

一、什么是数据库?
1.什么是数据库
概念
数据仓库(软件),安装在操作系统(window,Linux,mac…)之上。可以存储大量数据。500万
作用:
数据库是存储数据,管理数据,
2.为什么要学习数据库
- 趋势,岗位需求
- 大数据时代,得数据者得天下
- 被迫需求:存数据
- 数据库是所有软件体系中最核心得存在
3.数据库分类
关系型数据库:(SQL)
- MySQL、Oracle、SQL server、DB2、SQLlite…
- 通过表与表之间、行与行之间的关系进行数据的存储。
非关系型数据库:(NoSQL)Not Only SQL - redis、MongDB
- 对象存储,通过对象自身的属性来决定。
4.DBMS(DataBaseManagementSystem)
- 数据库的管理软件,管理我们的数据,可以维护和获取我们的数据。
- MySQL,数据库管理系统。
二、MySQL属性和操作
1.常用密令
show create database user; --查看创建数据库user的语句show create table user; --查看创建数据表user的语句desc user; --查看数据表user的结构
mysql的关键字不区分字母的大小写
2.操作数据库。数据库名:demo
- 创建数据库
create database [if not exists] demo;
- 删除数据库
drop database [if exists] demo;
- 使用数据库
use `demo`; --tab键上面,如果表名或者字段名是一个特殊字符,就需要使用``
- 查看数据库
show databases; --查看所有数据库
3.数据库列的类型
mysql数据类型长度问题总结:https://blog.csdn.net/yaruli/article/details/79187814
- 数值
- tinyint:十分小的数据,1个字节。
- smallint:较小的数据,2个字节。
- mediumint:中等大小的数据,3个字节。
- int:标准的证书,4个字节。(常用的变量)
- bigint:较大的数据,8个字节。
- float:浮点数,4个字节。
- double:浮点数,8个字节。
- decimal:字符串形式的浮点数。涉及到金钱计算时,一般使用decimal
- 字符串
- char:字符串固定大小的,0~255字节。
- varchar:可变字符串,0~65535字节。(常用的变量)
- tinytext:微型文本,2^8-1字节。
- text:文本串,2^16-1字节。
- 时间
- date:YYYY-MM-DD,日期格式。
- time:HH:mm:ss,时间格式。
- datatime:YYYY-MM-DD HH:mm:ss,最常用的时间格式。
- timestamp:时间戳,1970.1.1道现在的毫秒数。
- year:年份表示。
- null
- 没有值,未知。
- 注意:不要使用NULL进行运算,没有意义,计算结果为NULL
4.数据库的字段属性
- Unsigned
- 无符号的整数。
- 声明了该列不能为负数。
- zerofill
- 0填充
- 不足的位数使用0填充。int(5)类型存储数字9会变成00009
- 自增
- 通常理解为自增,自动在上一条记录的基础上+1(默认)。
- 通常用来设计唯一的主键,必须是整数类型。
- 可以自定义设计主键自增的起始值和步长。
- 非空
- 勾选上not null,如果不给字段赋值,则会报错。
- 默认
- 设置默认的值。
- sex,默认值为男,如果不指定该列的值,则会有默认的值。
5.创建数据库
- 注意点,使用英文(),表的名称和字段尽量使用``括起来。
- AUTO_INCREMENT 自增。
- 字符串使用单引号括起来。
- 所有的语句后面加,(英文的),最后一个不用加。
-
PRIMARY KEY主键,一般一个表只有一个唯一的主键。
CREATE TABLE IF NOT EXISTS `student`(`id` INT(4) NOT NULL AUTO_INCREMENT COMMENT '学号',`name` VARCHAR(30) NOT NULL DEFAULT '匿名' COMMENT '姓名',`pwd` VARCHAR(20)NOT NULL DEFAULT'123456' COMMENT '密码',`sex` VARCHAR(2) NOT NULL DEFAULT '女' COMMENT '性别',`birthday` DATETIME DEFAULT NULL COMMENT '出生日期',`address` VARCHAR(100) DEFAULT NULL COMMENT '家庭住址',`email` VARCHAR(50) DEFAULTI NULL COMMENT '邮箱’,PRIMARY KEY('id'))ENGINE=INNODB DEFAULT CHARSET=utf8
-
格式:
CREATE TABLE [IF NOT EXISTS] 表名('字段名' 列类型[属性][索引][注释],'字段名' 列类型[属性][索引][注释],......'字段名'列类型[属性][索引][注释])[表类型][字符集设置][注释]
6.数据表类型
-
关于数据库引擎
- InnoDB:5.5版本以后默认使用。
-
MyISam:早些年使用的默认。
| | MyISam | InnoDB |
| —————— | —————— | —————— |
| 事务支持 | 不支持 | 支持 |
| 数据行锁定| 不支持 | 支持 |
| 外键约束| 不支持 | 支持 |
| 全文索引| 支持 | 不支持 |
| 表空间大小| 较小 |较大,约为myisam两倍 |
常规使用操作:- MYISAM节约空间,速度较快。
- INNODB安全性高,事务的处理,多表多用户操作。
-
在物理空间参在的位置
所有的数据库文件都存在data目录下,一个文件夹就对应一个数据库本质还是文件的存储。 -
MySQL引擎在物理文件上的区别。
- InnoDB在数据库表中只有一个*.frm文件,以及上级目录下的ibdata1文件。
- MYISAM对应文件:
- *.frm:表结构的定义文件
- *.MYD:数据文件(data)
- *.MYI:索引文件(index)
7.设置数据库表的字符集编码
MySQL默认字符编码的设置:https://www.jianshu.com/p/ec0c86ee3e04
charset=utf8
- 不设置的话,会是mysql默认的字符集编码(不支持中文)
- MySQL的默认编码是Latin1,不支持中文。
- 在my.ini中配置默认的编码
character-set-server=utf8
8.修改数据表字段
-- 修改表名:alter table 旧表名 rename as 新表名alter table `teacher` rename as `teacher1`-- 增加表的字段:alter table 表名 add 字段名 列属性alter table `teacher1` add age int(11)-- 修改表的字段:alter table 表名 modify 字段名 列属性[]alter table `teacher1` modify age varchar(11)-- 字段重命名:alter table 表名 change 旧字段名 新字段名 列属性[]alter table `teacher1` change age int(1)
change一般用来字段重命名,modify不用来字段重命名,只能修改字段类型和约束
9.删除数据表字段
-- 删除表(如果表存在再删除)drop table if exists `teacher1`
三、MySQL数据管理
1.外键(了解)
方式一:在创建表的时候添加外键。
方式二:在创建表的时候没有外键,修改表添加外键
-- alter table 表名 add constraint 约束名 foreign key(作为外键的列) references 哪个表(哪个字段)alter table `student` add constraint `FK_gradeid` foreign key(`gradeid`) references grade(`gradeid`);
删除外键关系的表的时候,必须要先删除引用别人的表(从表student),再删除被引用的表(主表grade)。
以上操作都是物理外键,数据库级别的外键,我们不建议使用!
2.DML语言(全部记住)
-
添加
-- 插入语句一定要数据和字段一一对应:insert into 表名([字段1,字段2,...])values('值1','值2',...)insert into `student`(id,name,age)values(1,'zhangsan',12);
-
修改
-- 不指定条件的情况下,会修改所有的记录:update 表名 set column_name=value,[column_name=value,...] where [条件]update `student` set name='张三' where id=1;
-
删除
-- 不指定条件的情况下,会删除所有的记录:delete from 表名delete from `student` where id=1;-- 清空整张表truncate table `student`;
- delete和truncate区别
相同点:都能删除数据,都不会删除表结构。
不同点:- truncate重新设置自增列,自增计数器会归零。
- truncate不会影响事务。
- delete删除不会重新设置自增列。
- delete删除的问题,重启数据库(了解即可)
- InnoDB:自增列会从1开始(存在内存中的,断电即失)
- MyISAM:继续从上一个自增量开始(存在文件中的,不会丢失)
四、DQL查询数据(全部记住,最重点)
1.指定查询字段
-- 函数:concat(a,b)select concat('姓名:',studentName) as '新名字' from student;
2.去重
-- 去除select查询结果中重复的数据,重复的数据只显示一条select distinct `studentNo` from `result`;
3.数据库的列(表达式)
-- 查询数据库版本select version();-- 查询计算表达式select 100*3-1 as 计算结果;-- 查询自增的步长select @@auto_increment_increment;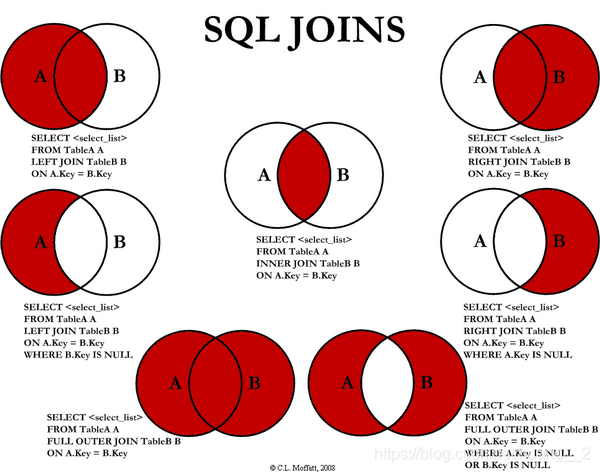-- 数据库中的表达式:文本值,列,null,函数,计算表达式,系统变量...select 表达式 from 表名;
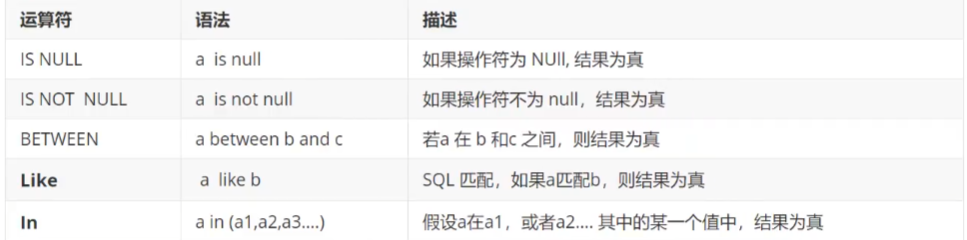
4.where条件子句
作用:检索数据中符合条件的值。
逻辑运算符
| 运算符 | 语法 | 描述 |
|---|---|---|
| and && | a and b,a&&b | 逻辑与,两个都为真,结果为真 |
| or | a or b | 逻辑或,其中一个为真,结果为真 |
| not ! | not a,!a | 逻辑非,真为假,假为真 |
5.模糊查询
6.联表查询
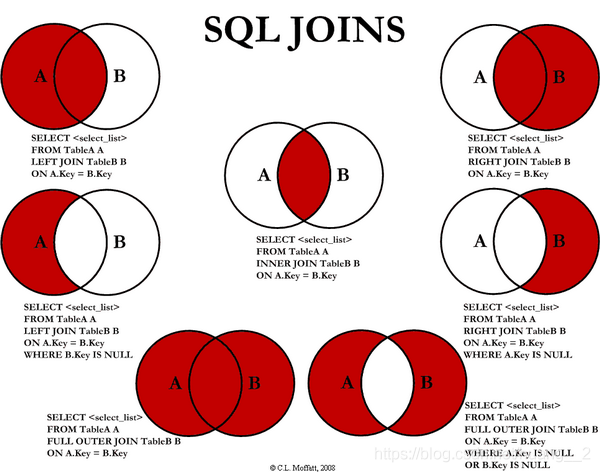
| left join | 会从左表中返回所有的值,即使右表中没有匹配 |
|---|---|
| right jion | 会从右表中返回所有的值,即使左表中没有匹配 |
| inner join | 如果表中至少有一个匹配,就返回行 |
自连接
自连接:自己的表和自己的表连接
核心:一张表拆为两张一样的表即可
7.排序
- ASC:升序,从小到大排序
- DESC:降序,从大到小排序
8.分页
为什么分页?
- 缓解数据库压力
- 给人的体验更好
# 第一页limit 0,5# 第二页limit 5,5# 第三页limit 10,5# 第N页limit (n-1)*pageSize,pageSizelimit 起始值,每页显示条数-----------------------------# pageSize:每页显示数据条数# (n-1)*pageSize:起始值# n:当前页# 总页数:数据总数/页面显示条数
9.子查询
本质:在where语句中嵌套一个子查询语句
select * from user where id = (select id from grade);
10.分组过滤
group by...having
五、MySQL函数
1.常用函数
-
数学函数
select ABS(-8) # 绝对值select ceiling(9.4) # 向上取整select floor(9.4) # 向下取整select rand() # 返回一个0~1之间的随机数selec sign(-10) #判断一个数的符号。 0返回0,负数返回-1,正数返回1
-
字符串函数
select char_length('我爱你') # 返回字符串的长度select concat('我','爱','你') # 拼接字符串select insert("我爱编程",1,2,'超级热爱') # 查询,从某个位置开始替换某个长度select upper('wo') # 转大写字母select lower('WO') # 转小写字母select instr('sunyiwenlong','y') # 返回第一次出现的索引,索引从1开始select replace('坚持就能成功','坚持','努力') # 替换出现的指定字符串select substr('我们都一样',2,4) # 从第二个开始截取4个。结果是‘们都一’select reverse('hello') # 反转字符串
-
时间和日期
select current_date() # 获取当前日期select now() # 获取当前时间select localtime() # 获取本地时间select sysdate() # 获取系统时间
-
系统
select system_user() # 获取系统当前登录用户(mysql登录用户)select user() # 获取系统当前登录用户的简写select version() # 获取系统版本
2.聚合函数
| 函数名称 | 描述 |
|---|---|
| COUNT() | 计数 |
| SUM() | 求和 |
| AVG() | 平均值 |
| MAX() | 最大值 |
| MIN() | 最小值 |
| … | … |
考题:区别
select count(name) from student # count(字段) :会忽略所有的null值
select count() from student # count() :不会忽略null,本质是计算行数
select count(1) from student # count(1) :不会忽略null,本质是计算行数
六、事务
事务原则:ACID原则,原子性、一致性、隔离性、持久性。
七、索引
http://blog.codinglabs.org/articles/theory-of-mysql-index.html
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。
提取句子主干,就可以得到索引的本质:索引是数据结构。
1.索引的分类
- 主键索引(primary key):唯一的标识,主键不可重复,只能有一个列作为主键。
- 唯一索引(unique key):避免重复的列出现,唯一索引可以重复,多个列都可以标识位,唯一索引。
- 常规索引(key/index):默认的,index。key关键字来设置。
- 全文索引(fulltext):在特定的数据库引擎下才有,myisam,快速定位数据。
# 显示一张表的所有的索引信息show index from student;# 增加一个全文索引。索引名(列名)alter table student add fulltext index 'studentName'('studentName')create index 索引名 on 表(字段)
2.测试索引
# 插入100万数据delimiter $$ # 写函数之前必须要写的,标志create function mock_data() # 创建一个函数returns int # 返回值类型begindeclare num int default 1000000; # 声明一个变量declare i int default 0; # 声明一个变量while i<num do# 插入语句insert into app_user('name','email','phone','gender','password','age')values(concat('用户'),i,'1234@qq.con',concat('18',floor(rand()*((999999999-100000000)+100000000))),floor(rand()*2),uuid(),floor(rand()*100));set i = i + 1;end while;return i;end;
- 索引在小数据量的时候,用处不大,但是在大数据的时候,区别十分明显.
- 分析sql的执行效率:explain +sql语句
3.索引的原则
- 索引不是越多越好。
- 不要对经常变动的数据加索引。
- 小数据量的表不需要加索引。
- 索引一般加在常用来查询的字段上。
4.索引的数据结构
- Hash类型的索引。
- Btree:InnoDB 的默认数据结构。
八、数据库备份和权限管理
为什么备份:为了保证重要的数据不丢失。为了数据转移
1.MySQL数据库备份方式
- 直接拷贝物理文件。
- 在navicat这种可视化工具手动导出。
- 使用命令行导出 mysqldump 命令行使用。
-
导出备份
# mysqldump -h 主机 -u 用户名 -p 密码 数据库 表名1 > 物理磁盘位置/文件名mysqldump -hlocalhost -uroot -p123456 school student > D:/1.sql# mysqldump -h 主机 -u 用户名 -p 密码 数据库 表名1 表名2 表名3 > 物理磁盘位置/文件名mysqldump -hlocalhost -uroot -p123456 school student > D:/1.sql# mysqldump -h 主机 -u 用户名 -p 密码 数据库 > 物理磁盘位置/文件名mysqldump -hlocalhost -uroot -p123456 school > D:/1.sql
-
导入备份
# 登录的情况下,切换到指定的数据库。(导入数据库时,不用切换到数据库)# source 备份文件source d:/a.sql# 没有登录的情况下mysql -u用户名 -p密码 库名< 备份文件
2.权限管理
方式:navicat用户管理。SQL命令操作管理。
用户表:mysql.user
本质:读这张表进行增删改查
# 创建用户create user 用户名 identified by '密码';# 修改当前用户密码set password = password('123456');# 修改指定用户密码set password for 用户名 = password('123456');# 重命名rename user 原名字 to 新名字;# 用户授权,给用户授予所有权限(除了给别人授权)grant all privilieges on *.* to 用户名;# 查看指定用户的权限show grants for 用户名;# 查看root用户的权限show grants for root@localhost;# 撤销权限,撤销该用户所有表的所有权限revoke all privilieges on *.* from 用户名;# 删除该用户drop user 用户名;
九、规范数据库设计
1.为什么要设计
当数据库比较复杂的时候,我们就需要设计。
-
糟糕的数据库设计:
- 数据冗余,浪费空间
- 数据库插入和删除都会麻烦、异常(屏蔽使用物理外键)
- 程序的性能差
-
良好的数据库设计:
- 节约内存空间
- 保证数据库的完整性
- 方便我们开发系统
-
软件开发中,关于数据库的设计:
- 分析需求:分析业务和需要处理的数据库的需求
- 概要设计:设计关系图E-R图
2.数据库三大范式
为什么需要数据规范化
- 信息重复
- 更新异常
- 插入异常
- 删除异常
-
第一范式(1NF):原子性:保证每一列不可再分
-
第二范式(2NF):前提:满足第一范式;每张表只描述一件事情
-
第三范式(3NF):前提:满足第二范式;第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
3.规范性和性能的问题
关联查询的表不得超过三张表:
- 考虑商业化的需求和目标,(成本,用户体验)数据库的性能更加重要。
- 在规范和性能的问题时候,需要适当的考虑一下规范性。
- 故意给某些表增加一些冗余的字段。(从多表查询中变成单表查询)
- 故意增加一些计算列。(从大数据量降低为小数据量的查询:索引)
十、JDBC(重点)
1.数据库驱动
应用程序通过驱动连接数据库。MySQL驱动、Oracle驱动
2.JDBC
Java操作数据库的规范。
3.连接数据库七大步骤
- 加载驱动
- 连接数据库DriverManager
- 获取sql的执行对象statement
- 写sql
- 执行sql
- 处理结果集
- 释放连接
public void contextLoads() throws ClassNotFoundException, SQLException {// 1.加载驱动Class.forName("com.mysql.jdbc.Driver");// 2.获取连接String url = "jdbc:mysql://localhost:3306/demo?useUnicode=true&characterEncoding&useSSL=true";Connection connection = DriverManager.getConnection(url, "root", "123456");// 3.获取sql执行对象Statement statement = connection.createStatement();// 4.写sql语句String sql = "select * from user";// 5.执行sqlResultSet resultSet = statement.executeQuery(sql);// 6.处理返回的结果集。返回的结果集中封装了我们全部查询出来的结果while (resultSet.next()){System.out.println(resultSet.getObject("id"));System.out.println(resultSet.getObject("name"));System.out.println(resultSet.getObject("age"));}// 7.释放连接resultSet.close();statement.close();connection.close();}
4.数据库连接池
- 数据库连接—-执行完毕—-释放;连接—-释放,十分浪费系统资源。
- 池化技术:准备一些预先的资源,过来就连接预先准备好的。
常用连接数:10
最小连接数:10
最大连接数:100 业务最高承载上线
等待超时:100ms
编写连接池,实现一个接口 DataSource
开源数据源实现
- DBCP
- C3P0
- Druid
—- 业务级别MySQL学习
—- 运维级别MySQL学习
十一、按照月份分组的sql
# # create_time时间格式SELECT DATE_FORMAT(create_time,'%Y%u') weeks FROM role GROUP BY weeks;SELECT DATE_FORMAT(create_time,'%Y%m%d') days FROM role GROUP BY days;SELECT DATE_FORMAT(create_time,'%Y%m') months FROM role GROUP BY months# create_time时间戳格式SELECT FROM_UNIXTIME(create_time,'%Y%u') weeks FROM role GROUP BY weeks;SELECT FROM_UNIXTIME(create_time,'%Y%m%d') days FROM role GROUP BY days;SELECT FROM_UNIXTIME(create_time,'%Y%m') months FROM role GROUP BY months

 浙公网安备 33010602011771号
浙公网安备 33010602011771号