SQL语法
SQL基本语法
DDL
操作数据库
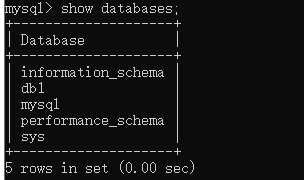
- 查看数据库: show databases;
- 创建数据库并且判断这个数据库是否存在:create database if not exists 名字;

-
删除数据库并判断这个数据库是否存在:drop database if exists 名字;

-
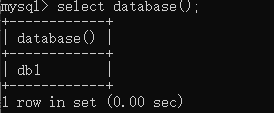
查看正在使用的数据库: select database();
-
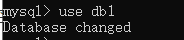
使用数据库:use 数据库名字;
操作表
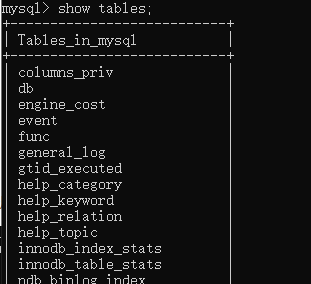
查看当前数据库的表:show tables;
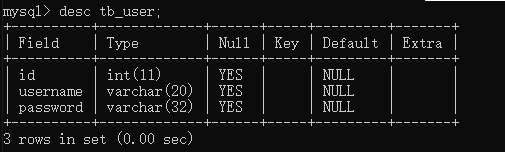
查看表的结构 desc 表名;
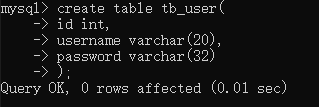
创建表:create table 表名(
字段名1 数据类型1,
字段名2 数据类型2,
字段名3 数据类型3
.......
)
修改表
- 修改表名:ALTER TABLE 表名 RENAME TO 新的表名;
ALTER TABLE stu_info RENAME TO stu;
- 添加一列:ALTER table 表明 ADD 列名 数据类型;
ALTER table stu ADD NO int;
- 修改列名和数据类型:ALTER table 表名 change 列名 新列名 新数据类型;
ALTER table stu changge no no2 VARCHAR(20);
- 删除列: ALTER TABLE 表名 drop 列名;
ALTER TABLE stu drop NO;
- 修改数据类型ALTER table 表名 MODIFY 列名 新数据类型;
ALTER table stu MODIFY no VARCHAR(20);
DML
添加数据
- 给指定列添加数据:INSERT into 表名(列名1,列名2.....) values(值1,值2);
INSERT into stu(id,name) values(3,'张三2');
- 给所有列添加数据: INSERT into 表名 VALUES(值1,值2,.....);
INSERT into stu VALUES(100,'李四',12);
- 添加多条数据:INSERT into 表名 VALUES(值1,值2,.....),(值1,值2,.....),(值1,值2,.....);
INSERT into stu VALUES(100,'李四',12),(100,'李四',12),(100,'李四',12),(100,'李四',12);
修改数据
- 修改数据:UPDATE 表名 SET 列名1=值1,列名2=值2 WHERE 列=值;
- 如果不写where 会将所有的数据都修改
PDATE stu set math_score=70 WHERE id BETWEEN 1 and 20;
删除数据
- 删除数据delete from 表名 where 列=值;
DELETE from stu where name="张三2"
如果不写where将会删除所有数据
DQL
- 查询语句:
- SELECT 字段列表 FROM 表名列表 WHERE 条件列表 GROP BY 分组字段 HAVING 分组后条件 ORDER BY 排序字段 LIMIT 分页限定
基础查询
- 查询指定列表所有的值:SELECT 列名1,列名2 from 表名;
SELECT name from stu;
- 去除重复的值:SELECT DISTINCT 列名1,列名2 from 表名;
SELECT DISTINCT name from stu;
- 可以给查询的列取别名 SELECT 列名1 as 别名1,列名2 as 别名2 from 表名;
SELECT name (as) 名字 ,id (as) 学号 from stu;

条件查询
SELECT id , name from stu where id>2; -- 查询id大于2的数据的id 和名字
SELECT num , name from stu where num>10 and num<120; -- 查询num值在10到120的数据的num和name
SELECT num , name from stu where num between 12 and 104;、-- 查询num值在12到104的数据的num和name 包括12和104
SELECT num , name from stu where num =12 or num=13 or num=15; -- 查询num值为12 13 15的数据的num和name
SELECT num , name from stu where num in(12,13,15)-- 查询num值为12 13 15的数据的num和name
SELECT num , name from stu where num IS (NOT) null; -- 查询num不为空的数据的num 和name 注意:null只能是is null 或者is not null 不能用=
模糊查询:
SELECT num , name from stu where name like "李%" -- 查询name第一个字为李的数据的num和名字
SELECT num , name from stu where name like "_李%" -- 查询nam第二字为李的数据的num和名字
SELECT num , name from stu where name like "%李%" -- 查询nam包含李字的数据的num和名字
排序查询
SELECT id ,name FROM stu ORDER BY id (asc); -- 按照id的升序来查找
SELECT id ,name FROM stu ORDER BY id desc; -- 按照id的降序来排列
SELECT id ,name FROM stu ORDER BY id desc,num asc; -- 按照id的降序来排列,如果id一样 按照num的升序排序
分组查询
聚合函数
- 将一列数据作为一个整体,进行纵向计算
- 聚合函数分类:
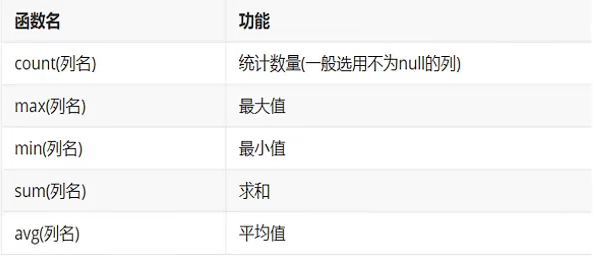
用法: select 聚合函数名(列名) from 表;
SELECT AVG(math_score) from stu; -- 查询math_score的平均数
SELECT sum(math_score) from stu; -- 查询math_score的和
SELECT max(math_score) from stu; -- 查询math_score的最大值
SELECT min(math_score) from stu; -- 查询math_score的最小值
分组查询
分组查询: select 字段 聚合函数 from 表名 (where 限制条件)group by 字段 having 分组后条件过滤;
SELECT sex ,AVG(math_score) ,COUNT(*) from stu GROUP BY sex; -- 查询数学成绩的平均值 按照性别分组 注意:分组以后 查询的字段为聚合函数和分组字段,查询其他字段无任何意义
SELECT sex ,AVG(math_score) ,COUNT(*) from stu where math_score > 50 GROUP BY sex having count(*)>4; -- 查询数学成绩平均分和总人数,只查询分数大于50 并且人数大于4的组
where和having的区别:
- 执行时机不一样,where是在分组以前限定,不满足where条件的不参与分组,而having是在分组以后对结果进行过滤
- 可判断的条件不一样,where不能对聚合函数进行判断,having可以
执行顺序:where》 聚合函数》having
分页查询
语法:select 列名 FROM 表名 LIMIT 起始索引 , 每业数据个数
select * FROM stu LIMIT 0 ,3
起始索引=(当前页码-1)*每页条数
- 分页查询mysql使用的是limit oracle使用的是rownnumber sqlserver使用的是top
约束
- 约束的概念:
-
- 约束是作用于表中列上的规则,用于限制加入表的数据
- 约束的存在保证了数据库中数据的正确性,有效性和完整性
- 约束的分类
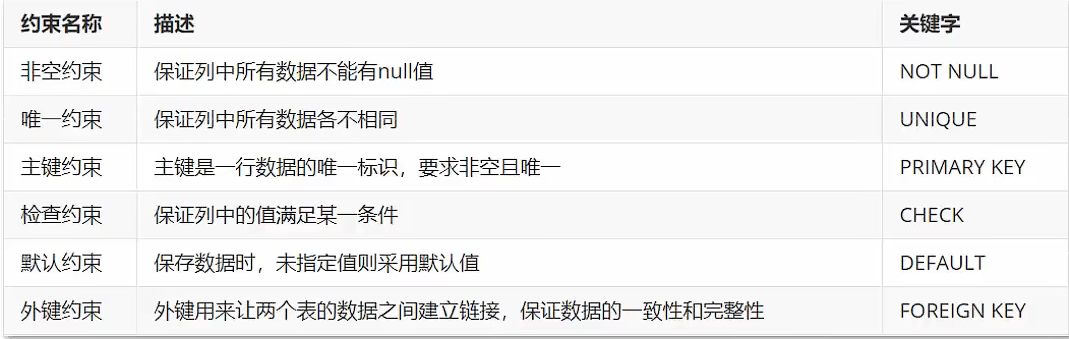
auto_increment :当列是数字,并且为唯一约束的时候 自动增长
外键
- 添加外键:ALTER table 表名 add CONSTRAINT 外键名 FOREIGN key(外键字段名称) REFERENCES 主表名称 (主表字段名称);
ALTER table emp add CONSTRAINT fk_emp_dept FOREIGN key(dep_id) REFERENCES dept(id); -- 添加外键fk_emp_dept
- 删除外键:alter table 表名 drop FOREIGN key 外键名;
alter table emp drop FOREIGN key fk_emp_dept; -- 删除外键fk_emp_dept
数据库设计
- 建立数据库中的表结构以及表与表之间的关联关系的过程
- 设计步骤:
-
- 需求分析:数据是什么,数据具有哪些属性?数据与属性的特点是什么
- 逻辑分析:通过ER图对数据库进行逻辑建模,不需要考虑我们所选用的数据库管理系统
- 物理设计:根据数据库自身的特点把逻辑设计转化为物理设计
- 维护设计:对新的需求进行建表 表优化等
多表查询
内连接
- 隐式内连接:SELECT 字段名 FROM 表名,表名 where 条件;‘
select a.id,a.name,b.dep_name,b.addr from emp a, dept b where a.dep_id=b.id; -- 给emp取名为a dept取名为b 并查询a中的name id 字段 b 中的addr dep_name字段
- 显式内链接: SELECT 字段名 FORM 表名(INNER) JOIN 表名 ON 条件;
SELECT
a.id,
a.NAME,
b.dep_name,
b.addr
FROM
emp a
INNER JOIN dept b ON a.dep_id = b.id;
外连接
- 左外连接:SELECT 字段名 from 表名 LEFT JOIN 表名 on 条件(查询做表的全部信息和对应的右表信息)
SELECT * from emp LEFT JOIN dept on emp.dep_id=dep_id;
- 右外连接:SELECT 字段名 from 表名RIGHT JOIN 表名 on 条件
SELECT 字段名 from 表名 RIGHT JOIN 表名 on 条件
子查询
- 单行单列: SELECT 字段名 from 表名 where 条件=(子查询 );
SELECT * from emp where emp.dep_id=(SELECT id FROM dept where dep_name='研发部' );
- 多行单列:SELECT 字段名 from 表名 in 条件=(子查询 );
SELECT * from emp where emp.dep_id in (SELECT id FROM dept where dep_name='研发部' or dep_name='销售部' );
- 多行多列:SELECT 字段名 from (子查询) where 条件;
SELECT a.name, b.dep_name FROM emp a, (SELECT * from dept where dep_name='研发部') b where a.dep_id=b.id;
’
事务
- 数据库的事务是一种机制,一个操作序列,包含了一组数据库操作命令
- 事务所有的命令作为一个整体一起向系统提交或撤销操作请求,即一组数据库命令要么同时成功要么同时失败
- 事务是一个不可分割的工作逻辑单元
- 例子:
BEGIN;
-- 开启事务
-- 李四金额-500
UPDATE account set money =money-500 where name='李四';
-- 出错了
-- 张三金额+500
UPDATE account set money =money+500 where name='张三';
-- 提交事务
commit;
-- 回滚事务
Rollback;
事物的四大特征
- 原子性(Atomicity):事务是不可分割的最小操作单位,要么同时成功要么同时失败
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态
- 隔离型(Isolation):多个事务之间,操作的可见性
- 持久性(DUrability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号