

mysql基础知识点二-mysql sql优化
mysql基础知识点二-mysql sql优化
1.mysql的explain

解释常见的列以及其作用
1. id,代表执行顺序,越大优先级越高,相同,从上到下,若为null最后执行
2. select_type代表查询类型
simple: 简单查询,就是一个select * form table
primary: 复杂查询最外层的select,比如 select * from (select * from table);第一个select
subquery: select中子查询 select (select * from table from table,括号里那个就是子查询;
derived: from中的子查询 select * form table where a = (select * from table),where中的那个查询就是子查询
union: 并查询(我的叫法) select 1 union select 1;后面那个select就是union
3. table: 表示正在查询的表,注意deriven3代表表用的是id=3的查询
4. type(重要): 代表索引使用的情况,一般分为system>const>eq_ref>ref>range>index>all
正常情况下要求达到range,最好ref,这是主要的sql优化点,这里涉及到索引的建立和使用,下面详细说 5. possible_keys: 代表查询可能会用这一列,但实际上索引优化器不一定会用
6. key: 实际使用的索引,可以强制使用索引列或者不用 force index、ignore index
7. ken_len: 索引的长度,这里有一个长度,不过没啥太大用,不用掌握这么深
key_len计算规则如下:
字符串,char(n)和varchar(n),5.0.3以后版本中,n均代 表字符数,而不是字节数,如果是utf-8,一个数字 或字母占1个字节,一个汉字占3个字节 char(n):如 果存汉字长度就是 3n 字节
varchar(n):如果存汉字则长度是 3n + 2 字节,加的2字节 用来存储字符串长度,因为 varchar是变长字符串 数值类型tinyint:1字节 smallint:2字节 int:4字节 bigint:8字节 时间类型date:3字节
timestamp:4字节
datetime:8字节 如果字段允许为 NULL,需要1字节记录是否 为 NULL 索引最大长度是768字节,当字符串过长时,mysql会做一个类似左前缀索引的处理,将前半部 分的字符提取出来做索 引
8. ref: 查值用的列或者常量,如const
9. rows: mysql估计检测的行数,实际检测行数是rows*filtered/100
10.extra: 额外信息,如下
using index:覆盖索引(不用回表)
using where:用了where,但查询列未被索引覆盖
using index condition:用了索引
using temporary: 用了临时表,基本上需要这个字段加索 引,避免用临时表
using filesort: 用了外部排序,数据小,内存排序,数据 大,裁判排序,而不是索引排序,尽量优化成索引排序
select table optimized away: 在索引字段上用了聚合函 数。
2.索引使用
-
建表
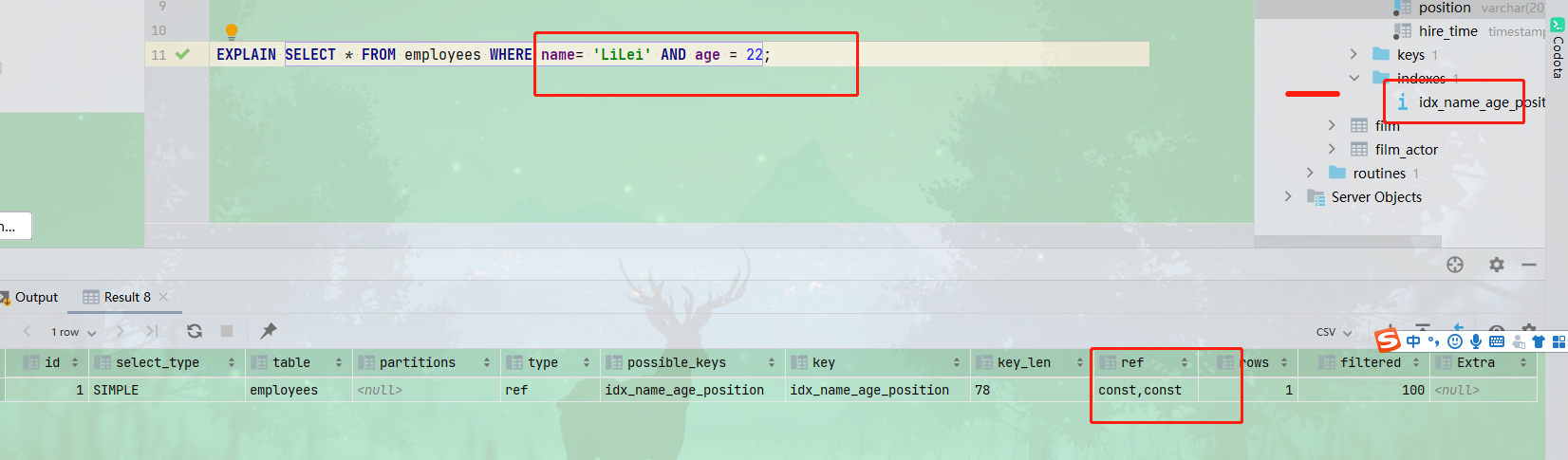
CREATE TABLE `employees` ( `id` int NOT NULL AUTO_INCREMENT, `name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名', `age` int NOT NULL DEFAULT '0' COMMENT '年龄', `position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位', `hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间', PRIMARY KEY (`id`), KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=100007 DEFAULT CHARSET=utf8mb3 COMMENT='员工记录表';- 本表只建立一个联合索引,下面这个查询,使用了联合索引的第一列,并且是ref级别,因为联合索引是多个单个索引组合在一起,如果单独使用,第一个索引列可以看做普通的二级索引,当然也可以看做使用了联合索引。

3. 使用联合索引要遵循最左前缀,也就是要按照建立联合索引的顺序去使用索引
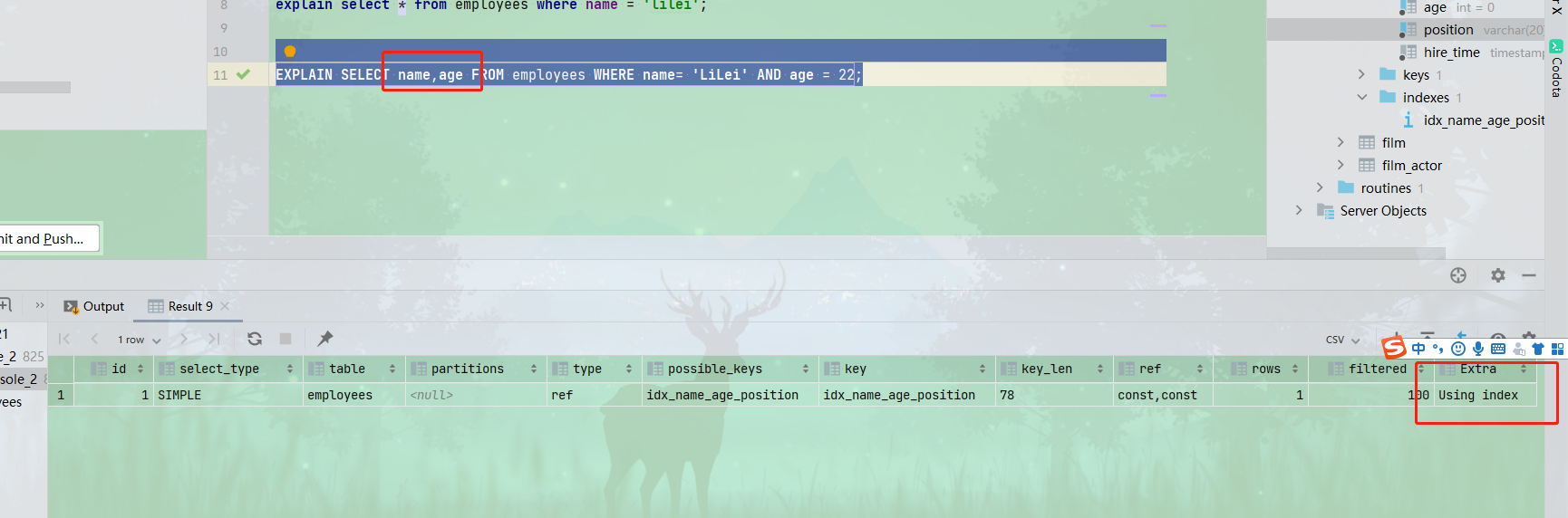
4. 覆盖索引,查询结果集完全在索引列上,不需要回表,看extra列,覆盖索引,这就是为啥不推荐用 select * from table
-
说几个会索引失效的场景
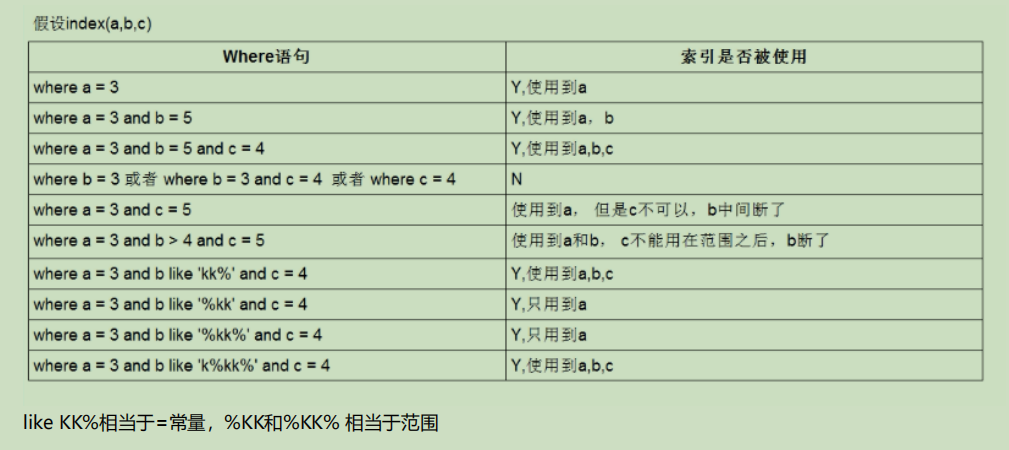
**不等于(!=或者<>),****not in** **,****not exists** **的时候无法使用索引会导致全表扫描** **<** **小于、** **>** **大于、** **<=****、****>=** **这些,mysql内部优化器会根据检索比例、表大小等多个因素整体评估是否使用索引** 字符串不加单引号索引失效 少用or或in,用它查询时,mysql不一定使用索引,mysql内部优化器会根据检索比例、表大小等多个因素整体评 估是否使用索引,如下面这个例子 ALTER TABLE `employees` ADD INDEX `idx_age` (`age`) USING BTREE ; explain select * from employees where age >=1 and age <=2000; 没走索引原因:mysql内部优化器会根据检索比例、表大小等多个因素整体评估是否使用索引。比如这个例子,可能是 由于单次数据量查询过大导致优化器最终选择不走索引 优化方法:可以将大的范围拆分成多个小范围,比如下面这种 explain select * from employees where age >=1 and age <=1000; explain select * from employees where age >=1001 and age <=2000;- 看下面这个例子,联合索引a,b,c各种情况理论下是否使用,但是实际上索引的使用和索引优化器有关 ,索引优化器又会根据扫描行数等各种原因决定是否使用索引。
不恋尘世浮华,不写红尘纷扰


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
2021-01-18 多线程知识点大纲
2021-01-18 服务器consul启动方法
2021-01-18 Lc160_相交链表
2021-01-18 Lc136_只出现一次的数字