


python - - 函数 - - 内置函数和匿名函数
目录
- 内置函数
- 匿名函数
- 本章小结
- 相关练习题
1,内置函数
- python里的内置函数。截止到python版本3.6.2,现在python一共为我们提供了68个内置函数。
| Built-inFunctions | ||||
|---|---|---|---|---|
| abs() | dict() | help() | min() | setattr() |
| all() | dir() | hex() | next() | slice() |
| any() | divmod() | id() | object() | sorted() |
| ascii() | enumerate() | input() | oct() | staticmethod() |
| bin() | eval() | int() | open() | str() |
| bool() | exec() | isinstance() | ord() | sum() |
| bytearray() | filter() | issubclass() | pow() | super() |
| bytes() | float() | iter() | print() | tuple() |
| callable() | format() | len() | property() | type() |
| chr() | frozenset() | list() | range() | vars() |
| classmethod() | getattr() | locals() | repr() | zip() |
| compile() | globals() | map() | reversed() | __import__() |
| complex() | hasattr() | max() | round() | |
| delattr() | hash() | memoryview() | set() |
1.1 作用域相关
- 基于字典的形式获取局部变量和全局变量
globals() # 获取全局变量的字典
locals() # 获取执行本方法所在命名空间内的局部变量的字典
1.2 迭代器与生成器
next()iter()range
迭代器.__next__()
next(迭代器)
迭代器 = iter(可迭代的)
迭代器 = 可迭代的.__iter__()
range(10)
range(1, 11)
print("__iter__" in dir(range(1, 11, 2))) # True
print("__next__" in dir(range(1, 11, 2))) # False
print("__next__" in dir(iter(range(1, 11, 2)))) # True
# range 是可迭代的 但不是迭代器
1.3 其它
1.3.1 字符串类型代码的执行
内置函数——eval、exec、compile
eval()将字符串类型的代码执行并返回结果
print(eval('1+2+3+4'))
exec()将自字符串类型的代码执行
print(exec("1+2+3+4"))
exec("print('hello,world')")
- 指定global参数
code = '''
import os
print(os.path.abspath('.'))
'''
code = '''
print(123)
a = 20
print(a)
'''
a = 10
exec(code,{'print':print},)
print(a)
-
exec和eval都可以执行 字符串类型的代码 -
eval有返回值 ---- 有结果的简单计算 -
exec没有返回值 ---- 简单流程控制 -
eval只能用在你明确知道你要执行的代码是什么 -
compile将字符串类型的代码编译。代码对象能够通过exec语句来执行或者eval()进行求值。 -
参数说明:
-
- 参数
source:字符串或者AST(Abstract Syntax Trees)对象。即需要动态执行的代码段。
- 参数
-
- 参数
filename:代码文件名称,如果不是从文件读取代码则传递一些可辨认的值。当传入了source参数时,filename参数传入空字符即可。
- 参数
-
- 参数
model:指定编译代码的种类,可以指定为‘exec’,’eval’,’single’。当source中包含流程语句时,model应指定为‘exec’;当source中只包含一个简单的求值表达式,model应指定为‘eval’;当source中包含了交互式命令语句,model应指定为'single'。
- 参数
-
>>> #流程语句使用exec
>>> code1 = 'for i in range(0,10): print (i)'
>>> compile1 = compile(code1,'','exec')
>>> exec (compile1)
1
3
5
7
9
>>> #简单求值表达式用eval
>>> code2 = '1 + 2 + 3 + 4'
>>> compile2 = compile(code2,'','eval')
>>> eval(compile2)
>>> #交互语句用single
>>> code3 = 'name = input("please input your name:")'
>>> compile3 = compile(code3,'','single')
>>> name #执行前name变量不存在
Traceback (most recent call last):
File "<pyshell#29>", line 1, in <module>
name
NameError: name 'name' is not defined
>>> exec(compile3) #执行时显示交互命令,提示输入
please input your name:'pythoner'
>>> name #执行后name变量有值
"'pythoner'"
1.3.2 输入输出相关:
input()输入
# input 的用法
s = input("请输入内容 : ") #输入的内容赋值给s变量
print(s) #输入什么打印什么。数据类型是str
print()输出
# print 源码剖析
def print(self, *args, sep=' ', end='\n', file=None): # known special case of print
"""
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
file: 默认是输出到屏幕,如果设置为文件句柄,输出到文件
sep: 打印多个值之间的分隔符,默认为空格
end: 每一次打印的结尾,默认为换行符
flush: 立即把内容输出到流文件,不作缓存
"""
# file 关键字的说明
f = open('tmp_file','w')
print(123,456,sep=',',file = f,flush=True)
# 打印进度条
import time
for i in range(0,101,2):
time.sleep(0.1)
char_num = i//2 #打印多少个'*'
per_str = '\r%s%% : %s\n' % (i, '*' * char_num) if i == 100 else '\r%s%% : %s'%(i,'*'*char_num)
print(per_str,end='', flush=True)
#小越越 : \r 可以把光标移动到行首但不换行
# progress Bar
1.3.2 数据类型相关:
type(o)返回变量o的数据类型
1.3.3 内存相关:
-
id(o)o是参数,返回一个变量的内存地址 -
hash(o)o是参数,返回一个可hash变量的哈希值,不可hash的变量被hash之后会报错。
# hash 实例
t = (1,2,3)
l = [1,2,3]
print(hash(t)) #可hash
print(hash(l)) #会报错
'''
结果:
TypeError: unhashable type: 'list'
'''
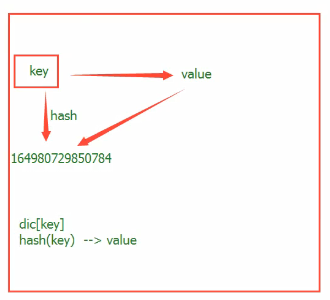
- hash函数会根据一个内部的算法对当前可hash变量进行处理,返回一个int数字。
- 每一次执行程序,内容相同的变量hash值在这一次执行过程中不会发生改变。
- 对于相应可
hash值在一次程序的执行过程中总是不会变的 - 字典的寻找方式
1.3.4 文件操作相关
open()打开一个文件,返回一个文件操作符(文件句柄)- 操作文件的模式有r,w,a,r+,w+,a+ 共6种,每一种方式都可以用二进制的形式操作(rb,wb,ab,rb+,wb+,ab+)
- 可以用encoding指定编码.
1.3.5 模块操作相关
__import__导入一个模块
# 导入模块
import time
# __import__
os = __import__('os')
print(os.path.abspath('.'))
1.3.6 帮助方法
- 在控制台执行
help()进入帮助模式。可以随意输入变量或者变量的类型。输入q退出 - 或者直接执行
help(o),o是参数,查看和变量o有关的操作。。。
1.3.7 和调用相关
callable(o),o是参数,看这个变量是不是可调用。- 如果o是一个函数名,就会返回True
# callable 实例
def func():pass
print(callable(func)) #参数是函数名,可调用,返回True
print(callable(123)) #参数是数字,不可调用,返回False
1.3.8 查看参数所属类型的所有内置方法
dir()默认查看全局空间内的属性,也接受一个参数,查看这个参数内的方法或变量
# 查看某变量/数据类型的内置方法
print(dir(list)) #查看列表的内置方法
print(dir(int)) #查看整数的内置方法
1.4 和数字相关
1.4.1 数据类型相关
bool根据传入的参数的逻辑值创建一个新的布尔值
>>> bool()
False
>>> bool(1)
True
>>> bool(0) #数值0、空序列等值为False
False
>>> bool('str')
True
int根据传入的参数创建一个新的整数
>>> int() #不传入参数时,得到结果0。
0
>>> int(3)
3
>>> int(3.6)
3
float根据传入的参数创建一个新的浮点数
>>> float() #不提供参数的时候,返回0.0
0.0
>>> float(3)
3.0
>>> float('3')
3.0
complex根据传入参数创建一个新的复数,复数在python里单位为j
>>> complex() #当两个参数都不提供时,返回复数 0j。
0j
>>> complex('1+2j') #传入字符串创建复数
(1+2j)
>>> complex(1,2) #传入数值创建复数
(1+2j)
1.4.2 进制转换相关
bin将整数转换成2进制字符串
>>> bin(3) #0b为默认
'0b11'
oct将整数转化成8进制数字符串
>>> oct(10)
'0o12'
hex将整数转换成16进制字符串
>>> hex(15)
'0xf'
1.4.3 数学运算
abs求数值的绝对值
>>> abs(-2)
2
divmod返回两个数值的商和余数
>>> divmod(10,3)
(3, 1)
min返回可迭代对象的元素中的最小值或者所有参数的最小值
>>> min(-1,12,3,4,5)
-1
>>> min('1234545')
'1'
>>> min(-1,0,key=abs)
0
max返回可迭代对象的元素中的最大值或者所有参数的最大值
>>> max(-1,1,2,3,4) #传入多个参数 取其中较大者
4
>>> max('1245657') #传入1个可迭代对象,取其最大元素值
'7'
>>> max(-1,0,key=abs) #传入了求绝对值函数,则参数都会进行求绝对值后再取较大者
-1
sum对元素类型是数值的可迭代对象中的每个元素求和
>>> sum((1,2,3,4))
10
>>> sum([1,2,3,4])
10
>>> sum((1.1,1.2,1.3))
3.5999999999999996
>>> sum((1,2,3,4),-10)
0
>>> sum((1,2,3,4),3)
13
>>> sum((1,2,3,4),5)
15
round对浮点数进行四舍五入求值
>>> round(1.456778888)
1
>>> round(1.4567787888,2)
1.46
pow取两个值的幂运算值,或与其他
>>> pow(2,3) # pow 幂运算 === 2**3
8
>>> pow(2,3,5) #取(2,3)%5 取模就是余数
3
>>> pow(2,3,4)
0
>>> pow(2,3,3)
2
1.5 和数据结构相关
1.5.1 序列
reversed:反转序列生成新的可迭代对象
>>> lis = [1, 2, 3, 4, 5]
>>> lis2 = reversed(lis)
>>> print(lis2) # 保留原列表,返回一个反向迭代器
<list_reverseiterator object at 0x7f2aec656198>
>>> for i in lis2:
... print(i)
...
5
4
3
2
1
slice:根据传入的参数创建一个新的切片对象
>>> l = (1,2,23,213,5612,342,43)
>>> sli = slice(1,5,2)
>>> print(l[sli])
(2, 213)
>>> print(l[1:5:2])
(2, 213)
列表和元组相关的
list:根据传入的参数创建一个新的列表
>>>list() # 不传入参数,创建空列表
[]
>>> list('abcd') # 传入可迭代对象,使用其元素创建新的列表
['a', 'b', 'c', 'd']
tuple:根据传入的参数创建一个新的元组
>>> tuple() #不传入参数,创建空元组
()
>>> tuple('121') #传入可迭代对象。使用其元素创建新的元组
('1', '2', '1')
字符串相关
str:返回一个对象的字符串表现形式(给用户)
>>> str()
''
>>> str(None)
'None'
>>> str('abc')
'abc'
>>> str(123)
'123'
format:格式化显示值-
- 函数功能将一个数值进行格式化显示。
-
- 如果参数format_spec未提供,则和调用str(value)效果相同,转换成字符串格式化。
-
>>> format(3.1415936)
'3.1415936'
>>> str(3.1415926)
'3.1415926'
3. 对于不同的类型,参数format_spec可提供的值都不一样
#字符串可以提供的参数,指定对齐方式,<是左对齐, >是右对齐,^是居中对齐
print(format('test', '<20'))
print(format('test', '>20'))
print(format('test', '^20'))
#整形数值可以提供的参数有 'b' 'c' 'd' 'o' 'x' 'X' 'n' None
>>> format(3,'b') #转换成二进制
'11'
>>> format(97,'c') #转换unicode成字符
'a'
>>> format(11,'d') #转换成10进制
'11'
>>> format(11,'o') #转换成8进制
'13'
>>> format(11,'x') #转换成16进制 小写字母表示
'b'
>>> format(11,'X') #转换成16进制 大写字母表示
'B'
>>> format(11,'n') #和d一样
'11'
>>> format(11) #默认和d一样
'11'
#浮点数可以提供的参数有 'e' 'E' 'f' 'F' 'g' 'G' 'n' '%' None
>>> format(314159267,'e') #科学计数法,默认保留6位小数
'3.141593e+08'
>>> format(314159267,'0.2e') #科学计数法,指定保留2位小数
'3.14e+08'
>>> format(314159267,'0.2E') #科学计数法,指定保留2位小数,采用大写E表示
'3.14E+08'
>>> format(314159267,'f') #小数点计数法,默认保留6位小数
'314159267.000000'
>>> format(3.14159267000,'f') #小数点计数法,默认保留6位小数
'3.141593'
>>> format(3.14159267000,'0.8f') #小数点计数法,指定保留8位小数
'3.14159267'
>>> format(3.14159267000,'0.10f') #小数点计数法,指定保留10位小数
'3.1415926700'
>>> format(3.14e+1000000,'F') #小数点计数法,无穷大转换成大小字母
'INF'
#g的格式化比较特殊,假设p为格式中指定的保留小数位数,先尝试采用科学计数法格式化,得到幂指数exp,如果-4<=exp<p,则采用小数计数法,并保留p-1-exp位小数,否则按小数计数法计数,并按p-1保留小数位数
>>> format(0.00003141566,'.1g') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留0位小数点
'3e-05'
>>> format(0.00003141566,'.2g') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留1位小数点
'3.1e-05'
>>> format(0.00003141566,'.3g') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留2位小数点
'3.14e-05'
>>> format(0.00003141566,'.3G') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留0位小数点,E使用大写
'3.14E-05'
>>> format(3.1415926777,'.1g') #p=1,exp=0 ==》 -4<=exp<p成立,按小数计数法计数,保留0位小数点
'3'
>>> format(3.1415926777,'.2g') #p=1,exp=0 ==》 -4<=exp<p成立,按小数计数法计数,保留1位小数点
'3.1'
>>> format(3.1415926777,'.3g') #p=1,exp=0 ==》 -4<=exp<p成立,按小数计数法计数,保留2位小数点
'3.14'
>>> format(0.00003141566,'.1n') #和g相同
'3e-05'
>>> format(0.00003141566,'.3n') #和g相同
'3.14e-05'
>>> format(0.00003141566) #和g相同
'3.141566e-05'
bytes:字节编码

>>> bytes("你好", encoding="GBK") # unicode 转换成 GBK 的 bytes 编码
b'\xc4\xe3\xba\xc3'
>>> bytes("你好", encoding="utf-8") # unicode 转换成 utf-8 的 bytes 编码
b'\xe4\xbd\xa0\xe5\xa5\xbd'
>>> bytes("你好", encoding="GBK").decode("GBK") # unicode 转换成 GBK 的 bytes 编码,decode 解码为 unicode
'你好'
bytearry:
>>> ret = bytearray('alex',encoding='utf-8')
>>> print(id(ret))
139822331421112
>>> print(ret[0])
97
>>> ret[0] = 65
>>> print(ret)
bytearray(b'Alex')
>>> print(id(ret))
139822331421112
memoryview: 根据传入的参数创建一个新的内存查看对象
>>> ret = memoryview(bytes('你好',encoding='utf-8'))
>>> print(len(ret))
6
>>> print(bytes(ret[:3]).decode('utf-8'))
你
>>> print(bytes(ret[3:]).decode('utf-8'))
好
ord:返回Unicode字符对应的整数
>>> ord('a')
97
chr:返回整数所对应的Unicode字符
>>> chr(97) #参数类型为整数
'a'
ascii:只要是ascii码中的内容,就打印出来,不是就转出\u
>>> ascii(1)
'1'
>>> ascii('&')
"'&'"
>>> ascii(9000000)
'9000000'
>>> ascii('中文') #非ascii字符
"'\\u4e2d\\u6587'"
repr用于%r 格式化输出,返回一个对象原有的类型
>>> name = "egg"
>>> print("你好 %s" % name)
你好 egg
>>> print("你好 %r" % name)
你好 'egg'
>>> print(repr("1"))
'1'
>>> print(repr(1))
1
1.5.2 数据集合
dict:根据传入的参数创建一个新的字典
>>> dict() # 不传入任何参数时,返回空字典。
{}
>>> dict(a = 1,b = 2) # 可以传入键值对创建字典。
{'b': 2, 'a': 1}
>>> dict(zip(['a','b'],[1,2])) # 可以传入映射函数创建字典。
{'b': 2, 'a': 1}
>>> dict((('a',1),('b',2))) # 可以传入可迭代对象创建字典。
{'b': 2, 'a': 1}
set:根据传入的参数创建一个新的集合
>>>set() # 不传入参数,创建空集合
set()
>>> a = set(range(10)) # 传入可迭代对象,创建集合
>>> a
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
frozenset:根据传入的参数创建一个新的不可变集合
>>> a = frozenset(range(10))
>>> a
frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9})
len:返回对象的长度
>>> len('abcd') # 字符串
>>> len(bytes('abcd','utf-8')) # 字节数组
>>> len((1,2,3,4)) # 元组
>>> len([1,2,3,4]) # 列表
>>> len(range(1,5)) # range对象
>>> len({'a':1,'b':2,'c':3,'d':4}) # 字典
>>> len({'a','b','c','d'}) # 集合
>>> len(frozenset('abcd')) #不可变集合
enumerate:根据可迭代对象创建枚举对象
>>> seasons = ['Spring', 'Summer', 'Fall', 'Winter']
>>> list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
>>> list(enumerate(seasons, start=1)) #指定起始值
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
all:判断可迭代对象的每个元素是否都为True值,有一个为False,则返回False
>>> all([1,2]) #列表中每个元素逻辑值均为True,返回True
True
>>> all([0,1,2]) #列表中0的逻辑值为False,返回False
False
>>> all(()) #空元组
True
>>> all({}) #空字典
True
any:判断可迭代对象的元素是否有为True值的元素,有一个为True,则返回True
>>> any([0,1,2]) #列表元素有一个为True,则返回True
True
>>> any([0,0]) #列表元素全部为False,则返回False
False
>>> any([]) #空列表
False
>>> any({}) #空字典
False
zip:聚合传入的每个迭代器中相同位置的元素,返回一个新的元组类型迭代器
>>> x = [1,2,3] #长度3
>>> y = [4,5,6,7,8] #长度5
>>> list(zip(x,y)) # 取最小长度3
[(1, 4), (2, 5), (3, 6)]
>>> lis = [1, 2, 3]
>>> lis2 = ["a", "b", "c"]
>>> for i in zip(lis, lis2):
... print(i)
...
(1, 'a')
(2, 'b')
(3, 'c')
filter()filter()函数接收一个函数 f 和一个list,这个函数 f 的作用是对每个元素进行判断,返回 True或 False,filter()根据判断结果自动过滤掉不符合条件的元素,返回由符合条件元素组成的新list。- filter 执行了filter之后的结果集合 《== 执行之前的个数
- filter 只管筛选,不会改变原来的值
# 例如,要从一个list [1, 4, 6, 7, 9, 12, 17]中删除偶数,保留奇数,首先,要编写一个判断奇数的函数:
def is_odd(x):
return x % 2 == 1
# 然后,利用filter()过滤掉偶数:
>>>list(filter(is_odd, [1, 4, 6, 7, 9, 12, 17]))
# 结果:
[1, 7, 9, 17]
# 利用filter(),可以完成很多有用的功能,例如,删除 None 或者空字符串:
def is_not_empty(s):
return s and len(s.strip()) > 0
>>>list(filter(is_not_empty, ['test', None, '', 'str', ' ', 'END']))
# 结果:
['test', 'str', 'END']
# 注意: s.strip(rm) 删除 s 字符串中开头、结尾处的 rm 序列的字符。
# 当rm为空时,默认删除空白符(包括'\n', '\r', '\t', ' '),如下:
>>> a = ' 123'
>>> a.strip()
'123'
>>> a = '\t\t123\r\n'
>>> a.strip()
'123'
# 请利用filter()过滤出1~100中平方根是整数的数,即结果应该是:
# [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
#方法:
import math
def is_sqr(x):
return math.sqrt(x) % 1 == 0
print(list(filter(is_sqr, range(1, 101))))
# 结果:
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
map- Python中的map函数应用于每一个可迭代的项,返回的是一个结果list。如果有其他的可迭代参数传进来,map函数则会把每一个参数都以相应的处理函数进行迭代处理。map()函数接收两个参数,一个是函数,一个是序列,map将传入的函数依次作用到序列的每个元素,并把结果作为新的list返回。
- map 执行前后元素的个数不变
- 值可能发生变化
有一个list, L = [1,2,3,4,5,6,7,8],我们要将f(x)=x^2作用于这个list上,那么我们可以使用map函数处理。
>>> L = [1,2,3,4,]
>>> def pow2(x):
... return x*x
...
>>> list(map(pow2,L))
[1, 4, 9, 16]
>>> ret = map(abs, [1, -4, 6, -8])
>>> print(ret)
<map object at 0x7f2ae490af28>
>>> for i in ret:
... print(i)
...
1
4
6
8
sorted- 对List、Dict进行排序,Python提供了两个方法
- 对给定的List L进行排序,
- 方法1.用List的成员函数sort进行排序,在本地进行排序,不返回副本
- 方法2.用built-in函数sorted进行排序(从2.4开始),返回副本,原始输入不变
- 参数说明:
- iterable:是可迭代类型;
- key:传入一个函数名,函数的参数是可迭代类型中的每一项,根据函数的返回值大小排序;
- reverse:排序规则. reverse = True 降序 或者 reverse = False 升序,有默认值。
- 返回值:有序列表
--------------------------------sorted---------------------------------------
sorted(iterable, key=None, reverse=False)
Return a new list containing all items from the iterable in ascending order.
A custom key function can be supplied to customise the sort order, and the
reverse flag can be set to request the result in descending order.
# 列表按照其中每一个值的绝对值排序
l1 = [1,3,5,-2,-4,-6]
l2 = sorted(l1,key=abs)
print(l1)
print(l2)
#列表按照每一个元素的len排序
l = [[1,2],[3,4,5,6],(7,),'123']
print(sorted(l,key=len))
2,匿名函数
- 匿名函数:为了解决那些功能很简单的需求而设计的一句话函数
#这段代码
def calc(n):
return n**n
print(calc(10))
#换成匿名函数
calc = lambda n:n**n
print(calc(10))

- 上面是我们对calc这个匿名函数的分析,下面给出了一个关于匿名函数格式的说明
函数名 = lambda 参数 :返回值
#参数可以有多个,用逗号隔开
#匿名函数不管逻辑多复杂,只能写一行,且逻辑执行结束后的内容就是返回值
#返回值和正常的函数一样可以是任意数据类型
- 匿名函数并不是真的不能有名字。
- 匿名函数的调用和正常的调用也没有什么分别。 就是 函数名(参数)
# 请把以下函数变成匿名函数
def add(x,y):
return x+y
>>> add = lambda x,y:x+y
>>> print(add(1,2))
3
>>> l=[3,2,100,999,213,1111,31121,333]
>>> print(max(l))
31121
>>> dic={'k1':10,'k2':100,'k3':30}
>>> print(max(dic))
k3
# >>> def func(key):
# ... return dic[key]
# ...
# >>> print(max(dic,key=func))
# k2
>>> print(max(dic,key=lambda k: dic[k]))
k2
>>> print(dic[max(dic,key=lambda k:dic[k])])
100
# 1.下面程序的输出结果是:
d = lambda p:p*2
t = lambda p:p*3
x = 2
x = d(x) # x =4
x = t(x) # x = 12
x = d(x) # x = 24
print(x)
#2.现有两元组(('a'),('b')),(('c'),('d')),请使用python中匿名函数生成列表[{'a':'c'},{'b':'d'}]
# max min sorted filter map
# 匿名函数 == 内置函数
# zip
ret = zip((('a'),('b')),(('c'),('d')))
# def func(tup):
# return {tup[0]:tup[1]}
# res = map(func, ret)
res = map(lambda tup:{tup[0]:tup[1]}, ret)
print(list(ret))
# print(list(map(lambda tup:{tup[0]:tup[1]}, zip((('a'),('b')),(('c'),('d'))))))
# 结果呈现
[('a', 'c'), ('b', 'd')]
# 3.以下代码的输出是什么?请给出答案并解释。
def multipliers():
return [lambda x:i*x for i in range(4)]
print([m(2) for m in multipliers()])
# 结果呈现
[6, 6, 6, 6]
4,本章小结
- 重点掌握:
- 其他:input,print,type,hash,open,import,dir
- str类型代码执行:eval,exec
- 数字:bool,int,float,abs,divmod,min,max,sum,round,pow
- 序列——列表和元组相关的:list和tuple
- 序列——字符串相关的:str,bytes,repr
- 序列:reversed,slice
- 数据集合——字典和集合:dict,set,frozenset
- 数据集合:len,sorted,enumerate,zip,filter,map
- 参考文档:
5,相关练习题
1,用map来处理字符串列表,把列表中所有人都变成R,比方Luffy_R
name = ["Luffy", "Zoro", "Nami", "Usopp", "Sanji", ""]
# def func(item):
# return item+"_R"
#
# ret = map(func,name) # ret 迭代器
#
# for i in ret:
# print(i)
#
# print(list(ret))
ret = map(lambda item:item + "_R", name)
print(list(ret))
# 结果呈现
['Luffy_R', 'Zoro_R', 'Nami_R', 'Usopp_R', 'Sanji_R', '_R']
2, 用filter函数处理数字列表,将列表中所有的偶数筛选出来
num = [1, 3, 5, 6, 7, 8]
# def func(x):
# return x % 2 == 0
#
# ret = filter(func, num) # ret 是迭代器
# print(list(ret))
ret = filter(lambda x:x % 2 == 0, num)
ret = filter(lambda x:True if x % 2 == 0 else False, num)
print(list(ret))
# 结果呈现
[6, 8]
3,随意写一个20行以上的文件,运行程序,先对内容读到内存中,用列表存储,接收用户输入页码,每页5条,仅输出当页的内容
with open("page_file",encoding="utf-8") as f :
lis = f.readlines()
page_num = int(input("请输入页码:"))
print(page_num)
pages,mod = divmod(len(lis),5) # 求有多少页,有没有剩余的行数
if mod: # 如果有剩余的行数,那么页数加一
pages += 1 # 一共多少页
if page_num > pages or page_num <= 0 : # 用户输入的页数大于总数
print("输入有误")
elif page_num == pages and mod != 0: # 如果用户输入的页码是最后一页,且之前有过剩余行数
for i in range(mod):
print(lis[(page_num - 1) * 5 + i].strip()) # 只输出这一页上的剩余的行
else:
for i in range(5):
print(lis[(page_num - 1) * 5 + i].strip()) # 输出5行
# 结果呈现
请输入页码:1
1
1,“草帽”蒙奇·D·路飞(モンキーD·ルフィ/Monkey D. Luffy) [12]
2,初次登场:漫画第1话
3,年龄:17岁→19岁
4,生日:5月5日
5,血型:F型
# page_file
1,“草帽”蒙奇·D·路飞(モンキーD·ルフィ/Monkey D. Luffy) [12]
2,初次登场:漫画第1话
3,年龄:17岁→19岁
4,生日:5月5日
5,血型:F型
6,身高:172cm→174cm
7,故乡:东海·风车村
8,身份:草帽海贼团船长
9,喜欢的食物:所有美食,首先是肉。
10,爱好:喜欢探险,感兴趣于新奇怪异的事物
11,梦想:找到ONE PIECE,并成为海贼王。
12,恶魔果实:超人系橡胶果实
13,身世:父亲是革命军首领蒙奇·D·龙,爷爷是海军中将英雄卡普。
14,悬赏:3千万(可可亚西村事件)→1亿(阿拉巴斯坦事件)→3亿(司法岛事件)→4亿(顶上战争)→5亿(德雷斯罗萨篇)→15亿(蛋糕岛事件)
15,由于他的标志性特征是一顶草帽,因此常被直接称呼为“草帽”。梦想是找到传说中的ONE PIECE,成为海贼王。性格积极乐观,爱憎分明且十分重视伙伴,对任何危险的事物都超感兴趣。看似白痴,却是一个大智若愚型的无愧船长之职的人。和其他传统的海贼所不同的是,他并不会为了追求财富而无故杀戮,而是享受着身为海贼的冒险。 [13]
16,“海贼猎人”罗罗诺亚·索隆(ロロノア·ゾロ/Roronoa Zoro) [14]
17,初次登场:漫画第3话
18,年龄:19岁→21岁
19,生日:11月11日
20,血型:XF型
21,故乡:东海·霜月村
22,身份:东海海贼赏金猎人→草帽海贼团战斗员
23,身高:178cm→181cm
24,喜欢的食物:白米,海兽的肉,适合下酒的食物
25,爱好:睡觉、修炼、喝酒。
26,缺点:路痴
27,梦想:世界第一大剑豪
28,悬赏:6千万(阿拉巴斯坦事件)→1亿2000万(司法岛事件)→3亿2000万(德雷斯罗萨篇)
29,爱喝酒,爱睡觉,讲义气,海贼第一超级大路痴。为了小时候与挚友的约定而踏上了前往世界第一剑士的道路,随后成为路飞出海后遇到的第一个伙伴。在初次败给世界第一剑士“鹰眼米霍克”后向路飞发誓永不再败,并且更加努力的锻炼自己。两年后的他成功与伙伴们汇合,并且为了实现自己的梦想,奔赴强者如云的新世界。 [13]
4,如下,每个小字典的name对应股票的名字,shares对应多少股,price对应股票的价格
portfolio = [
{"name": "IBM", "shares": 100, "price": 91.1},
{"name": "AAPL", "shares": 50, "price": 543.22},
{"name": "FB", "shares": 200, "price": 21.09},
{"name": "HPQ", "shares": 35, "price": 31.75},
{"name": "YHOO", "shares": 45, "price": 16.35},
{"name": "ACME", "shares": 75, "price": 115.65},
]
4.1 计算购买每支股票的总价
result = map(lambda dic: {dic["name"]:round(dic["shares"] * dic["price"])},portfolio)
print(list(result))
# 结果呈现
[{'IBM': 9110}, {'AAPL': 27161}, {'FB': 4218}, {'HPQ': 1111}, {'YHOO': 736}, {'ACME': 8674}]
4.2 用filter过滤出,单价大于100的股票有哪些
ret = filter(lambda dic: True if dic["price"] > 100 else False, portfolio)
print(list(ret))
ret = filter(lambda dic: dic["price"] > 100, portfolio)
print(list(ret))
# 结果呈现
[{'name': 'AAPL', 'shares': 50, 'price': 543.22}, {'name': 'ACME', 'shares': 75, 'price': 115.65}]
[{'name': 'AAPL', 'shares': 50, 'price': 543.22}, {'name': 'ACME', 'shares': 75, 'price': 115.65}]
