

MySQL - - 多表查询
目录
- 1 多表联合查询
- 2 多表连接查询
- 3 复杂条件多表查询
- 4 子语句查询
- 5 其他方式查询
- 6 SQL逻辑查询语句执行顺序(重点)
- 7 外键约束
- 8 其他约束类型
- 9 表与表之间的关系
1 多表联合查询
- 创建表和数据
#创建部门
CREATE TABLE IF NOT EXISTS dept (
did int not null auto_increment PRIMARY KEY,
dname VARCHAR(50) not null COMMENT '部门名称'
)ENGINE=INNODB DEFAULT charset utf8;
#添加部门数据
INSERT INTO `dept` VALUES ('1', '教学部');
INSERT INTO `dept` VALUES ('2', '销售部');
INSERT INTO `dept` VALUES ('3', '市场部');
INSERT INTO `dept` VALUES ('4', '人事部');
INSERT INTO `dept` VALUES ('5', '鼓励部');
-- 创建人员
DROP TABLE IF EXISTS `person`;
CREATE TABLE `person` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL,
`age` tinyint(4) DEFAULT '0',
`sex` enum('男','女','人妖') NOT NULL DEFAULT '人妖',
`salary` decimal(10,2) NOT NULL DEFAULT '250.00',
`hire_date` date NOT NULL,
`dept_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8;
-- 添加人员数据
-- 教学部
INSERT INTO `person` VALUES ('1', 'alex', '28', '人妖', '53000.00', '2010-06-21', '1');
INSERT INTO `person` VALUES ('2', 'wupeiqi', '23', '男', '8000.00', '2011-02-21', '1');
INSERT INTO `person` VALUES ('3', 'egon', '30', '男', '6500.00', '2015-06-21', '1');
INSERT INTO `person` VALUES ('4', 'jingnvshen', '18', '女', '6680.00', '2014-06-21', '1');
-- 销售部
INSERT INTO `person` VALUES ('5', '歪歪', '20', '女', '3000.00', '2015-02-21', '2');
INSERT INTO `person` VALUES ('6', '星星', '20', '女', '2000.00', '2018-01-30', '2');
INSERT INTO `person` VALUES ('7', '格格', '20', '女', '2000.00', '2018-02-27', '2');
INSERT INTO `person` VALUES ('8', '周周', '20', '女', '2000.00', '2015-06-21', '2');
-- 市场部
INSERT INTO `person` VALUES ('9', '月月', '21', '女', '4000.00', '2014-07-21', '3');
INSERT INTO `person` VALUES ('10', '安琪', '22', '女', '4000.00', '2015-07-15', '3');
-- 人事部
INSERT INTO `person` VALUES ('11', '周明月', '17', '女', '5000.00', '2014-06-21', '4');
-- 鼓励部
INSERT INTO `person` VALUES ('12', '苍老师', '33', '女', '1000000.00', '2018-02-21', null);
#多表查询语法
select 字段1,字段2... from 表1,表2... [where 条件]
- 注意: 如果不加条件直接进行查询,则会出现以下效果,这种结果我们称之为 笛卡尔乘积
#查询人员和部门所有信息
select * from person,dept
- 笛卡尔乘积公式 : A表中数据条数 * B表中数据条数 = 笛卡尔乘积.
mysql> select * from person ,dept;
+----+----------+-----+-----+--------+------+-----+--------+
| id | name | age | sex | salary | did | did | dname |
+----+----------+-----+-----+--------+------+-----+--------+
| 1 | alex | 28 | 女 | 53000 | 1 | 1 | python |
| 1 | alex | 28 | 女 | 53000 | 1 | 2 | linux |
| 1 | alex | 28 | 女 | 53000 | 1 | 3 | 明教 |
| 2 | wupeiqi | 23 | 女 | 29000 | 1 | 1 | python |
| 2 | wupeiqi | 23 | 女 | 29000 | 1 | 2 | linux |
| 2 | wupeiqi | 23 | 女 | 29000 | 1 | 3 | 明教 |
| 3 | egon | 30 | 男 | 27000 | 1 | 1 | python |
| 3 | egon | 30 | 男 | 27000 | 1 | 2 | linux |
| 3 | egon | 30 | 男 | 27000 | 1 | 3 | 明教 |
| 4 | oldboy | 22 | 男 | 1 | 2 | 1 | python |
| 4 | oldboy | 22 | 男 | 1 | 2 | 2 | linux |
| 4 | oldboy | 22 | 男 | 1 | 2 | 3 | 明教 |
| 5 | jinxin | 33 | 女 | 28888 | 1 | 1 | python |
| 5 | jinxin | 33 | 女 | 28888 | 1 | 2 | linux |
| 5 | jinxin | 33 | 女 | 28888 | 1 | 3 | 明教 |
| 6 | 张无忌 | 20 | 男 | 8000 | 3 | 1 | python |
| 6 | 张无忌 | 20 | 男 | 8000 | 3 | 2 | linux |
| 6 | 张无忌 | 20 | 男 | 8000 | 3 | 3 | 明教 |
| 7 | 令狐冲 | 22 | 男 | 6500 | NULL | 1 | python |
| 7 | 令狐冲 | 22 | 男 | 6500 | NULL | 2 | linux |
| 7 | 令狐冲 | 22 | 男 | 6500 | NULL | 3 | 明教 |
| 8 | 东方不败 | 23 | 女 | 18000 | NULL | 1 | python |
| 8 | 东方不败 | 23 | 女 | 18000 | NULL | 2 | linux |
| 8 | 东方不败 | 23 | 女 | 18000 | NULL | 3 | 明教 |
+----+----------+-----+-----+--------+------+-----+--------+
#查询人员和部门所有信息
select * from person,dept where person.did = dept.did;
#注意: 多表查询时,一定要找到两个表中相互关联的字段,并且作为条件使用
mysql> select * from person,dept where person.did = dept.did;
+----+---------+-----+-----+--------+-----+-----+--------+
| id | name | age | sex | salary | did | did | dname |
+----+---------+-----+-----+--------+-----+-----+--------+
| 1 | alex | 28 | 女 | 53000 | 1 | 1 | python |
| 2 | wupeiqi | 23 | 女 | 29000 | 1 | 1 | python |
| 3 | egon | 30 | 男 | 27000 | 1 | 1 | python |
| 4 | oldboy | 22 | 男 | 1 | 2 | 2 | linux |
| 5 | jinxin | 33 | 女 | 28888 | 1 | 1 | python |
| 6 | 张无忌 | 20 | 男 | 8000 | 3 | 3 | 明教 |
| 7 | 令狐冲 | 22 | 男 | 6500 | 2 | 2 | linux |
+----+---------+-----+-----+--------+-----+-----+--------+
7 rows in set
2 多表连接查询
#多表连接查询语法(重点)
SELECT 字段列表
FROM 表1 INNER|LEFT|RIGHT JOIN 表2
ON 表1.字段 = 表2.字段;
- 1 内连接查询 (只显示符合条件的数据)
#查询人员和部门所有信息
select * from person inner join dept on person.did =dept.did;
- 效果: 大家可能会发现, 内连接查询与多表联合查询的效果是一样的.
mysql> select * from person inner join dept on person.did =dept.did;
+----+---------+-----+-----+--------+-----+-----+--------+
| id | name | age | sex | salary | did | did | dname |
+----+---------+-----+-----+--------+-----+-----+--------+
| 1 | alex | 28 | 女 | 53000 | 1 | 1 | python |
| 2 | wupeiqi | 23 | 女 | 29000 | 1 | 1 | python |
| 3 | egon | 30 | 男 | 27000 | 1 | 1 | python |
| 4 | oldboy | 22 | 男 | 1 | 2 | 2 | linux |
| 5 | jinxin | 33 | 女 | 28888 | 1 | 1 | python |
| 6 | 张无忌 | 20 | 男 | 8000 | 3 | 3 | 明教 |
| 7 | 令狐冲 | 22 | 男 | 6500 | 2 | 2 | linux |
+----+---------+-----+-----+--------+-----+-----+--------+
7 rows in set
- 2 左外连接查询 (左边表中的数据优先全部显示)
#查询人员和部门所有信息
select * from person left join dept on person.did =dept.did;
- 效果:人员表中的数据全部都显示,而 部门表中的数据符合条件的才会显示,不符合条件的会以 null 进行填充.
mysql> select * from person left join dept on person.did =dept.did;
+----+----------+-----+-----+--------+------+------+--------+
| id | name | age | sex | salary | did | did | dname |
+----+----------+-----+-----+--------+------+------+--------+
| 1 | alex | 28 | 女 | 53000 | 1 | 1 | python |
| 2 | wupeiqi | 23 | 女 | 29000 | 1 | 1 | python |
| 3 | egon | 30 | 男 | 27000 | 1 | 1 | python |
| 5 | jinxin | 33 | 女 | 28888 | 1 | 1 | python |
| 4 | oldboy | 22 | 男 | 1 | 2 | 2 | linux |
| 7 | 令狐冲 | 22 | 男 | 6500 | 2 | 2 | linux |
| 6 | 张无忌 | 20 | 男 | 8000 | 3 | 3 | 明教 |
| 8 | 东方不败 | 23 | 女 | 18000 | NULL | NULL | NULL |
+----+----------+-----+-----+--------+------+------+--------+
8 rows in set
- 3 右外连接查询 (右边表中的数据优先全部显示)
#查询人员和部门所有信息
select * from person right join dept on person.did =dept.did;
- 效果:正好与[左外连接相反]
mysql> select * from person right join dept on person.did =dept.did;
+----+---------+-----+-----+--------+-----+-----+--------+
| id | name | age | sex | salary | did | did | dname |
+----+---------+-----+-----+--------+-----+-----+--------+
| 1 | alex | 28 | 女 | 53000 | 1 | 1 | python |
| 2 | wupeiqi | 23 | 女 | 29000 | 1 | 1 | python |
| 3 | egon | 30 | 男 | 27000 | 1 | 1 | python |
| 4 | oldboy | 22 | 男 | 1 | 2 | 2 | linux |
| 5 | jinxin | 33 | 女 | 28888 | 1 | 1 | python |
| 6 | 张无忌 | 20 | 男 | 8000 | 3 | 3 | 明教 |
| 7 | 令狐冲 | 22 | 男 | 6500 | 2 | 2 | linux |
+----+---------+-----+-----+--------+-----+-----+--------+
7 rows in set
- 4 全连接查询(显示左右表中全部数据)
- 全连接查询:是在内连接的基础上增加 左右两边没有显示的数据
- 注意: mysql并不支持全连接 full JOIN 关键字
- 注意: 但是mysql 提供了 UNION 关键字.使用 UNION 可以间接实现 full JOIN 功能
- 全连接查询:是在内连接的基础上增加 左右两边没有显示的数据
#查询人员和部门的所有数据
SELECT * FROM person LEFT JOIN dept ON person.did = dept.did
UNION
SELECT * FROM person RIGHT JOIN dept ON person.did = dept.did;
mysql> SELECT * FROM person LEFT JOIN dept ON person.did = dept.did
UNION
SELECT * FROM person RIGHT JOIN dept ON person.did = dept.did;
+------+----------+------+------+--------+------+------+--------+
| id | name | age | sex | salary | did | did | dname |
+------+----------+------+------+--------+------+------+--------+
| 1 | alex | 28 | 女 | 53000 | 1 | 1 | python |
| 2 | wupeiqi | 23 | 女 | 29000 | 1 | 1 | python |
| 3 | egon | 30 | 男 | 27000 | 1 | 1 | python |
| 5 | jinxin | 33 | 女 | 28888 | 1 | 1 | python |
| 4 | oldboy | 22 | 男 | 1 | 2 | 2 | linux |
| 7 | 令狐冲 | 22 | 男 | 6500 | 2 | 2 | linux |
| 6 | 张无忌 | 20 | 男 | 8000 | 3 | 3 | 明教 |
| 8 | 东方不败 | 23 | 女 | 18000 | NULL | NULL | NULL |
| NULL | NULL | NULL | NULL | NULL | NULL | 4 | 基督教 |
+------+----------+------+------+--------+------+------+--------+
9 rows in set
注意: UNION 和 UNION ALL 的区别:UNION 会去掉重复的数据,而 UNION ALL 则直接显示结果
3 复杂条件多表查询
- 1 查询出 教学部 年龄大于20岁,并且工资小于40000的员工,按工资倒序排列.(要求:分别使用多表联合查询和内连接查询)
#1.多表联合查询方式:
select * from person p1,dept d2 where p1.did = d2.did
and d2.dname='python'
and age>20
and salary <40000
ORDER BY salary DESC;
#2.内连接查询方式:
SELECT * FROM person p1 INNER JOIN dept d2 ON p1.did= d2.did
and d2.dname='python'
and age>20
and salary <40000
ORDER BY salary DESC;
- 2 查询每个部门中最高工资和最低工资是多少,显示部门名称
select MAX(salary),MIN(salary),dept.dname from
person LEFT JOIN dept
ON person.did = dept.did
GROUP BY person.did;
4 子语句查询
- 子查询(嵌套查询): 查多次, 多个select
- 注意: 第一次的查询结果可以作为第二次的查询的 条件 或者 表名 使用.
- 子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字. 还可以包含比较运算符:= 、 !=、> 、<等.
- 1作为表名使用
select * from (select * from person) as 表名;
ps:大家需要注意的是: 一条语句中可以有多个这样的子查询,在执行时,最里层括号(sql语句) 具有优先执行权.<br>注意: as 后面的表名称不能加引号('')
- 2 求最大工资那个人的姓名和薪水
1.求最大工资
select max(salary) from person;
2.求最大工资那个人叫什么
select name,salary from person where salary=53000;
合并
select name,salary from person where salary=(select max(salary) from person);
- 3 求工资高于所有人员平均工资的人员
1.求平均工资
select avg(salary) from person;
2.工资大于平均工资的 人的姓名、工资
select name,salary from person where salary > 21298.625;
合并
select name,salary from person where salary >(select avg(salary) from person);
- 4 练习
- 1查询平均年龄在20岁以上的部门名
- 2查询教学部 下的员工信息
- 3查询大于所有人平均工资的人员的姓名与年龄
#1.查询平均年龄在20岁以上的部门名
SELECT * from dept where dept.did in (
select dept_id from person GROUP BY dept_id HAVING avg(person.age) > 20
);
#2.查询教学部 下的员工信息
select * from person where dept_id = (select did from dept where dname ='教学部');
#3.查询大于所有人平均工资的人员的姓名与年龄
select * from person where salary > (select avg(salary) from person);
- 5 关键字
- ANY关键字
假设any内部的查询语句返回的结果个数是三个,如:result1,result2,result3,那么,
select ...from ... where a > any(...);
->
select ...from ... where a > result1 or a > result2 or a > result3;
- ALL关键字
ALL关键字与any关键字类似,只不过上面的or改成and。即:
select ...from ... where a > all(...);
->
select ...from ... where a > result1 and a > result2 and a > result3;
- SOME关键字
some关键字和any关键字是一样的功能。所以:
select ...from ... where a > some(...);
->
select ...from ... where a > result1 or a > result2 or a > result3;
- EXISTS 关键字
EXISTS 和 NOT EXISTS 子查询语法如下:
SELECT ... FROM table WHERE EXISTS (subquery)
该语法可以理解为:主查询(外部查询)会根据子查询验证结果(TRUE 或 FALSE)来决定主查询是否得以执行。
mysql> SELECT * FROM person
-> WHERE EXISTS
-> (SELECT * FROM dept WHERE did=5);
Empty set (0.00 sec)
此处内层循环并没有查询到满足条件的结果,因此返回false,外层查询不执行。
NOT EXISTS刚好与之相反
mysql> SELECT * FROM person
-> WHERE NOT EXISTS
-> (SELECT * FROM dept WHERE did=5);
+----+----------+-----+-----+--------+------+
| id | name | age | sex | salary | did |
+----+----------+-----+-----+--------+------+
| 1 | alex | 28 | 女 | 53000 | 1 |
| 2 | wupeiqi | 23 | 女 | 29000 | 1 |
| 3 | egon | 30 | 男 | 27000 | 1 |
| 4 | oldboy | 22 | 男 | 1 | 2 |
| 5 | jinxin | 33 | 女 | 28888 | 1 |
| 6 | 张无忌 | 20 | 男 | 8000 | 3 |
| 7 | 令狐冲 | 22 | 男 | 6500 | 2 |
| 8 | 东方不败 | 23 | 女 | 18000 | NULL |
+----+----------+-----+-----+--------+------+
8 rows in set
当然,EXISTS关键字可以与其他的查询条件一起使用,条件表达式与EXISTS关键字之间用AND或者OR来连接,如下:
mysql> SELECT * FROM person
-> WHERE AGE >23 AND NOT EXISTS
-> (SELECT * FROM dept WHERE did=5);
提示:
•EXISTS (subquery) 只返回 TRUE 或 FALSE,因此子查询中的 SELECT * 也可以是 SELECT 1 或其他,官方说法是实际执行时会忽略 SELECT 清单,因此没有区别。
5 其他方式查询
- 1 临时表查询
- 需求: 查询高于本部门平均工资的人员

# 解析思路: 1.先查询本部门人员平均工资是多少.
# 2.再使用人员的工资与部门的平均工资进行比较
#1.先查询部门人员的平均工资
SELECT dept_id,AVG(salary)as sal from person GROUP BY dept_id;
#2.再用人员的工资与部门的平均工资进行比较
SELECT * FROM person as p1,
(SELECT dept_id,AVG(salary)as '平均工资' from person GROUP BY dept_id) as p2
where p1.dept_id = p2.dept_id AND p1.salary >p2.`平均工资`;
ps:在当前语句中,我们可以把上一次的查询结果当前做一张表来使用.因为p2表不是真是存在的,所以:我们称之为 临时表
临时表:不局限于自身表,任何的查询结果集都可以认为是一个临时表.
- 判断查询 IF关键字
- 需求1 :根据工资高低,将人员划分为两个级别,分别为 高端人群和低端人群。显示效果:姓名,年龄,性别,工资,级别
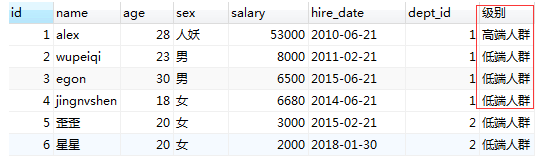
select p1.*,
IF(p1.salary >10000,'高端人群','低端人群') as '级别'
from person p1;
#ps: 语法: IF(条件表达式,"结果为true",'结果为false');
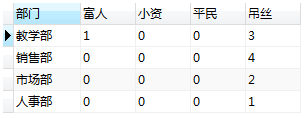
- 需求2: 根据工资高低,统计每个部门人员收入情况,划分为 富人,小资,平民,吊丝 四个级别, 要求统计四个级别分别有多少人
#语法一:
SELECT
CASE WHEN STATE = '1' THEN '成功'
WHEN STATE = '2' THEN '失败'
ELSE '其他' END
FROM 表;
#语法二:
SELECT CASE age
WHEN 23 THEN '23岁'
WHEN 27 THEN '27岁'
WHEN 30 THEN '30岁'
ELSE '其他岁' END
FROM person;
SELECT dname '部门',
sum(case WHEN salary >50000 THEN 1 ELSE 0 end) as '富人',
sum(case WHEN salary between 29000 and 50000 THEN 1 ELSE 0 end) as '小资',
sum(case WHEN salary between 10000 and 29000 THEN 1 ELSE 0 end) as '平民',
sum(case WHEN salary <10000 THEN 1 ELSE 0 end) as '吊丝'
FROM person,dept where person.dept_id = dept.did GROUP BY dept_id
6 SQL逻辑查询语句执行顺序
6.1 SQL语句定义顺序
SELECT DISTINCT <select_list>
FROM <left_table>
<join_type> JOIN <right_table>
ON <join_condition>
WHERE <where_condition>
GROUP BY <group_by_list>
HAVING <having_condition>
ORDER BY <order_by_condition>
LIMIT <limit_number>
6.2 准备测试
- 1 新建一个测试数据库TestDB;
CREATE DATABASE TestDB DEFAULT charset utf8;
- 2 创建测试表table1和table2;
CREATE TABLE table1(
customer_id VARCHAR(10) NOT NULL,
city VARCHAR(10) NOT NULL,
PRIMARY KEY(customer_id)
)ENGINE=INNODB DEFAULT CHARSET=UTF8;
CREATE TABLE table2(
order_id INT NOT NULL auto_increment,
customer_id VARCHAR(10),
PRIMARY KEY(order_id)
)ENGINE=INNODB DEFAULT CHARSET=UTF8;
- 3 插入测试数据
INSERT INTO table1(customer_id,city) VALUES('163','hangzhou');
INSERT INTO table1(customer_id,city) VALUES('9you','shanghai');
INSERT INTO table1(customer_id,city) VALUES('tx','hangzhou');
INSERT INTO table1(customer_id,city) VALUES('baidu','hangzhou');
INSERT INTO table2(customer_id) VALUES('163');
INSERT INTO table2(customer_id) VALUES('163');
INSERT INTO table2(customer_id) VALUES('9you');
INSERT INTO table2(customer_id) VALUES('9you');
INSERT INTO table2(customer_id) VALUES('9you');
INSERT INTO table2(customer_id) VALUES('tx');
INSERT INTO table2(customer_id) VALUES(NULL);
- 4 效果
mysql> select * from table1;
+-------------+----------+
| customer_id | city |
+-------------+----------+
| 163 | hangzhou |
| 9you | shanghai |
| baidu | hangzhou |
| tx | hangzhou |
+-------------+----------+
4 rows in set (0.00 sec)
mysql> select * from table2;
+----------+-------------+
| order_id | customer_id |
+----------+-------------+
| 1 | 163 |
| 2 | 163 |
| 3 | 9you |
| 4 | 9you |
| 5 | 9you |
| 6 | tx |
| 7 | NULL |
+----------+-------------+
7 rows in set (0.00 sec)
- 5 准备SQL逻辑查询测试语句
SELECT
a.customer_id,
COUNT(b.order_id) as total_orders
FROM table1 AS a LEFT JOIN table2 AS b
ON a.customer_id = b.customer_id
WHERE a.city = 'hangzhou'
GROUP BY a.customer_id
HAVING count(b.order_id) < 2
ORDER BY total_orders DESC;
# SQL语句解释: 获得来自杭州,并且订单数少于2的客户
6.3 SQL逻辑查询语句执行顺序
(7) SELECT
(8) DISTINCT <select_list>
(1) FROM <left_table>
(3) <join_type> JOIN <right_table>
(2) ON <join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list>
(6) HAVING <having_condition>
(9) ORDER BY <order_by_condition>
(10) LIMIT <limit_number>
6.4 SQL执行先后顺序分析
- 在这些SQL语句的执行过程中,都会产生一个虚拟表,用来保存SQL语句的执行结果(这是重点),我们现在就来跟踪这个虚拟表的变化,得到最终的查询结果的过程,来分析整个SQL逻辑查询的执行顺序和过程。
6.4.1 执行FROM语句
- 第一步,执行FROM语句。我们首先需要知道最开始从哪个表开始的,这就是FROM告诉我们的。现在有了<left_table>和<right_table>两个表,我们到底从哪个表开始,还是从两个表进行某种联系以后再开始呢?它们之间如何产生联系呢?——笛卡尔积
- 经过FROM语句对两个表执行笛卡尔积,会得到一个虚拟表,暂且叫VT1(vitual table 1),内容如下:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| 9you | shanghai | 1 | 163 |
| baidu | hangzhou | 1 | 163 |
| tx | hangzhou | 1 | 163 |
| 163 | hangzhou | 2 | 163 |
| 9you | shanghai | 2 | 163 |
| baidu | hangzhou | 2 | 163 |
| tx | hangzhou | 2 | 163 |
| 163 | hangzhou | 3 | 9you |
| 9you | shanghai | 3 | 9you |
| baidu | hangzhou | 3 | 9you |
| tx | hangzhou | 3 | 9you |
| 163 | hangzhou | 4 | 9you |
| 9you | shanghai | 4 | 9you |
| baidu | hangzhou | 4 | 9you |
| tx | hangzhou | 4 | 9you |
| 163 | hangzhou | 5 | 9you |
| 9you | shanghai | 5 | 9you |
| baidu | hangzhou | 5 | 9you |
| tx | hangzhou | 5 | 9you |
| 163 | hangzhou | 6 | tx |
| 9you | shanghai | 6 | tx |
| baidu | hangzhou | 6 | tx |
| tx | hangzhou | 6 | tx |
| 163 | hangzhou | 7 | NULL |
| 9you | shanghai | 7 | NULL |
| baidu | hangzhou | 7 | NULL |
| tx | hangzhou | 7 | NULL |
+-------------+----------+----------+-------------+
- 总共有28(table1的记录条数 * table2的记录条数)条记录。这就是VT1的结果,接下来的操作就在VT1的基础上进行。
6.4.2 执行ON过滤
- 执行完笛卡尔积以后,接着就进行ON a.customer_id = b.customer_id条件过滤,根据ON中指定的条件,去掉那些不符合条件的数据,得到VT2表,内容如下:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| 163 | hangzhou | 2 | 163 |
| 9you | shanghai | 3 | 9you |
| 9you | shanghai | 4 | 9you |
| 9you | shanghai | 5 | 9you |
| tx | hangzhou | 6 | tx |
+-------------+----------+----------+-------------+
6.4.3 添加外部行
- 这一步只有在连接类型为OUTER JOIN时才发生,如LEFT OUTER JOIN、RIGHT OUTER JOIN。在大多数的时候,我们都是会省略掉OUTER关键字的,但OUTER表示的就是外部行的概念。
- LEFT OUTER JOIN把左表记为保留表,得到的结果为:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| 163 | hangzhou | 2 | 163 |
| 9you | shanghai | 3 | 9you |
| 9you | shanghai | 4 | 9you |
| 9you | shanghai | 5 | 9you |
| tx | hangzhou | 6 | tx |
| baidu | hangzhou | NULL | NULL |
+-------------+----------+----------+-------------+
- RIGHT OUTER JOIN把右表记为保留表,得到的结果为:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| 163 | hangzhou | 2 | 163 |
| 9you | shanghai | 3 | 9you |
| 9you | shanghai | 4 | 9you |
| 9you | shanghai | 5 | 9you |
| tx | hangzhou | 6 | tx |
| NULL | NULL | 7 | NULL |
+-------------+----------+----------+-------------+
- 添加外部行的工作就是在VT2表的基础上添加保留表中被过滤条件过滤掉的数据,非保留表中的数据被赋予NULL值,最后生成虚拟表VT3。
- 由于我在准备的测试SQL查询逻辑语句中使用的是LEFT JOIN,过滤掉了以下这条数据:
| baidu | hangzhou | NULL | NULL |
- 现在就把这条数据添加到VT2表中,得到的VT3表如下:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| 163 | hangzhou | 2 | 163 |
| 9you | shanghai | 3 | 9you |
| 9you | shanghai | 4 | 9you |
| 9you | shanghai | 5 | 9you |
| tx | hangzhou | 6 | tx |
| baidu | hangzhou | NULL | NULL |
+-------------+----------+----------+-------------+
- 接下来的操作都会在该VT3表上进行。
6.4.4 执行WHERE过滤
- 对添加外部行得到的VT3进行WHERE过滤,只有符合<where_condition>的记录才会输出到虚拟表VT4中。当我们执行WHERE a.city = 'hangzhou'的时候,就会得到以下内容,并存在虚拟表VT4中:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| 163 | hangzhou | 2 | 163 |
| tx | hangzhou | 6 | tx |
| baidu | hangzhou | NULL | NULL |
+-------------+----------+----------+-------------+
- 但是在使用WHERE子句时,需要注意以下两点:
- 由于数据还没有分组,因此现在还不能在WHERE过滤器中使用where_condition=MIN(col)这类对分组统计的过滤;
- 由于还没有进行列的选取操作,因此在SELECT中使用列的别名也是不被允许的,如:SELECT city as c FROM t WHERE c='shanghai';是不允许出现的。
6.4.5 执行GROUP BY分组
- GROU BY子句主要是对使用WHERE子句得到的虚拟表进行分组操作。我们执行测试语句中的GROUP BY a.customer_id,就会得到以下内容:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| baidu | hangzhou | NULL | NULL |
| tx | hangzhou | 6 | tx |
+-------------+----------+----------+-------------+
- 得到的内容会存入虚拟表VT5中,此时,我们就得到了一个VT5虚拟表,接下来的操作都会在该表上完成。
6.4.6 执行HAVING过滤
- HAVING子句主要和GROUP BY子句配合使用,对分组得到的VT5虚拟表进行条件过滤。当我执行测试语句中的HAVING count(b.order_id) < 2时,将得到以下内容:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| baidu | hangzhou | NULL | NULL |
| tx | hangzhou | 6 | tx |
+-------------+----------+----------+-------------+
- 这就是虚拟表VT6。
6.4.7 SELECT列表
- 现在才会执行到SELECT子句,不要以为SELECT子句被写在第一行,就是第一个被执行的。
- 我们执行测试语句中的SELECT a.customer_id, COUNT(b.order_id) as total_orders,从虚拟表VT6中选择出我们需要的内容。我们将得到以下内容:
+-------------+--------------+
| customer_id | total_orders |
+-------------+--------------+
| baidu | 0 |
| tx | 1 |
+-------------+--------------+
- 还没有完,这只是虚拟表VT7。
6.4.8 执行DISTINCT子句
- 如果在查询中指定了DISTINCT子句,则会创建一张内存临时表(如果内存放不下,就需要存放在硬盘了)。这张临时表的表结构和上一步产生的虚拟表VT7是一样的,不同的是对进行DISTINCT操作的列增加了一个唯一索引,以此来除重复数据。
- 由于我的测试SQL语句中并没有使用DISTINCT,所以,在该查询中,这一步不会生成一个虚拟表。
6.4.9 执行ORDER BY子句
- 对虚拟表中的内容按照指定的列进行排序,然后返回一个新的虚拟表,我们执行测试SQL语句中的ORDER BY total_orders DESC,就会得到以下内容:
+-------------+--------------+
| customer_id | total_orders |
+-------------+--------------+
| tx | 1 |
| baidu | 0 |
+-------------+--------------+
- 可以看到这是对total_orders列进行降序排列的。上述结果会存储在VT8中。
6.4.10 执行LIMIT子句
- LIMIT子句从上一步得到的VT8虚拟表中选出从指定位置开始的指定行数据。对于没有应用ORDER BY的LIMIT子句,得到的结果同样是无序的,所以,很多时候,我们都会看到LIMIT子句会和ORDER BY子句一起使用。
- MySQL数据库的LIMIT支持如下形式的选择:
LIMIT n, m
- 表示从第n条记录开始选择m条记录。而很多开发人员喜欢使用该语句来解决分页问题。对于小数据,使用LIMIT子句没有任何问题,当数据量非常大的时候,使用LIMIT n, m是非常低效的。因为LIMIT的机制是每次都是从头开始扫描,如果需要从第60万行开始,读取3条数据,就需要先扫描定位到60万行,然后再进行读取,而扫描的过程是一个非常低效的过程。所以,对于大数据处理时,是非常有必要在应用层建立一定的缓存机制(貌似现在的大数据处理,都有缓存哦).
7 外键约束
- 1 问题?
- 什么是约束:约束是一种限制,它通过对表的行或列的数据做出限制,来确保表的数据的完整性、唯一性
- 2 问题?
- 以上两个表 person和dept中, 新人员可以没有部门吗?
- 3问题?
- 新人员可以添加一个不存在的部门吗?
- 4如何解决以上问题呢?
- 简单的说,就是对两个表的关系进行一些约束 (即: froegin key).
- foreign key 定义:就是表与表之间的某种约定的关系,由于这种关系的存在,能够让表与表之间的数据,更加的完整,关连性更强。
- 5 具体操作
- 创建表时,同时创建外键约束
CREATE TABLE IF NOT EXISTS dept (
did int not null auto_increment PRIMARY KEY,
dname VARCHAR(50) not null COMMENT '部门名称'
)ENGINE=INNODB DEFAULT charset utf8;
CREATE TABLE IF NOT EXISTS person(
id int not null auto_increment PRIMARY KEY,
name VARCHAR(50) not null,
age TINYINT(4) null DEFAULT 0,
sex enum('男','女','人妖') NOT NULL DEFAULT '人妖',
salary decimal(10,2) NULL DEFAULT '250.00',
hire_date date NOT NULL,
dept_id int(11) DEFAULT NULL,
CONSTRAINT fk_did FOREIGN KEY(dept_id) REFERENCES dept(did) -- 添加外键约束
)ENGINE = INNODB DEFAULT charset utf8;
- 已经创建表后,追加外键约束
#添加外键约束
ALTER table person add constraint fk_did FOREIGN key(dept_id) REFERENCES dept(did);
#删除外键约束
ALTER TABLE person drop FOREIGN key fk_did;
- 定义外键的条件:
- (1)外键对应的字段数据类型保持一致,且被关联的字段(即references指定的另外一个表的字段),必须保证唯一
- (2)所有tables的存储引擎必须是InnoDB类型.
- (3)外键的约束4种类型: 1.RESTRICT 2. NO ACTION 3.CASCADE 4.SET NULL
- 约束类型详解
RESTRICT
同no action, 都是立即检查外键约束
NO ACTION
如果子表中有匹配的记录,则不允许对父表对应候选键进行update/delete操作
CASCADE
在父表上update/delete记录时,同步update/delete掉子表的匹配记录
SET NULL
在父表上update/delete记录时,将子表上匹配记录的列设为null (要注意子表的外键列不能为not null)
- (4)建议:
- 1 如果需要外键约束,最好创建表同时创建外键约束.
- 2 如果需要设置级联关系,删除时最好设置为 SET NULL.
- 注:
- 插入数据时,先插入主表中的数据,再插入从表中的数据。
- 删除数据时,先删除从表中的数据,再删除主表中的数据。
8 其他约束类型
- 1 非空约束
- 关键字: NOT NULL ,表示 不可空. 用来约束表中的字段列
create table t1(
id int(10) not null primary key,
name varchar(100) null
);
- 2 主键约束
- 用于约束表中的一行,作为这一行的标识符,在一张表中通过主键就能准确定位到一行,因此主键十分重要。
create table t2(
id int(10) not null primary key
);
- 注意: 主键这一行的数据不能重复且不能为空。
- 还有一种特殊的主键——复合主键。主键不仅可以是表中的一列,也可以由表中的两列或多列来共同标识
create table t3(
id int(10) not null,
name varchar(100) ,
primary key(id,name)
);
- 3 唯一约束
- 关键字: UNIQUE, 比较简单,它规定一张表中指定的一列的值必须不能有重复值,即这一列每个值都是唯一的。
create table t4(
id int(10) not null,
name varchar(255) ,
unique id_name(id,name)
);
//添加唯一约束
alter table t4 add unique id_name(id,name);
//删除唯一约束
alter table t4 drop index id_name;
-
注意: 当INSERT语句新插入的数据和已有数据重复的时候,如果有UNIQUE约束,则INSERT失败.
-
4 默认值约束
- 关键字: DEFAULT
create table t5(
id int(10) not null primary key,
name varchar(255) default '张三'
);
#插入数据
INSERT into t5(id) VALUES(1),(2);
- 注意: INSERT语句执行时.,如果被DEFAULT约束的位置没有值,那么这个位置将会被DEFAULT的值填充
9 表与表之间的关系
9.1 表关系分类:
- 总体可以分为三类: 一对一 、一对多(多对一) 、多对多
9.2 如何区分表与表之间是什么关系?
#分析步骤:
#多对一 /一对多
#1.站在左表的角度去看右表(情况一)
如果左表中的一条记录,对应右表中多条记录.那么他们的关系则为 一对多 关系.约束关系为:左表普通字段, 对应右表foreign key 字段.
注意:如果左表与右表的情况反之.则关系为 多对一 关系.约束关系为:左表foreign key 字段, 对应右表普通字段.
#一对一
#2.站在左表的角度去看右表(情况二)
如果左表中的一条记录 对应 右表中的一条记录. 则关系为 一对一关系.
约束关系为:左表foreign key字段上 添加唯一(unique)约束, 对应右表 关联字段.
或者:右表foreign key字段上 添加唯一(unique)约束, 对应右表 关联字段.
#多对多
#3.站在左表和右表同时去看(情况三)
如果左表中的一条记录 对应 右表中的多条记录,并且右表中的一条记录同时也对应左表的多条记录. 那么这种关系 则 多对多 关系.
这种关系需要定义一个这两张表的[关系表]来专门存放二者的关系
9.3 建立表关系
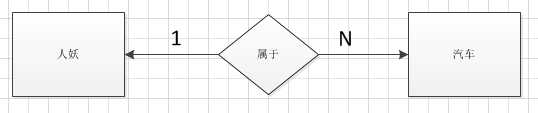
- 1 一对多关系
例如:一个人可以拥有多辆汽车,要求查询某个人拥有的所有车辆。
分析:人和车辆分别单独建表,那么如何将两个表关联呢?有个巧妙的方法,在车辆的表中加个外键字段(人的编号)即可。
* (思路小结:’建两个表,一’方不动,’多’方添加一个外键字段)*
//建立人员表
CREATE TABLE people(
id VARCHAR(12) PRIMARY KEY,
sname VARCHAR(12),
age INT,
sex CHAR(1)
);
INSERT INTO people VALUES('H001','小王',27,'1');
INSERT INTO people VALUES('H002','小明',24,'1');
INSERT INTO people VALUES('H003','张慧',28,'0');
INSERT INTO people VALUES('H004','李小燕',35,'0');
INSERT INTO people VALUES('H005','王大拿',29,'1');
INSERT INTO people VALUES('H006','周强',36,'1');
//建立车辆信息表
CREATE TABLE car(
id VARCHAR(12) PRIMARY KEY,
mark VARCHAR(24),
price NUMERIC(6,2),
pid VARCHAR(12),
CONSTRAINT fk_people FOREIGN KEY(pid) REFERENCES people(id)
);
INSERT INTO car VALUES('C001','BMW',65.99,'H001');
INSERT INTO car VALUES('C002','BenZ',75.99,'H002');
INSERT INTO car VALUES('C003','Skoda',23.99,'H001');
INSERT INTO car VALUES('C004','Peugeot',20.99,'H003');
INSERT INTO car VALUES('C005','Porsche',295.99,'H004');
INSERT INTO car VALUES('C006','Honda',24.99,'H005');
INSERT INTO car VALUES('C007','Toyota',27.99,'H006');
INSERT INTO car VALUES('C008','Kia',18.99,'H002');
INSERT INTO car VALUES('C009','Bentley',309.99,'H005');
例子1:学生和班级之间的关系
班级表
id class_name
1 python脱产100期
2 python脱产300期
学生表 foreign key
id name class_id
1 alex 2
2 刘强东 2
3 马云 1
例子2: 一个女孩 拥有多个男朋友...
例子3:....
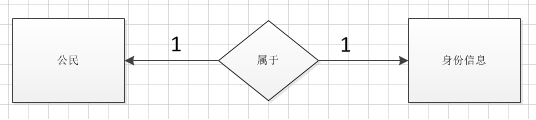
- 2 一对一关系
例如:一个中国公民只能有一个身份证信息
分析: 一对一的表关系实际上是 变异了的 一对多关系. 通过在从表的外键字段上添加唯一约束(unique)来实现一对一表关系.
#身份证信息表
CREATE TABLE card (
id int NOT NULL AUTO_INCREMENT PRIMARY KEY,
code varchar(18) DEFAULT NULL,
UNIQUE un_code (CODE) -- 创建唯一索引的目的,保证身份证号码同样不能出现重复
);
INSERT INTO card VALUES(null,'210123123890890678'),
(null,'210123456789012345'),
(null,'210098765432112312');
#公民表
CREATE TABLE people (
id int NOT NULL AUTO_INCREMENT PRIMARY KEY,
name varchar(50) DEFAULT NULL,
sex char(1) DEFAULT '0',
c_id int UNIQUE, -- 外键添加唯一约束,确保一对一
CONSTRAINT fk_card_id FOREIGN KEY (c_id) REFERENCES card(id)
);
INSERT INTO people VALUES(null,'zhangsan','1',1),
(null,'lisi','0',2),
(null,'wangwu','1',3);
例子一:一个用户只有一个博客
用户表:
主键
id name
1 egon
2 alex
3 wupeiqi
博客表
fk+unique
id url user_id
1 xxxx 1
2 yyyy 3
3 zzz 2
例子2: 一个男人的户口本上,一辈子最多只能一个女主的名字.等等
- 3 多对多关系
例如:学生选课,一个学生可以选修多门课程,每门课程可供多个学生选择。
分析:这种方式可以按照类似一对多方式建表,但冗余信息太多,好的方式是实体和关系分离并单独建表,实体表为学生表和课程表,关系表为选修表,
其中关系表采用联合主键的方式(由学生表主键和课程表主键组成)建表。

#//建立学生表
CREATE TABLE student(
id VARCHAR(10) PRIMARY KEY,
sname VARCHAR(12),
age INT,
sex CHAR(1)
);
INSERT INTO student VALUES('S0001','王军',20,1);
INSERT INTO student VALUES('S0002','张宇',21,1);
INSERT INTO student VALUES('S0003','刘飞',22,1);
INSERT INTO student VALUES('S0004','赵燕',18,0);
INSERT INTO student VALUES('S0005','曾婷',19,0);
INSERT INTO student VALUES('S0006','周慧',21,0);
INSERT INTO student VALUES('S0007','小红',23,0);
INSERT INTO student VALUES('S0008','杨晓',18,0);
INSERT INTO student VALUES('S0009','李杰',20,1);
INSERT INTO student VALUES('S0010','张良',22,1);
# //建立课程表
CREATE TABLE course(
id VARCHAR(10) PRIMARY KEY,
sname VARCHAR(12),
credit DOUBLE(2,1),
teacher VARCHAR(12)
);
INSERT INTO course VALUES('C001','Java',3.5,'李老师');
INSERT INTO course VALUES('C002','高等数学',5.0,'赵老师');
INSERT INTO course VALUES('C003','JavaScript',3.5,'王老师');
INSERT INTO course VALUES('C004','离散数学',3.5,'卜老师');
INSERT INTO course VALUES('C005','数据库',3.5,'廖老师');
INSERT INTO course VALUES('C006','操作系统',3.5,'张老师');
# //建立选修表
CREATE TABLE sc(
sid VARCHAR(10),
cid VARCHAR(10),
PRIMARY KEY(sid,cid),
CONSTRAINT fk_student FOREIGN KEY(sid) REFERENCES student(id),
CONSTRAINT fk_course FOREIGN KEY(cid) REFERENCES course(id)
);
INSERT INTO sc VALUES('S0001','C001');
INSERT INTO sc VALUES('S0001','C002');
INSERT INTO sc VALUES('S0001','C003');
INSERT INTO sc VALUES('S0002','C001');
INSERT INTO sc VALUES('S0002','C004');
INSERT INTO sc VALUES('S0003','C002');
INSERT INTO sc VALUES('S0003','C005');
INSERT INTO sc VALUES('S0004','C003');
INSERT INTO sc VALUES('S0005','C001');
INSERT INTO sc VALUES('S0006','C004');
INSERT INTO sc VALUES('S0007','C002');
INSERT INTO sc VALUES('S0008','C003');
INSERT INTO sc VALUES('S0009','C001');
INSERT INTO sc VALUES('S0009','C005');
例子1:中华相亲网: 男嘉宾表+相亲关系表+女嘉宾表
男嘉宾:
1 孟飞
2 乐嘉
女嘉宾:
1 小乐
2 小嘉
相亲表:(中间表)
男嘉宾 女嘉宾 相亲时间
1 1 2017-10-12 12:12:12
1 2 2017-10-13 12:12:12
1 1 2017-10-15 12:12:12
例子2: 用户表,菜单表,用户权限表...

