

正向传播、反向传播
一、前言
正向传播(forward propagation/forward pass)指的是:按顺序(从输入层到输出层)计算和存储神经网络中每层的结果。
二、步骤
1、为了简单起见,我们假设输入样本是 𝐱∈ℝ𝑑x∈Rd,并且我们的隐藏层不包括偏置项。这里的中间变量是:
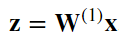
2、其中𝐖(1)∈ℝℎ×𝑑是隐藏层的权重参数。然后将中间变量𝐳∈ℝℎ通过激活函数𝜙后,我们得到长度为h的隐藏激活向量:
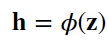
3、隐藏变量h也是一个中间变量。假设输出层的参数只有权重𝐖(2)∈ℝ𝑞×ℎ,我们可以得到输出层变量,它是一个长度为q的向量
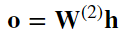
4、 假设损失函数为𝑙l,样本标签为𝑦y,我们可以计算单个数据样本的损失项
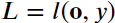
5、 根据𝐿2正则化的定义,给定超参数𝜆,正则化项为:
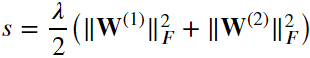
6、最后,模型在给定数据样本上的正则化损失为:
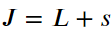
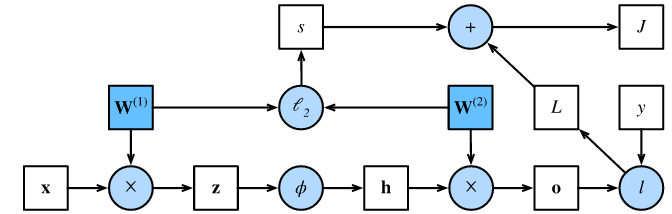
三、正向传播计算图
- 计算图:可视化运算符和变量在计算中的依赖关系
- 左下角是输入,右上角是输出
- 方框代表变量,圆圈代表运算符,箭头代表从输入到输出之间的依赖关系
四、反向传播
1、反向传播指的是计算神经网络参数梯度的方法。
2、反向传播依据微积分中的链式法则,沿着从输出层到输入层的顺序,依次计算并存储目标函数有关神经网络各层的中间变量以及参数的梯度
3、假设我们有函数𝖸=𝑓(𝖷)和𝖹=𝑔(𝖸),其中输入和输出𝖷,𝖸,𝖹是任意形状的张量。利用链式法则,我们可以计算𝖹关于𝖷的导数
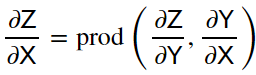
五、训练神经网络
1、在训练神经网络时,正向传播和后向传播相互依赖。对于正向传播,我们沿着依赖的方向遍历计算图并计算其路径上的所有变量。然后将这些用于反向传播,其中计算顺序与计算图的相反。
2、一方面,正向传播的计算可能依赖于模型参数的当前值。而模型参数是在反向传播的梯度计算后通过优化算法迭代的。另一方面,反向传播的梯度计算可能依赖于个变量的当前值,而这些变量的当前值是通过正向传播计算得到的。
3、在模型参数初始化结束后,我们交替的进行正向传播和反向传播,并根据反向传播计算的梯度迭代模型参数。
六、训练比测试占用更多内存原因
1、我们在反向传播中使用了正向传播中计算得到的中间变量来避免重复计算,那么这个复用也导致正向传播结束后不能立即释放中间变量内存。
2、另外,这些中间变量的个体数目大体上与网络层数线性相关,每个变量的大小与批量大小和输入个数也是线性相关的,这是导致较深的神经网络使用较大批量训练时更容易超内存的主要原因
七、小结
1、正向传播沿着输入层到输出层的顺序,依次计算并存储神经网络的中间变量。
2、反向传播沿着输出层到输入层的顺序,依次计算并存储神经网络的中间变量和参数的梯度。
3、在训练深度学习模型时,正向传播和反向传播互相依赖。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)