

字典
一、什么是字典
1、python内置的数据结构之一,与列表一样是一个可变序列
2、以键值对的方式存储数据,字典是一个无序的序列
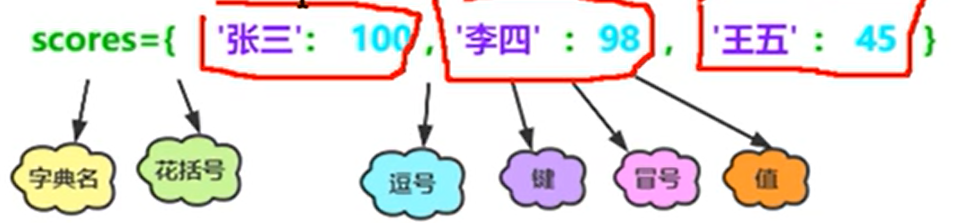
3、字典示意图
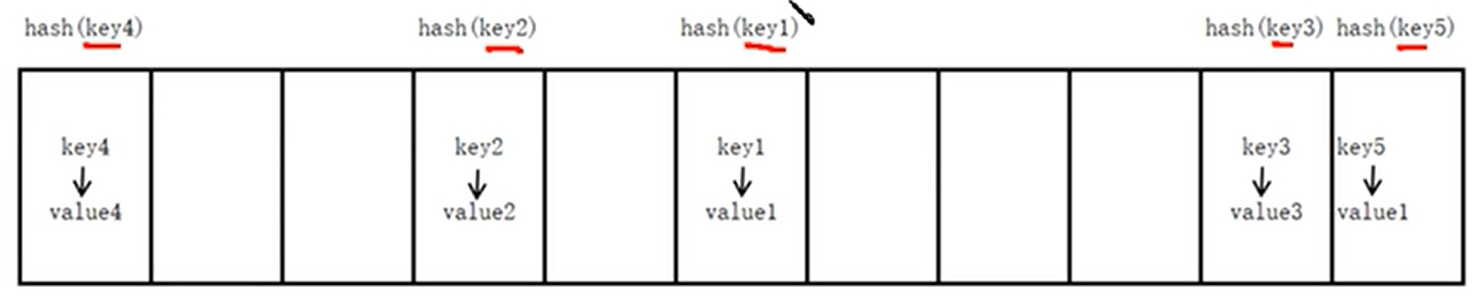
4、字典的实现原理
- 字典的实现原理与查字典类似,查字典是先根据部首或拼音查找对应的页码,python中的字典是根据key值查找value所在的位置
二、字典的创建
1、最常用的方式:使用花括号
2、使用内置函数dict()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | #第一种字典的创建方法scores={'小秦同学在上学':90,'梅达':97,'柳阳':98}print(scores)print(type(scores))#第二种字典的创建方法student=dict(name='Jack',age=20)print(student)print(type(student))#空字典的创建d={}print(d)print(type(d))运算结果:{'小秦同学在上学': 90, '梅达': 97, '柳阳': 98}<class 'dict'>{'name': 'Jack', 'age': 20}<class 'dict'>{}<class 'dict'> |
三、字典元素的获取
1、字典中元素的获取——[]和get()方法
2、[]取值和get()方法的区别
- 在[]中,如果key不存在,则会报错,抛出keyError异常
- get()方法取值,如果字典中不存在指定的key值,不会报错而是返回None,可以通过设置默认的value,以便指定的key不存在时返回
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | score={'秦健峰':100,'梅达':50,'刘阳':80}print(score)print(score['刘阳'])#print(score['meida']) #没有该key值,报错KeyError: 'meida'print(score.get('秦健峰'))print(score.get('全家福'))#返回Noneprint(score.get('全家福',99)) #如果’全家福‘不存在,则返回设置的默认值运算结果:{'秦健峰': 100, '梅达': 50, '刘阳': 80}80100None99 |
四、字典常用操作
- key的判断-看其是否存在
- 删除key-value对
- 新增元素
- 修改元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | score={'秦健峰':100,'梅达':50,'刘阳':80}print(score)#判断key是否存在print('qjf' in score)print('qjf' not in score)print('梅达' in score)print(score['梅达'])#删除指定的key-value对#del score['qjf'] #没有该key,则会报错del score['梅达']print(score)#清空key-value对#score.clear()#print(score)#增加新的元素score['qjf']=99print(score)#修改元素score['qjf']=100print(score)运算结果:{'秦健峰': 100, '梅达': 50, '刘阳': 80}FalseTrueTrue50{'秦健峰': 100, '刘阳': 80}{'秦健峰': 100, '刘阳': 80, 'qjf': 99}{'秦健峰': 100, '刘阳': 80, 'qjf': 100}Process finished with exit code 0 |
五、获取字典视图
- 获取字典中所有key——key()
- 获取字典中所有value——values()
- 获取字典中所有key-value对——items()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | #获取所有的keyscore={'秦健峰':100,'梅达':50,'刘阳':80}keys=score.keys()print(keys)print(type(keys))#将dict_keys转变为列表keys=list(keys)print(keys) #['秦健峰', '梅达', '刘阳']#获取所有的value值values=score.values()print(values)print(type(values))#将dict_values转变为列表values=list(values)print(values,type(values)) #[100, 50, 80]#获取key-value对的值items=score.items()print(items)print(type(items))#将dict_items转变为列表items=list(items)print(items) #[('秦健峰', 100), ('梅达', 50), ('刘阳', 80)] 引入元组概念运行结果:dict_keys(['秦健峰', '梅达', '刘阳'])<class 'dict_keys'>['秦健峰', '梅达', '刘阳']dict_values([100, 50, 80])<class 'dict_values'>[100, 50, 80] <class 'list'>dict_items([('秦健峰', 100), ('梅达', 50), ('刘阳', 80)])<class 'dict_items'>[('秦健峰', 100), ('梅达', 50), ('刘阳', 80)]Process finished with exit code 0 |
六、字典元素的遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | score={'秦健峰':100,'梅达':50,'刘阳':80}#字典元素的遍历#for循环遍历取得到的是keyfor i in score: print(i)<br>#查看key对应的valuefor i in score: print(i,score[i],score.get(i))运算结果:秦健峰梅达刘阳秦健峰 100 100梅达 50 50刘阳 80 80 |
七、字典的特点
- 字典中所有元素都是一个key-value对,key不允许重复,value可以重复
- 字典中的元素是无序的
- 字典中的key必须是不可变对象
- 字典也可以根据需要动态伸缩
- 字典会浪费较大的内存,是一种使用空间换时间的数据结构
八、字典生成式——也就是生成字典
使用内置函数zip():用于将可迭代的对象作为参数,将对象中对应的元素打包成一个元组,然后返回由这些元组组成的列表
1 2 3 4 5 6 7 8 9 | items=['Fruits','Books','Others']prices=[96,78,85]d={item:price for item,price in zip(items,prices)}#{'Fruits': 96, 'Books': 78, 'Others': 85}print(d)#使用upper()可以将字符全部变为大写d={item.upper():price for item,price in zip(items,prices)}#{'FRUITS': 96, 'BOOKS': 78, 'OTHERS': 85}print(d) |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)