

模型选择、欠拟合和过拟合
一、前言
将模型在训练数据上拟合得比在潜在分布中更接近的现象称为过拟合(overfitting),用于对抗过拟合的技术称为正则化(regularization)。
二、训练误差与泛化误差
1、训练误差(training error):我们的模型在训练数据集上计算得到的误差。、
2、泛化误差(generalization error):当我们将模型应用在同样从原始样本的分布中抽取的无限多的数据样本时,我们模型误差的期望。
3、我们永远不能准确估算泛化误差。因为无限多的数据样本是一个虚拟的对象。在实际中,我们只能将模型应用在一个独立的数据集中来估计泛化误差,且该数据集需随机选取、未曾在训练集中出现的数据样本构成。
4、独立同分布:我们假设训练数据和测试数据都是从相同的分布中独立提取(也就是说数据之间的没有相关性),每一个样本都是从同一个概率分布中相互独立中生成
5、机器学习模型应关注降低泛化误差
三、模型选择
1、在机器学习中,通常需要评估若干候选模型的表现并从中选择模型
2、验证数据集:在描述模型选择中经常使用验证数据集
- 测试数据集只能在所以超参数和恶模型参数选定后使用一次,不可以使用该测试数据集用于模型选择,
- 由于无法从训练误差中估算泛化误差,因此不能依赖训练数据集来选择模型。所以,我们必须预留一部分在训练数据集和测试数据集以外的数据来进行模型选择,这部分数据集就是验证数据集
3、K折交叉验证:在训练数据集不够用时,预留大量的验证数据显得太奢侈。K折交叉验证就是为了解决训练数据集不够用的情况
- 我们把原始训练数据集分割成K个不重合的子数据集,然后做k次模型训练和验证
- 每一次,使用一个子数据做验证数据集,并使用其他k-1个子数据集来训练模型
- 在k次训练和验证中,每次用来验证模型的子数据集都不同。最后,对这k次训练误差和验证误差取平均值
四、欠拟合和过拟合
1、欠拟合:模型无法得到较低的训练误差(学习能力弱)
2、过拟合:模型的训练误差远小于他在测试数据集上的泛化误差(学习能力太强)
五、模型复杂度
1、模型容量
- 拟合各种函数的能力
- 低容量的模型难以拟合训练数据
- 高容量的模型可以记住所有训练数据
2、模型容量估计
- 参数的个数
- 参数值的选择范围
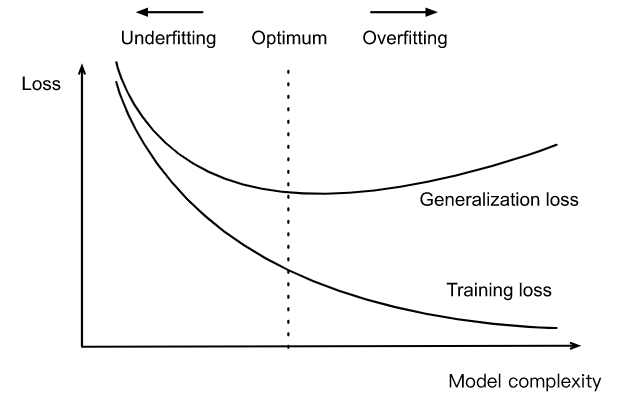
3、给定数据集,模型复杂度与误差之间的关系如下
- 如果模型的复杂度过低,很容易出现欠拟合现象
- 如果模型的复杂度过高(记住了所有训练数据),很容易出现过拟合现象
六、训练数据集大小
1、数据复杂度
- 样本个数
- 每个样本的元素个数
- 时间、空间结构
- 多样性
2、训练数据集中的样本越少,我们就越有可能(且更严重地)遇到过拟合
3、泛化误差不会随训练数据集中样本数量增加而增加


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)