MongoDB学习5:模型设计和设计模式
1.数据模型
1.1 什么是数据模型?
数据模型是一组由符号、文本组成的集合,用以准确表达信息,达到有效交流、沟通的目的
1.2 数据模型设计元素
- 实体 Entity
- 描述业务的主要数据集合
- 属性 Attribute
- 描述实体里面的单个属性
- 关系 Relationship
- 描述实体与实体之间的数据规则
- 结构规则:1-N N-1 N-N
- 引用规则:比如电话号码不能单独存在,必须依赖于具体的人
2.JSON文档模型设计特点
2.1 MongoDB文档模型设计的三个误区
- 不需要模型设计
- MongoDB应该用一个超级大文档来组织所有数据
- MongoDB不支持关联或者事务
2.2 为什么说MongoDB是无模式的
- 严格来说,MongoDB同样需要概念/逻辑建模
- 文档模型设计的物理层结构可以和逻辑层类似
- 可以省略物理建模的具体过程
2.3 文档设计模式原则:性能和易用
2.4 关系模型 vs 文档模型
| 关系数据库 | JSON文档模型 | |
|---|---|---|
| 模型设计层次 | 概念模型、逻辑模型、物理模型 | 概念模型、逻辑模型 |
| 模型实体 | 表 | 集合 |
| 模型属性 | 列 | 字段 |
| 模型关系 | 关联关系,主外键 | 内嵌数组、引用字段 |
3.MongoDB文档模型设计三部曲
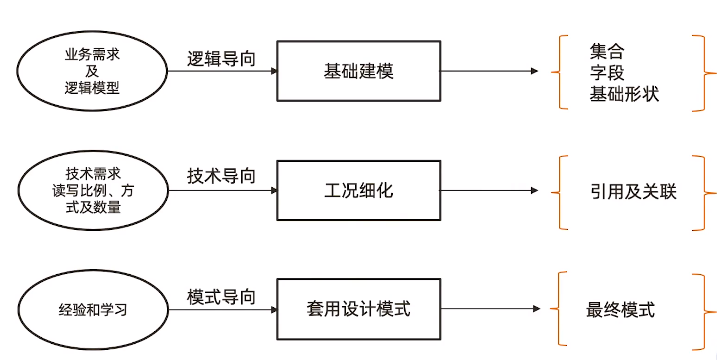
3.1 建立基础文档模型
-
根据概念模型或者业务需求推导出逻辑模型 -找到对象
-
列出实体之间的关系 -明确关系
-
套用逻辑设计原则来决定内嵌方式 -进行建模
-
完成基础模型构建

-
一个联系人管理应用的例子
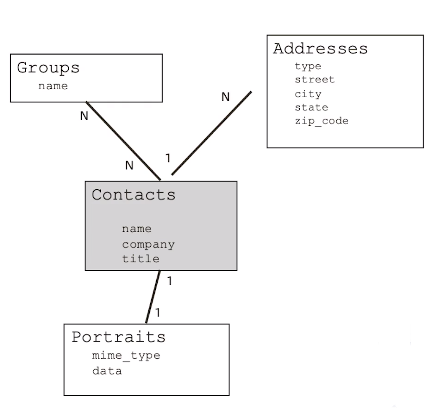
- 1.找到对象
-- Contacts
-- Group
-- Address
-- Portraits - 2.明确关系
-- 一个联系人有1个头像 (1-1)
-- 一个联系人可以有多个地址 (1-N)
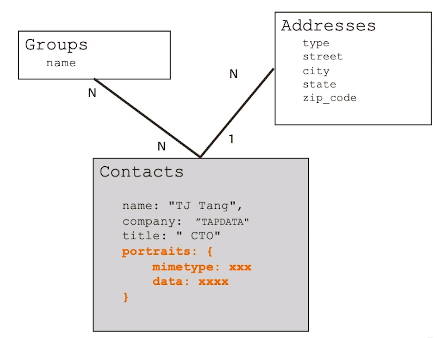
-- 一个联系人可以属于多个组,一个组可以有多个联系人(N-N) - 3.关系建模(1-1):Portraits
-- 基本原则:一对一关系以内嵌为主,作为子文档形式或者直接在顶级,不涉及到数据冗余
-- 例外情况:如果内嵌后导致文档大小超过16MB
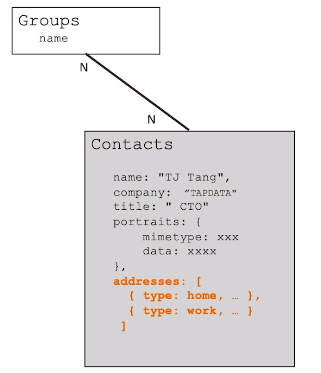
- 4.关系建模(1-N):Address
-- 基本原则:一对多关系同样以内嵌为主,用数组来表示一对多,不涉及到数据冗余
-- 例外情况:内嵌后导致文档大小超过16MB、数组长度太大(数万或更多)、数组长度不确定
- 5.关系建模(N-N):Groups
-- 基本原则:不需要映射表,一般用内嵌数组来表示一对多,通过冗余来实现N-N
-- 例外情况:内嵌后导致文档大小超过16MB、数组长度太大(数万或更多)、数组长度不确定

- 1.找到对象
3.2 根据读写工况细化
-
联系管理应用的分组需求
Q : 假如有千万级联系人;需要频繁变动分组的信息,比如增加分组及修改名称及描述以及营销状态;一个分组有百万级联系人,如何解决?
A : Group使用单独的集合

-
什么时候应该使用引用方式?
- 内嵌文档太大,数MB或者超过16MB
- 内嵌文档或数组元素会频繁修改
- 内嵌数组元素会持续增长并且没有封顶
-
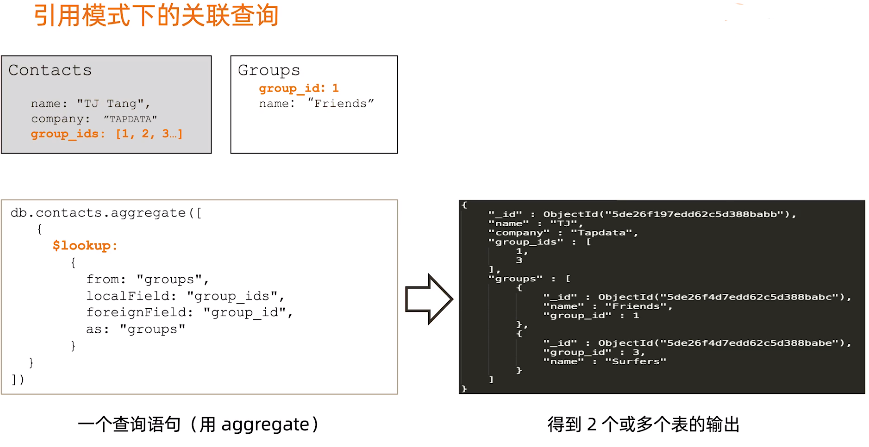
MongoDB引用设计的限制
- MongoDB对使用引用的集合无主外键检查(需要程序自行判断)
- MongoDB使用聚合框架的 $lookup 来模仿关联查询
- $lookup 只支持 left outer join
- $lookup 的关联目标(from)不能是分片表
db.contacts.aggregate([
{
$lookup:{
from:"groups", #外联表
localField:"group_ids", #外键字段
foreignField:"group_id", #外联表主键
as:"groups" #查询结果
}
}
])
3.3 套用设计模型
- 物联网场景下的海量数据处理 - 飞机监控数据
-- 要求记录飞机的实时位置,假设有10万架飞机、1年的数据、每分钟一条
-- 如果每架飞机每分钟都往数据库写入一条数据,那么数据量将非常庞大,如何解决呢?可以使用分桶设计解决:一个文档保存一架飞机一小时的数据
| 每分钟1个文档 | 每小时1个文档 | |
|---|---|---|
| 文档条数 | 52.6B | 876M |
| 索引大小(_id index \ {ts:1,deviceId:1}) | 6364GB(1468GB \ 4895GB) | 106GB(24.5GB \ 81.6GB) |
| 文档平均大小 | 92 Bytes | 758 Bytes |
| 数据大小 | 4503GB | 618GB |
-
大文档,很多字段,很多索引
-- 比如一个表中存在各种各样的名字(chineseName,englishName,franchName...),而且每个名字会频繁的查询。可以使用列转行,将多个相同的列转化为一个数组(names:{ chinese:'',english:'',franch:'' }) -
模型灵活了,如何管理文档的不同版本?
-- 增加一个版本字段 -
统计网页流量点击
-- 如果每次点击页面都产生一个计数更新操作,那么数据库将大量由此操作占据了
-- 这种统计数字准确性并不十分重要,可以使用近似计算优化:每10次操作计数一次写入库数值10
if random(0,9) == 0
increment by 10
- 业绩排名、游戏排名、商品销售统计等精确统计
-- 如某个商品今天卖了多少、本周卖了多少、本月卖了多少
-- 传统解决方案是通过聚合计算,但是消耗资源多,聚合计算时间长;使用聚合字段
{
product:"洗衣服",
sku:"10000",
price:23.99,
stock:9999,
daily_sales:10,
weekly_sales:100,
monthly_sales:700
}
db.products.update({_id:123,{
$inc:{
stock:-1,
daily_sales:1,
weekly_sales:1,
monthly_sales:1
}
}})
- 模式小结
| 模式 | 场景 | 痛点 | 设计模式的方案及优点 |
|---|---|---|---|
| 分桶 | 时序数据(物联网、智慧城市、智慧交通) | 数据点采集频繁,数据量太多 | 利用文档内嵌数组,将一个时间段的数据聚合到一个文档里 大量减少文档数量 大量减少索引占用空间 |
| 列转行 | 产品属性(color、size...) 多语言(多国家)属性 |
文档中有很多类似的字段 会用于组合查询搜索,需要建立很多索引 |
转化为数组,一个索引解决所有查询问题 |
| 版本字段 | 任何有版本衍变的数据库 | 文档模型格式多,无法知道其合理性 升级时需要更新太多文档 |
增加一个版本号字段 快速过滤掉不需要升级的文档 升级时对不同版本的文档做不同的处理 |
| 近似计算 | 网页计数,各种结果不需要准确的排名 | 写入太频繁,消耗系统资源 | 间隔写入,每隔10次或100次写入 大量减少写入操作 |
| 预聚合 | 准确排名、排行榜 | 统计计算耗时,计算时间长 | 模型中直接增加统计字段 每次更新数据的同时更新统计值 |
