

使用panda了解数据集信息
htxx = pd.read_sql()
--------------阅览表格--------------
查看数据前几行(对表有一个大概的认知)默认前5,参数代表前几行
htxx.head()
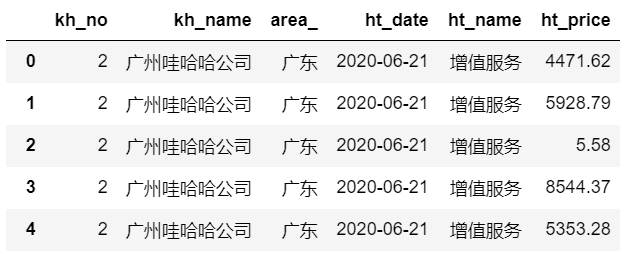
查看数据后几行,默认后5,参数代表后几行
htxx.tail()
查看有几行几列
htxx.shape

--------------查看字段类型--------------
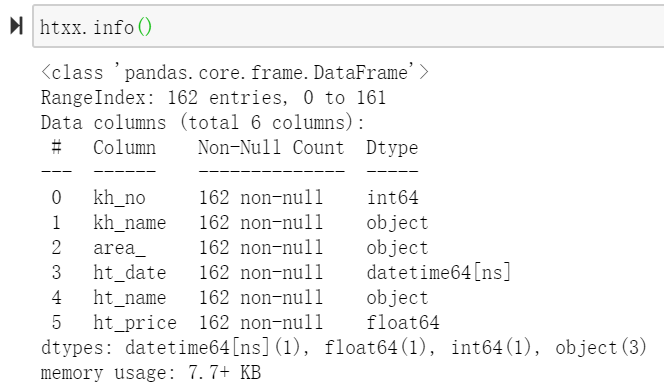
查看数据字段的大概情况,包括类型,列字段格式,名称,占用内存等
htxx.info()
查看某一列的数据类型
htxx.ht_price.dtype

--------------重复值--------------
查看唯一值的长度是否等于数据长度,如果大于说明有重复的数据,可用drop_duplicates()删除
len(htxx.ht_no.unique())
去除重复值,keep=first代表只保留第一个,如果是last则保留最后一个
drop_duplicates = htxx.drop_duplicates(subset='ht_no',keep='first')
--------------描述统计--------------
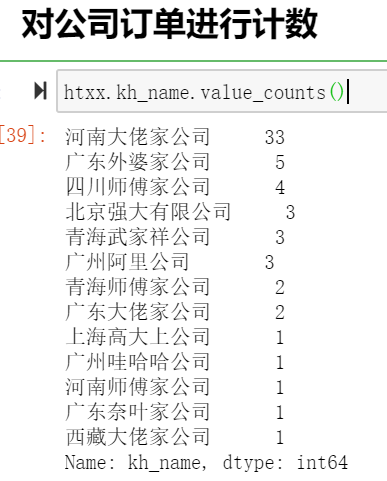
对列中数据进行计数(统计非0元素)
htxx.kh_name.value_counts()
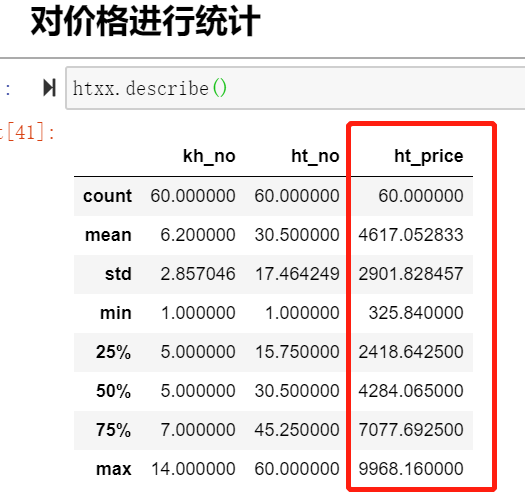
针对表中的数值型数据进行描述统计。一般分类数据用value_counts,数值数据用describe,这是最常用的两个统计函数。
htxx.describe()
--------------排序--------------
对单列数据进行排列,by是排序的列或行,ascending是升序,True则降序,inplace表示排序后是否更新原数据
htxx.sort_values(by = 'ht_price',axis=0,ascending = False,inplace=False,ignore_index=True)
对多列数据进行排列,部分参数使用list
htxx.sort_values(by = ['ht_price','ht_no'],axis=0,ascending = [False,True],inplace=False,ignore_index=True)
--------------数据集切片--------------
取表中的部分列(数据集子集)
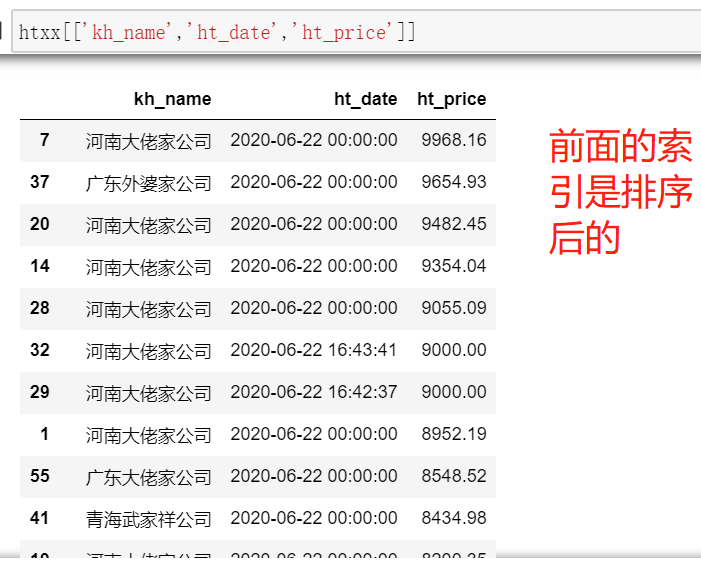
htxx[['kh_name','ht_date','ht_price']]
---iloc[]---
数据集切片(取行,列)iloc[1:3]中的行数表示行,即第1行到第2行,从第0行开始算起
htxx.iloc[1:3]

使用iolc[6,5],使用逗号的表示第6行第5列的数据(从第0行开始的)
htxx.iloc[6,5]
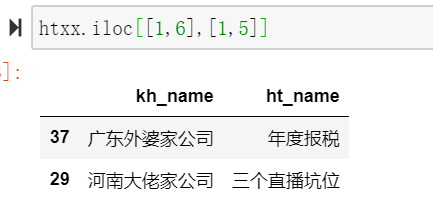
使用iolc[[1,6],[1,5]],表示第1,6行第1,5列的数据(从第0行开始的)
htxx.iloc[[1,6],[1,5]]
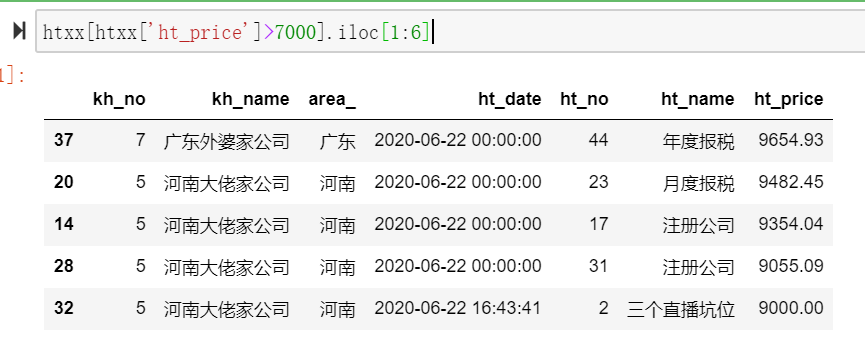
加一个条件判断的切片,在价格大于7000的条件下再进行数据的切片
htxx[htxx['ht_price']>7000].iloc[1:6]
--- loc[]---
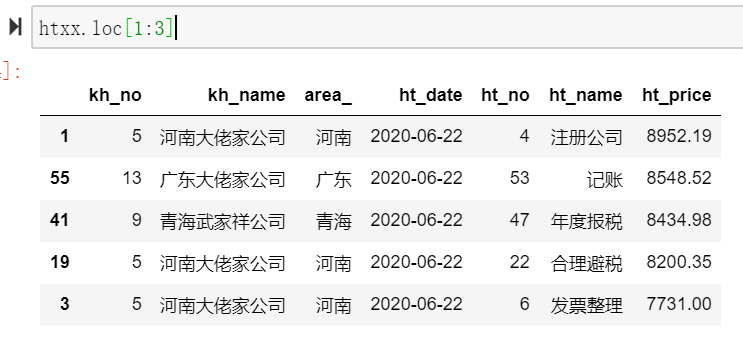
loc[1:3]中的参数表示索引的值,即下图索引1到索引3的所有行数。
htxx.loc[1:3]
持续更新...
