
1.安装cuda
2.安装插件Nsight Visual Studio Code Edition 和c++
3.给VSCode添加头文件的搜索路径
(55条消息) vscode中配置或添加头文件路径_vscode 配置头文件路径_Markus.Zhao的博客-CSDN博客
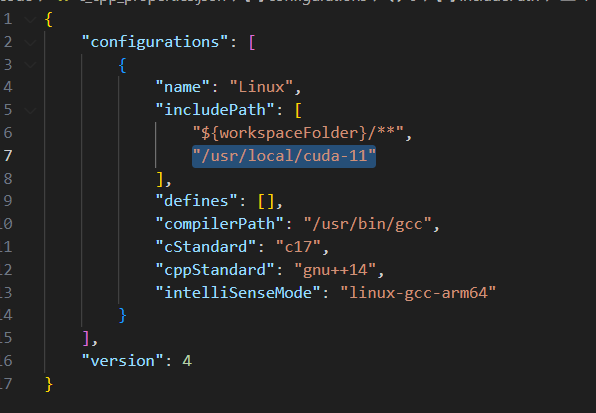
4.没有提示
blockDim
需要添加头文件
#include <device_launch_parameters.h>
5.查看grid,block的详细信息
找到cuda对应的位置,执行可执行文件
root@xintent-nx:/usr/local/cuda-10.2/samples/bin/aarch64/linux/release# ./deviceQuery

6.如果需要debug cuda程序和debug c++程序相同
nvcc -g -G setrun.cu -o set
7.终极计算position的位置公式


#include <stdio.h> #include <cuda_runtime.h> #include <cuda_profiler_api.h> #include <device_launch_parameters.h> // https://www.cnblogs.com/tiandsp/p/9458734.html 这个是反面教材 // compute最终会在gpu上,以3个线程启动进行执行 __global__ void compute(float* a, float* b, float* c){ /* * The function invokes kernel func on gridDim (gridDim.x × gridDim.y × gridDim.z) grid of blocks. * Each block contains blockDim (blockDim.x × blockDim.y × blockDim.z) threads. * gridDim、blockDim、blockIdx、threadIdx是系统内置的变量,可以直接访问 * gridDim,对应网格维度,由kernel启动时指定,deviceQuery中明确了,gridDim的最大值是受限的 Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535) * blockDim,每个网格里面块的维度,由kernel启动时指定,deviceQuery中明确了,gridDim的最大值是受限的 Max dimension size of a thread block (x,y,z): (1024, 1024, 64) * blockIdx,是核在运行时,所处block的索引 * threadIdx,是核在运行时,所处thread的索引 * grid、block是虚拟的,由CUDA的任务调度器管理并分配到真实cuda core中,实际每次启动的线程数由调度器决定 * gridDim、blockDim都是dim3类型,具有x、y、z属性值,blockIdx、threadIdx类型是uint3,具有x、y、z属性值 * 哪个线程先运行是不确定的 */ int d0 = gridDim.z; int d1 = gridDim.y; int d2 = gridDim.x; int d3 = blockDim.z; int d4 = blockDim.y; int d5 = blockDim.x; // 构成了一个tensor是d0 x d1 x d2 x d3 x d4 x d5 int p0 = blockIdx.z; int p1 = blockIdx.y; int p2 = blockIdx.x; int p3 = threadIdx.z; int p4 = threadIdx.y; int p5 = threadIdx.x; int position = (((((p0 * d1) + p1) * d2 + p2) * d3 + p3) * d4 + p4) * d5 + p5; //int position = ((blockIdx.y * gridDim.x) + blockIdx.x + threadIdx.y) * blockDim.x + threadIdx.x; //int position = ((gridDim.x * blockIdx.y + blockIdx.x) * blockDim.y + threadIdx.y) * blockDim.x + threadIdx.x; //int position = (blockDim.x * blockIdx.x + threadIdx.x); c[position] = a[position] * b[position]; printf("gridDim = %dx%dx%d, blockDim = %dx%dx%d, [blockIdx = %d,%d,%d, threadIdx = %d,%d,%d], position = %d, avalue = %f\n", gridDim.x, gridDim.y, gridDim.z, blockDim.x, blockDim.y, blockDim.z, blockIdx.x, blockIdx.y, blockIdx.z, threadIdx.x, threadIdx.y, threadIdx.z, position, a[position] ); } int main(){ const int num = 16; float a[num] = {1, 2, 3}; float b[num] = {5, 7, 9}; float c[num] = {0}; for(int i = 0; i < num; ++i){ a[i] = i; b[i] = i; } size_t size_array = sizeof(c); float* device_a = nullptr; float* device_b = nullptr; float* device_c = nullptr; // 分配GPU中的内存,大小是3个float,也就是12个字节 cudaMalloc(&device_a, size_array); cudaMalloc(&device_b, size_array); cudaMalloc(&device_c, size_array); // 把cpu中的数组复制到GPU中 cudaMemcpy(device_a, a, size_array, cudaMemcpyHostToDevice); cudaMemcpy(device_b, b, size_array, cudaMemcpyHostToDevice); // 启动核函数compute,并以1个block和3个thread的方式进行运行 compute<<<1, 32>>>(device_a, device_b, device_c); // 等待核函数执行完毕后,将数据复制到CPU(host)上变量c中 cudaMemcpy(c, device_c, size_array, cudaMemcpyDeviceToHost); // 打印c中的数据 for(int i = 8; i < 8 + 3; ++i){ printf("value.%d = %f\n", i, c[i]); } return 0; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号