减少的同时,可以利用多个子集弥补由于降维效果不佳所带来的损失。
3)基于特征的集成学习。是一种融合降维和集成的方法。集成学习的有效前提基础是基分类器具有多样性和准确性.Boosting和装袋都是基于数据子集的划分。而基于特征的集成学习的思想在于基分类器的构成是在特征子集上,而非整个特征空间。
根据最终特征子集产生的不同方式,基于特征的集成学习方法可以分为两类:
1)基于随机的方式,以随机的方式产生特征子空间,如随机子空间算法,随机森林算法等;
2)基于选择的方式,采用一定原则从特征子空间中选择部分特征子空间集成。通常此类方法都与搜索方法相关,基于一定的度量原则或目标,利用搜索算法,从特征子空间中搜索符合要求的特征子空间集合,再构造集成分类器。
分析用于高维数据分类的两类集成学习算法可以发现,基于随机的方式的方法主要面临随机子空间中属性数的选择,而在随机森林中除此之外还需要确定树的数量。这两个参数的选择对于算法有一定的影响。基于选择的方式的方法面临两个问题:特征选择方法和搜索方法,即如何选择合适的特征子集,使得构造的集成学习方法算法具有多样性和准确性;选择何种搜索方法使得在有限时间和空间中获得最优特征子集。
基于特征的集成学习在特征子集上构造基分类器的方式降低特征维度,利用集成学习方式提高算法泛化能力,具有适合解决高维数据分类问题的特性。但集成学习在解决不平衡数据分类时,其本身并不具有独特性,集成学习的基分类器的产生仍然面临着传统分类算法在面对不平衡数据时所面临的问题。之所以将其用于不平衡数据分类,在于其提供了一个统一的算法框架,可以将常用的不平衡处理方法,如取样技术和代价敏感方法融合在集成学习算法中,在解决不平衡分类问题时,充分利用集成学习提高算法的泛化能力的特性,可构造出一系列的算法。
分类不平衡的数据的集成方法:
1)代价敏感集成:目前解决不平衡分类问题的代价敏感集成方法主要采用不同的方法更新的Adaboost算法的权重,使得算法对于不同的类别区别对待;
2)基于Boosting的数据预处理和集成学习:此类方法将取样技术嵌入到推进算法中,朝着小类的方向改变用于训练下一个分类器的数据分布;
3)基于Bagging的数据预处理和集成学习:装袋方法由于其简单性及具有较好的泛化能力,常常与预处理方法组合处理不平衡数据分类问题,采用这种方法的关键在于处理不平衡获得有效分类器的同时保证基分类器的多样性;
4)混合方法的数据预处理和集成学习:混合方法不同于前面两类方法之处是采用了双重混合,也就是将装袋和推进组合起来。
集成学习并非某一个算法,而是一系列的算法。通常集成学习分为两个步骤:构建和组合。第一步产生多个用于集成的基分类器,第二步在此基础上,组合基分类器的结果。根据产生基分类器的算法个数,集成学习可以分为同构集成学习和异构集成学习。同构集成学习采用单个分类器算法,有构建策略产生不同的基分类器;而异构集成学习(多分类器系统)则采用不同的分类算法,利用分类算法间的差异性获得不同的基分类器。一般意义上的集成学习是指同构集成学习。
根据不同构造方法,集成学习算法可分为以下四种:
1)基于数据样本的(Boosting,Bagging);
2)基于特征的(Random Subspace);
3)基于输出类别的(ECOC);
4)基于随机性的(神经网络,决策树)。
根据组合形式,集成学习算法分为组合全部基分类器的算法,选择性集成算法,而选择性集成算法主要由以下四类:
1)基于聚类的方法,将聚类算法应用于各基分类器的预测结果。每个基分类器对验证集中的各个实例军有一个预测结果,由此可获得一个T * N的矩阵,其中Ť为基分类器个数,N为验证集实例个数。把验证集矩阵作为聚类算法的输入数据,即可获得具有类似预测的基分类器聚类,根据聚类结果修剪基分类器集合,选择出具有代表性的基分类器;
2)基于排序的方法,是一种直观的方法,分为两个步骤,先基于某种衡量标准对基分类器排序,再采取适当的停止准则选取一定数量的基分类器;
3)基于选择的方法,根据是否采用统一模型对验证集中的所有个体进行预测,分为静态选择法和动态选择法,排序算法实际上是选择算法的一种。静态选择算法的特点是从已有基分类器中选择部分构建集成分类器,并用于预测验证集中的所有实例。动态选择法则是针对验证集的每个实例,动态选择合适的部分基分类器预测,即每个实例可能选择不同的基分类器组合;
4)基于优化的方法,其核心思想是对每个基分类器赋予一定的权重,采用优化算法获得最优权重向量,根据预设的阈值选择相应的基分类器。通常采用遗传算法(GA)优化基分类器权重,所不同的是采用的遗传算法编码方式。
基于集成特征选择的集成学习方法的关键是利用一定的度量获得选择的特征子空间集合。所以,此类算法的关键是特征子空间选择度量和获得方法的研究,而特征子空间选择度量的一个关键因素就是基分类器多样性的度量。
多样性度量方法主要分为两类:成对多样性度量,非成对多样性度量。
成对多样性度量有以下5种:相关性度量,Q统计量,评判间一致性K,不一致度量,双错度量。
成对非多样性度量主要由以下6种:熵度量,Kohavi-沃伯特方差,者间一致性度量,“困难”度量,泛化多样性,偶然错误多样性。
预处理高维不平衡数据
高维不平衡数据分类的解决思路有两种:预处理后再分类和直接分类,一般预处理方法又包括降维方法和取样方法。
降维方法
Filter特征选择方法的评估直接依赖于数据集本身,通常认为相关性较大的特征或特征子集可获得较高的分类准确率。常见的Filter特征选择评估方法有信息增益,类间距离,关联度和不一致度等。
Wrapper器特征选择的核心思想是:与学习算法无关的过滤特征评价与后续的分类算法产生较大的偏差不同的学习算法偏好不同的特征子集,特征选择后的特征子集最终将用于后续的学习算法,则该学习算法的性能就是最好的评估标准。选择不同的分类算法以及特征空间搜索策略,则可产生各种Wrapper特征选择算法,常见的搜索方式有最佳优先搜索,随机搜索和启发式搜索。
取样方法
根据其取样方向可以分为两类,过采样和欠采样。根据取样策略可分为随机取样和算法取样。
过取样:增加小类实例;
欠取样:减少大类实例;
随机取样:以随机的方式删除或增加实例;
算法取样:根据一定的原则取样,如删除靠近大类边界的实例或增加任意产生的小类样例等一般来说,算法取样会产生一定的导向性。
分类算法评价方法
传统的分类算法假定类别分布平衡。但真实数据常常出现类不平衡、类分布偏斜的情况。当处理类不平衡数据时,由于多数类占优势,分类边界偏置于优势数据,传统的分类算法将面临对少数类预测能力下降的问题,从而影响整体预测性能。因而,应用通常的Acc(准确率)或Err(错误率)可能会出现偏差。目前不平衡数据分类的算法的评价方法包括:正确率、错误率、召回率、F-measure、Gmean、AUC、ROC曲线、precision-recall曲线和cost曲线等。而混淆矩阵表达实例分布的分布情况,是计算分类器性能度量的基础。
基于随机森林的不平衡特征选择算法
不平衡数据特征选择
1)基于预报风险误差的EasyEnsemble算法PREE
EasyEnsemble算法分为两步:
a)欠采样,从大类数据中随机抽取多个与小类数据一致的实例子集,并与小类一起组成多个新的训练数据集用于训练分类器;
b)所有分类器通过AdaBoost算法集成为最终的分类器。
PREE算法也为两步:
a)使用EasyEnsemble算法建立分类模型;
b)利用分类器模型获得特征子集。
2)基于抽样集成的特征选择算法EFSBS
EFSBS的思路比较简单,算法有以下三个步骤:
a)欠采样,采用随机有放回方法从大类中产生多个与小类数量相等的数据子集,再与小类数据一起组成新的训练数据集;
b)通过FCBF特征选择算法获得特征子集;
c)对产生的特征子集多数投票,获得最终的特征子集。
PREE和EFSBS共同之处在于都采用了集成学习算法,利用欠采样方法先平衡数据集。区别在于PREE算法严格意义应属于Wrapper方法,利用了集成学习算法的分类效果进行特征选择,EFSBS则属于Filter方法,在特征子集的选择上没有利用来自于分类算法的反馈。
随机森林变量选择
随机森林变量选择(RVS)是随机森林的一种隐式特征选择方法。当一个重要特征(对预测准确率有贡献)出现噪声时,预测的准确率应该会明显减少,若此特征是不相关特征,则其出现噪声对预测准确率的影响应该不大。基于这一思想,利用袋外数据(Out of Bag Data)预测随机森林性能时,若想知道某特征的重要程度,只需随机修改该特征数值,而保持其他特征不变,由此获得的袋外数据预测准确率与原始袋外数据预测准确率之差体现了该特征的重要程度其具体过程如下:
对于每个自举数据集袋内数据(InOfBagi),构建决策树Treei
1)确认袋外数据OutOfBagi;
2)同Treei预测OutOfBagi中实例的类标号,计算正确预测次数Sumoutofbagi;
3)对于每个随机变量FJ(J = 1 ... M):
对于特征Ĵ,先计算所有所有原始袋外数据预测正确率与改变特征Ĵ值后袋外数据的正确预测率之差,其在所有树上的平均值即代表了特征Ĵ的变量重要性。一个)对OutOfBagi中的特征FJ的值随机排序,获得变化后的袋外数据集OutOfBagCij;
B)用Treei对OutOfBagCij中的实例进行预测,计算正确预测次数Sumoutofbagcij;
C)用原始OutOfBag正确预测次数减去改变特征Ĵ值后的袋外数据的正确预测次数。
随机森林变量选择方法实际上也是一种嵌入式的特征选择算法,充分利用了集成分类器构建过程所产生的分类模型。与PREE不同之处在于,PREE利用的是在特定特征上的结构风险变化,PREE在计算特定特征的AUC时,采用的是取特征平均值的方式;而随机森林变量选择方法基于的是无关特征对模型性能影响不大的思想,通过施加干扰来测试特征的准确程度,且这种方法乐意同时处理离散型和连续性数据,弥补了PREE的缺陷。
不平衡随机森林变量选择算法
高维数据处理的一种有效途径即通过特征选择降低特征数,而不平衡数据处理的有效途径是通过取样方法平衡数据。随机森林的两个步骤综合了此两项机制。不平衡随机森林变量选择算法(BRFVS)受随机森林算法启发,利用随机森林的构造过程,对不平衡数据集进行特征选择。
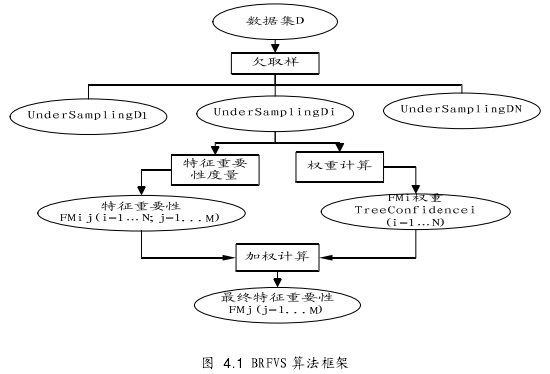
在随机子空间上构造决策树,是一种缩小特征空间的有效办法,而决策树算法计算分裂属性的过程也就是一个属性选择的过程,可以直接利用此过程选择重要特征。在每个UndeSamplingD数据集上都可以构造一棵在随机子空间中产生的决策树,也即获得一个特征重要性度量。N个UndeSamplingD可以获得N个特征重要性度量。这些特征重要性度量体现了各特征在不同UndeSamplingD数据集上的重要程度。但是每个UndeSamplingD所获得特征重要性度量的可信度是不一样的,在此体现为权重,也即可信度越高,所赋予的权重越高。
特征重要性度量
BRFVS采用RVS来计算特征重要性度量值.RVS中特征重要性度量的计算是基于袋外数据样本的。基于袋外数据样本测试算法性能或计算算法参数是当前常用的一种方法。这种方法的好处是可以减少计算时间。但在BRFVS中,由于采用的欠采样方法平衡数据集中的类别,如果按照袋外数据样本的获取方法,则会导致出现袋外数据的大类数据过多。因此,BRFVS采用ķ层交叉验证的方法来获取特征重要性度量。
权重计算方法
当大类数据和小类数据严重不平衡时,对大类数据欠采样时可能会产生差异性较大的UndeSamplingD数据子集。在此数据子集上建立的树的准确率也将有所区别。实际上,由于UndeSamplingD的多样性,其准确性是不同的.BRFVS算法认为最终集成判定一致度高的基决策树应该具有更高的权重,其所获得的特征重要性度量值具有更好的可信度。
基于随机森林的高维不平衡分类算法
分类高维不平衡数据的方法有两种:预处理再分类和直接分类。尽管预处理后能够达到一定的分类效果,但是由于预处理后获得的结果是单个数据集,也就是说最终用于分类的数据集将损失一部分特征和实例信息。直接分类则是在分类时充分考虑数据的高维和不平衡特性,使算法在面临此类数据时,能够有较好的性能。
有关集成学习解决不平衡数据分类问题的综述中,代价敏感集成学习是一种不平衡数据分类算法。大部分的代价敏感集成方法主要是与Boosting相结合,通过在AdaBoost的权重更新公式中引入不同代价,修改权重更新公式,使之能够有效处理不平衡问题。但是Boosting算法每次建树时都是考虑整个特征空间,不利于高维数据的处理。
针对不平衡数据分类问题,有人提出平衡随机森林算法(BRF)和权重随机森林(WRF):
研究表明,对于树分类器而言,通过欠采样或过采样的方式人为地使数据平衡是一种有效解决不平衡数据分类问题的方式。欠取样看起来优于过取样,但是欠取样大类也可能会导致信息丢失,通过集成的方式可以弥补这一点。
BRF算法的思想的来源于此,算法步骤如下:
1)对随机森林中的每一轮迭代从小类中抽取Bootstrap样本。从大类中,以有放回的方式随机抽取同样数量的实例;
2)从产生的数据中以不剪枝的方式产生决策树。树产生算法为CART算法。但对CART算法修改如下:在每个节点上,不是在所有特征中搜索最优分裂,仅在固定的随机选择的特征中搜索最优分裂;
3)按照指定次数重复上述两个步骤,集成预测结果获得最终的预测。
由于RF分类器偏向于大类准确,WRF对误分类小类设置更重的惩罚。WRF给每个类别分配一个权重,小类赋予更大的权重。类权重以两种方式整合在RF算法中,WRF算法步骤如下:
1)树的构建过程中,在计算分类的Gini系数中加入类权重;
2)每棵树的终端结点上,每个端点类别的预测采取有权重的投票方式决定。例如,一个类别的权重投票使用该类别的权重乘以终端结点上的实例数。
RF的最终预测是由来自各个树的带权重投票集成,权重是终端结点的平均权重。类权重本质上而言就是通过参数调整来达到理想的性能。权重可以通过袋外数据(Out-of-Bag)来估计获得。WRF设置大类和小类的初始权重均为0.5,通过调整权重,获得ROC曲线,确定最优权重设置。
实验显示,BRF和WRF相比于之前的一些经典算法而言,具有更好的性能。但BRF和WRF之间性能不相上下。BRF虽平衡了数据,但是改变了数据分布,可能会引入数据的不确定性;WRF赋予小类更多权重的同时,可能使得算法在面临噪声时更为脆弱。,隐蔽有人提出了一个融合BRF和WRF的改进的平衡随机森林算法(IBRF)。IBRF算法在欠采样时,并非取与小类实例数量相等的固定数量的实例,而是引入区间参数,使得小类和大类的取样数量可以根据需要调整。IBRF算法描述如下:
输入:训练数据{(x1,y1),...,(xn,yn)},区间变量m和d,树的数量ntree;
过程如下:
For t=1,...,ntree,
1)在区间m-d/2和m+d/2间产生变量a;
2)以有放回形式随机从负类训练数据集D-中抽取na个实例,从正类训练数据集D+中抽取n(1-a)个实例;
3)分配权重w1给负类,w2给正类,其中w1=1-a,w2=a;
4)产生不剪枝的分类决策树;
输出:最终排名。计算每个测试实例的负例得分,即预测为负类的树的数量,越多树将该实例预测为负类,该实例所获得的负例得分就越高。对所有实例的负例得分排序获得最终序列。
变量a直接决定了每轮迭代中负例和正例训练实例的平衡程度。a越大,意味着训练实例中负类的实例越多,也意味着赋予负类的权重越大。
代价敏感方法
代价敏感(Cost-Sensitive Learning,CSL)学习最初来源于医疗诊断中,将有病的病人诊断为无病所付出的代价将远大于将无病的人诊断为有病病人。也就是说错误分类的代价是不等的。代价敏感方法被提出用于解决占据少数类别,但其误判影响较大的问题。
代价是代价敏感学习的基础,在数据挖掘中,将代价分为测试代价和误分类代价。测试代价是指获得测试属性所需要的代价。误分类代价是指将训练数据实例错误分类所造成的损失。
针对二元分类问题,假设正类(+)表示少数类,负类(-)表示多数类。一个实例本应属于j,但被错误分为i,C(i,j)表示将j错误分为i的代价。代价矩阵定义如下:

假设正确分类没有代价,则代价矩阵可以描述为代价率:
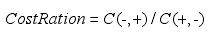
代价敏感分类的目的就是以最小误分类代价建立模型:
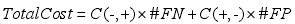
其中#FN 和#FP 表示假负和假正实例数。
集成学习中的代价
在用集成学习解决不平衡分类问题中,代价敏感AdaBoost算法是一种主要的方式。代价敏感AdaBoost通过修改AdaBoost的权重以及分布更新公式,使得来自不同类别的实例被区别对待。
AdaBoosting是一个串行算法,通过逐步调整实例分布,使得分类倾向于难分的实例。再集成所有分类器,形成集成学习算法。AdaBoost算法涉及两个参数:at和Dt(i)。at是指每个分类器的权重,Dt(i)是指t轮时实例i的权重。

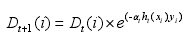
在AdaCost中,权重更新公式增加了一个代价调整函数。对于一个具有更高代价因子的实例,如果这个实力被误分类,则增加更多权重,但是如果没有被误分类,则减少相应的权重。AdaBoost的权重函数和at的计算公式被替换为:
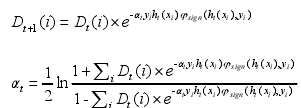
代价敏感随机森林算法
尽管代价敏感学习已经被引入到集成学习中,但是现有的代价敏感方法大多是与Boosting算法结合,在分类高维数据时不能取得较好的性能。随机森林本身适合于处理高维数据,如果在随机森林中引入代价因子,则可同时处理高维不平衡数据分类。之前的BRF和WRF为代价敏感随机森林算法(CSRF)设计提供了启发。之前方法在决策树中引入的代价多是误分类代价,而CSRF则综合考虑了误分类代价和测试代价两种代价的影响。
随机森林是一个两阶段的过程:
1)通过Bagging方法获得多个Bootstrap训练集用于产生基分类器;
2)在产生的训练数据集上,用分类回归树(CART)算法产生不剪枝的决策树。
决策树的每个结点的分裂属性不是在整个特征空间计算,而是固定一个属性特征数量K,每次分裂时,从特征集中随机有放回地抽取K个属性,在此K个属性上计算最佳分裂属性。
CART决策树是一个二元递归划分过程,可用于处理分类问题也可以处理回归问题。每一个结点均划分为两个分支,分裂属性的计算原则采用Gini指数。但Gini指数中只考虑了误分类代价,而未考虑测试代价。CSRF算法借鉴了EG2算法的思想,EG2算法是在C4.5的基础上,修改了属性分裂度量,使用信息代价函数(ICF)作为分裂准则,这一准则同时权衡了信息增益和测试代价两方面的信息。
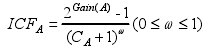
其中Gain(A)代表属性A的信息增益,CA代表属性A的测试代价,参数用于调整信息代价大小。将信息增益修改为Gini系数,则使得分裂属性的计算综合考虑测试代价和误分类代价。
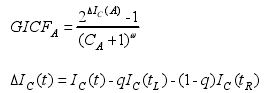
当w取值为0的时候,属性分裂度量与测试代价无关。
代价敏感算法通常以最小化误分类代价为目标,由于在算法中引入了测试代价,因此,总体代价表示为:
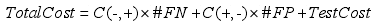
也就是说评价函数由最小化误分类代价转化最小化误分类代价和测试代价之和,其中TestCost为测试代价。
CSRF算法描述:
CSRF通过对随机森林中产生决策树的CART算法进行修正,使其对不平衡数据能够区别对待。代价引入主要体现在两个方面:属性分裂和算法评价。在CSRF中的测试代价与分类类别相关,测试代价是一个预设的数值,该数值通过计算该属性与类别的相关性而获得,也就是说如果某一属性与某一类别的相关性大,则认为在当前属性上分裂的测试代价更小。
CSRF具体步骤如下:
1)通过Bagging方法获得Boostrap数据集;
2)建立不剪枝的CART决策树,修改CART决策树的属性分裂计算方法。这里误分类代价采用固定数值。还需要确定的就是参数w,w用于调节测试代价的影响能力,CSRF用袋外数据测试,w的初值为0,取0.1为步长,以总体代价为评价标准,获得总体代价最小的w值作为最终的模型参数值。为了简化问题,每个CART树的w取值都相同。由于在不平衡数据中,期望给予小类更多地关注,因此,确定测试代价时,仅考虑属性和小类的相关性,相关性大则测试代价小,反之则大。采用Gini系数计算各属性与小类的相关性。
基于集成特征选择的高维不平衡数据分类算法
集成学习算法有效的前提是基分类器多样且准确。随机森林本身的机制就可以达到保证多样性和准确性的双重效果,能够较准确的处理高维数据,直接在其中引入倾向于小类的代价,就可以达到平衡小类和大类的效果。
集成特征选择不同于随机森林,是一种基于选择特征的集成学习方法。采用特征选择算法分类高维不平衡数据时,需要兼顾多样性、准确性和不平衡性。 思路与前一章类似,本文设计了一个新集成特征选择算法IEFS,在特征子集评价函数中引入代价,代价以权重体现,增加了奖惩因子。在子集搜索过程中,小类上的分类准确率得以提升则给予奖励,小类上的分类准确率下降则给予惩罚。
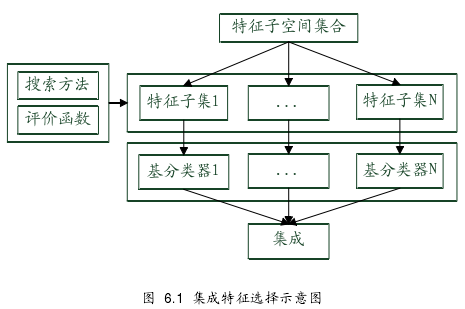
集成特征选择
基于特征选择的集成分类也称为集成特征选择方法。集成特征选择方法可以描述为:将数据集中的不同特征分别进行分割,在不同的特征子集上构建不同分分类器。集成特征选择不同于传统的特征选择方法,传统的特征选择方法是按照某一个准则选择一组最优或近似最优的特征。而集成特征选择方法的目标不是选择某一个最优或近似最优的特征子集,而是以构建的基分类器具有高精度且分类器间具有分类错误多样性为目标,选择划分特征子集的方法。多样性和准确性往往是两个矛盾的目标,因此集成特征选择算法的核心目标是平衡多样性和准确性,而并非寻找具有最优识别精度的特征子集。
一个集成特征选择算法包含三个步骤:1)特征子集的选择;2)产生基分类器;3)集成预测结果。其中特征子集的选择是一个搜索过程,搜索目标函数用于评价特征子集,假设有M个属性,则属性组合的搜索空间为2的M次方。特征子集的选择本质上就是在搜索空间中搜索满足目标函数的特征子集的集合。目标函数决定了搜索收敛的方向,搜索方法决定了搜索的质量。
常用目标函数
最初,基于特征选择的集成学习方法是为了扩展集成学习基分类器的产生方式而提出,以最小化泛化错误率为目标。即选择预测错误率最小的特征子集的组合。
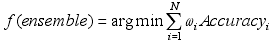
随后,研究发现,集成错误由两个部分组成:基分类器的泛化错误和基分类器的不一致程度。于是,Opitz提出集成特征选择的概念,用标准遗传算法搜索构建集成的特征子集,将遗传算法的适应值函数定义为:
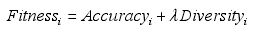
Fitnessi代表第i个种群的适应值。准确率Accuracyi指所有基分类器在测试集上正确分类率的平均值。
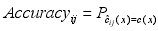
Accuracyij是指第i个种群中第j个基分类器的预测准确率。cij(x)基分类器j预测x的类标号,c(x)是测试集的原始类标号。多样性Diversityi定义为第i种群中,基分类器与集成预测结果的差距的平均值。通过加权平均平衡准确率和多样性。
搜索方法
在集成特征选择中除了考虑目标函数,采用的搜索算法也是其中一个关键因素。目前在集成特征选择中常用的搜索方法有:爬山法(HC)、遗传算法(GA)等。
集成特征选择中关注搜索性能的相关研究以遗传算法为基础算法,通过研究搜索算法,力求获得最优解。但由于遗传算法的时间开销大,关注目标函数的研究通常采用爬山搜索作为搜索方法。
兼顾不平衡性的集成特征选择算法
本文修改了Optiz提出的目标函数,使其在特征子集的搜索过程中更倾向于小类准确,采用爬山搜索特征空间,提出了兼顾不平衡性的集成特征选择算法(IEFS)。
IEFS的特征子集评价函数仍然由两个部分组成:准确率和多样性。
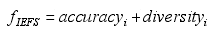
由于数据的不平衡性,采用准确率度量基分类器的预测性能将倾向于大类准确。因此,在IEFS中,准确率采用F-measure度量。
IEFS的多样性度量采用KW方差多样性度量。一个好的集成的基分类器应该尽可能准确且多样。集成目标f IEFS中,准确率越大,意味着基分类器越准确;多样性越大,意味着基分类的预测越不一致。IEFS在准确率的度量中采用了倾向于小类的F度量。同时修改了KW方差多样性度量。基分类器的多样性度量越大意味着可能产生更好的集成,也意味着基分类器选择的特征子集是合适的。在KW多样性度量中,当基分类器的预测越一致,则KW的取值越小,代表基分类器的预测多样性越小。
IEFS在多样性的度量中引入不平衡因素,即在小类实例上预测越不一致,则增加其多样性计算值。当小类预测不准确时,予以惩罚,减少多样性度量值,使得不能使小类分类正确的基分类器被抛弃,则可增加小类的分类准确率。
为测试此多样性度量的有效性,集成选择的目标函数仅考虑准确率和多样性的简单求和。
总结部分:
不论是高维数据还是不平衡数据,可以都预处理再分类。
降维是常用的高维预处理方法,包括特征选择和特征变换;不平衡数据的预处理方法主要是取样技术,包括欠采样和过采样;预处理可以减少分类时间,但会损失特征或实例信息,预处理不准确将导致分类不准确。
直接分类高维数据的算法较少,基于特征的集成学习是其中的一种;直接分类不平衡数据的算法有三类:代价敏感算法,单一分类算法和集成学习。
注意:其中集成学习算法大都是在推进算法中引入代价或结合取样方法处理不平衡数据当数据展现高维和不平衡双重性时,现有方法无法获得较好的性能但从现有方法中可以发现,集成学习是两类数据分类方法的交集。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号