个人项目
| 软件工程班级 | 19级网工34班 |
|---|---|
| 作业要求 | 作业2-个人项目-论文查重 |
| 作业目标 | 熟悉个人项目开发流程 学会使用PSP表格 初步掌握Git 论文查重算法的实现 学会使用单元测试 |
| github链接 |
一.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 35 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 35 | 30 |
| Development | 开发 | 450 | 600 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 70 |
| · Design Spec | · 生成设计文档 | 60 | 50 |
| · Design Review | · 设计复审 | 40 | 50 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 40 | 50 |
| · Design | · 具体设计 | 40 | 60 |
| · Coding | · 具体编码 | 120 | 150 |
| · Code Review | · 代码复审 | 60 | 70 |
| Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 100 | 100 |
| · Test Repor | · 测试报告 | 80 | 70 |
| · Size Measurement | · 计算工作量 | 20 | 30 |
| · Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 615 | 760 | |
| 项目大致结构: | |||
 |
|||
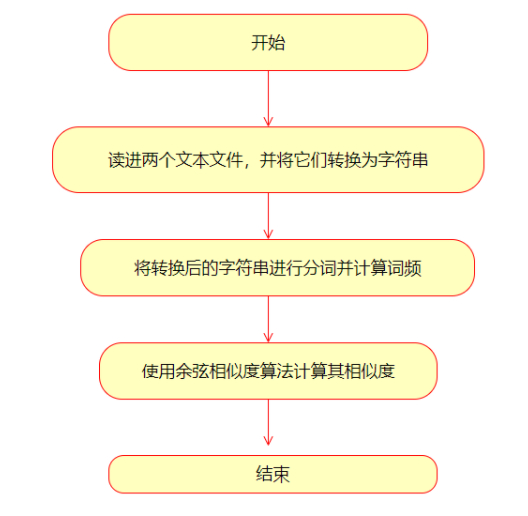
| 算法流程: | |||
 |
二.接口设计与实现
文件读取接口实现
·从命令行中接受原文,查重论文以及答案文件存储路径.
·对原文及查重论文进行分句处理.
·将处理后的文件传递给计算模组.
核心算法:
private static String[] TxtToArray(String paperPath) {
String[] sentenceArray = new String[2000];
try {
Reader reader = null;
reader = new InputStreamReader(new FileInputStream(new File(paperPath)));
int tempchar;
int n = 0;
String sentence = "";
while ((tempchar = reader.read()) != -1) {
switch (JudgeType(tempchar)) {
case 1:
if (sentence.equals("")) break;
if (sentence.length() > 5) sentenceArray[n++] = sentence;
sentence = "";
break;
case 2:
sentence = sentence + (char) (tempchar);
default:
break;
}
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
return sentenceArray;
}
原理:利用逐字读取字符并判定字符类型的方法划分句子;
计算模组接口实现
·从读取接口中获取两组处理好的字符数组
·利用原文中的每一句对查重论文的所有句子进行比对并取最高值
核心算法:
for (String doc1 : originalArray
) {
sentencePercentage = 0;
if (doc1 == null) break;
wordNum += doc1.length();
for (String doc2 : addArray
) {
if (doc2 == null) break;
Map<Character, int[]> algMap = new HashMap<Character, int[]>();
for (int i = 0; i < doc1.length(); i++) {
char d1 = doc1.charAt(i);
int[] fq = algMap.get(d1);
if (fq != null && fq.length == 2) {
fq[0]++;
} else {
fq = new int[2];
fq[0] = 1;
fq[1] = 0;
algMap.put(d1, fq);
}
}
for (int i = 0; i < doc2.length(); i++) {
char d2 = doc2.charAt(i);
int[] fq = algMap.get(d2);
if (fq != null && fq.length == 2) {
fq[1]++;
} else {
fq = new int[2];
fq[0] = 0;
fq[1] = 1;
algMap.put(d2, fq);
}
}
double sqdoc1 = 0;
double sqdoc2 = 0;
double denuminator = 0;
for (Map.Entry entry : algMap.entrySet()) {
int[] c = (int[]) entry.getValue();
denuminator += c[0] * c[1];
sqdoc1 += c[0] * c[0];
sqdoc2 += c[1] * c[1];
}
double similarPercentage = denuminator / Math.sqrt(sqdoc1 * sqdoc2);
if (similarPercentage > sentencePercentage)
sentencePercentage = similarPercentage;
}
similarityPercentage += (sentencePercentage * doc1.length());
}
similarityPercentage = similarityPercentage / wordNum * 100;
原理:利用余弦相似度来判断句子的相似性
运行--根据指示输入原文路径和所需查重论文的路径,并指出答案存储路径获得结果
(同理,其他查重论文的查重方法一致,也可以两篇抄袭论文间的查重测试)
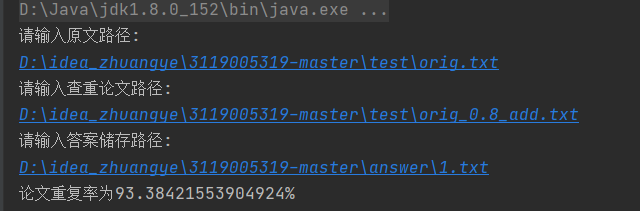
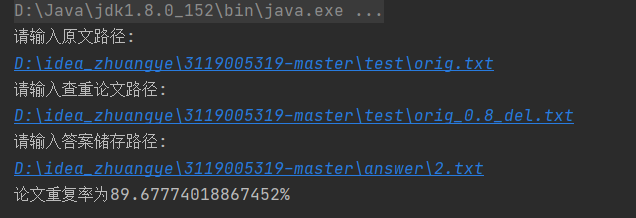
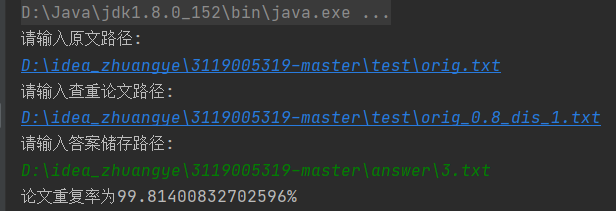
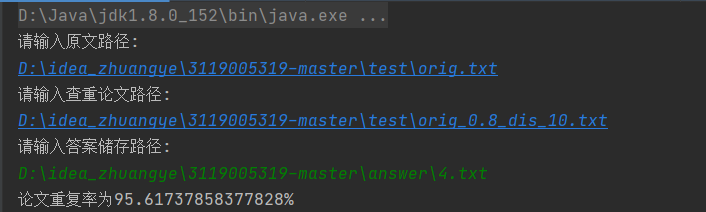
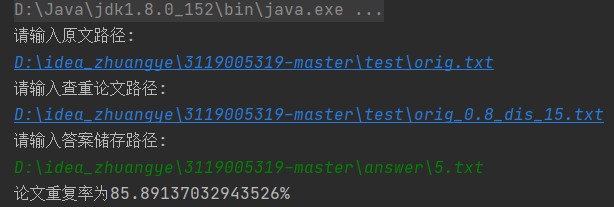
储存的文件情况:


三.算法的改进分析
对分句算法进行优化,减少拼凑字符串的次数.
忽略符号以减少处理次数.

异常处理


四.性能分析
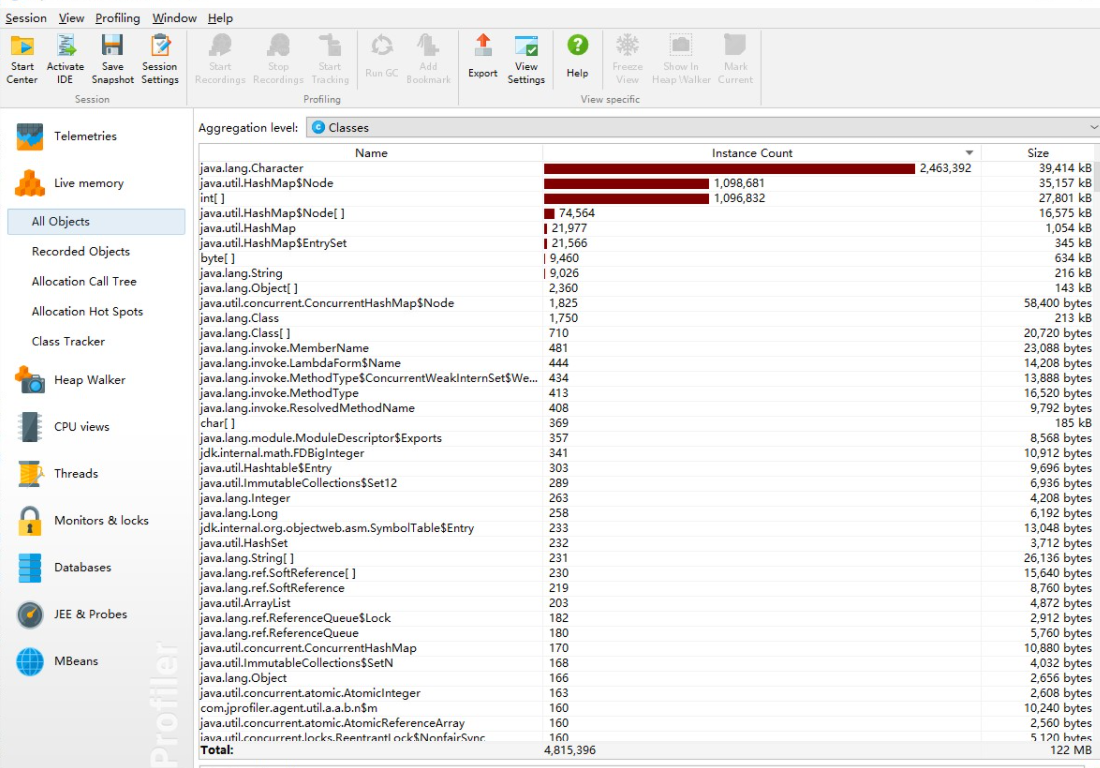
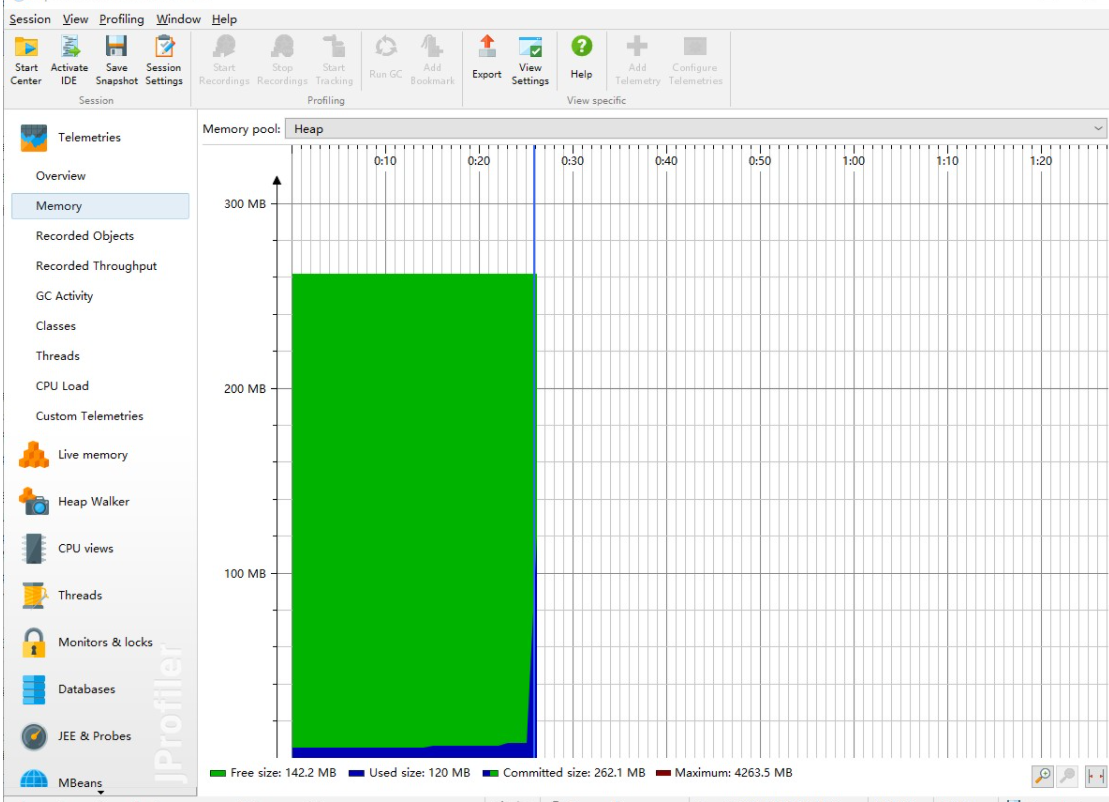
①CPU:
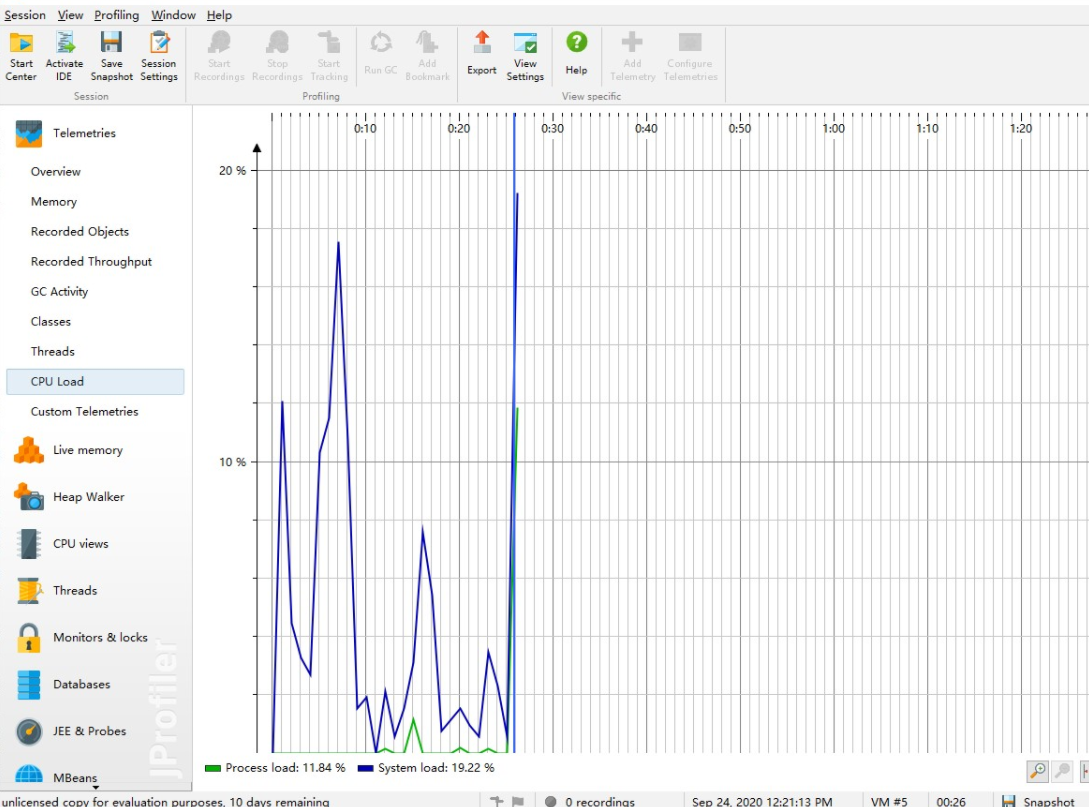
②:使用内存: