[Python]Windows 配置双击可执行bat脚本以及xlsx中文处理方法
windows好陌生,一直没怎么接触过windows,也没有拿它来进行过脚本和程序编写。
之前写的一个小工具是在mac上实现的,同事他们需要在windows上使用,于是研究了一下相关配置,不得不说,懂了之后是还挺简单的,但是不熟悉的话,配置跟实现这些小需求真的麻烦,这里记录一下相关需求实现,当自己的笔记,如果你需要又刚好看到,也希望能帮助到你。
先说第一个配置实现。
实现双击执行脚本编写
预期的是有一个傻瓜式点击操作,双击就可以执行不用管其他的东西,这个在mac很好做,通过shell command或者编写一个命令行程序都可以。
但是windows 怎么做呢?
shell 配置?其他的方式?
这里我选择使用编写bat格式的脚本实现双击需求(cmd也可以,不过我只研究了bat编写)。
bat和cmd常用命令参考这个:Windows批处理(cmd/bat)常用命令小结
首先,桌面新建一个txt文件,内容编辑如下。
@echo off
start cmd /c "cd /d %~dp0"
start cmd /k "python exportData.py"
内容解释:
-
@echo off执行以后,后面所有的命令均不显示,包括本条命令(也就是只显示你打印的输出)。
echo off执行以后,后面所有的命令均不显示,但本条命令是显示的。 -
cd /d %~dp0
cd到当前所在目录,我的目的就是cd目录然后执行python文件。
- start cmd /c / start cmd /k
start cmd /c 是执行完命令后关闭该命令窗口;
start cmd /k 是执行完命令后不关闭该命令窗口;
我这里只需要打开一个窗口就好,所以第一个关第二个开,最后把txt合适后缀改成bat后缀即可双击执行。
配置安装python 以及pip环境
1.安装配置python
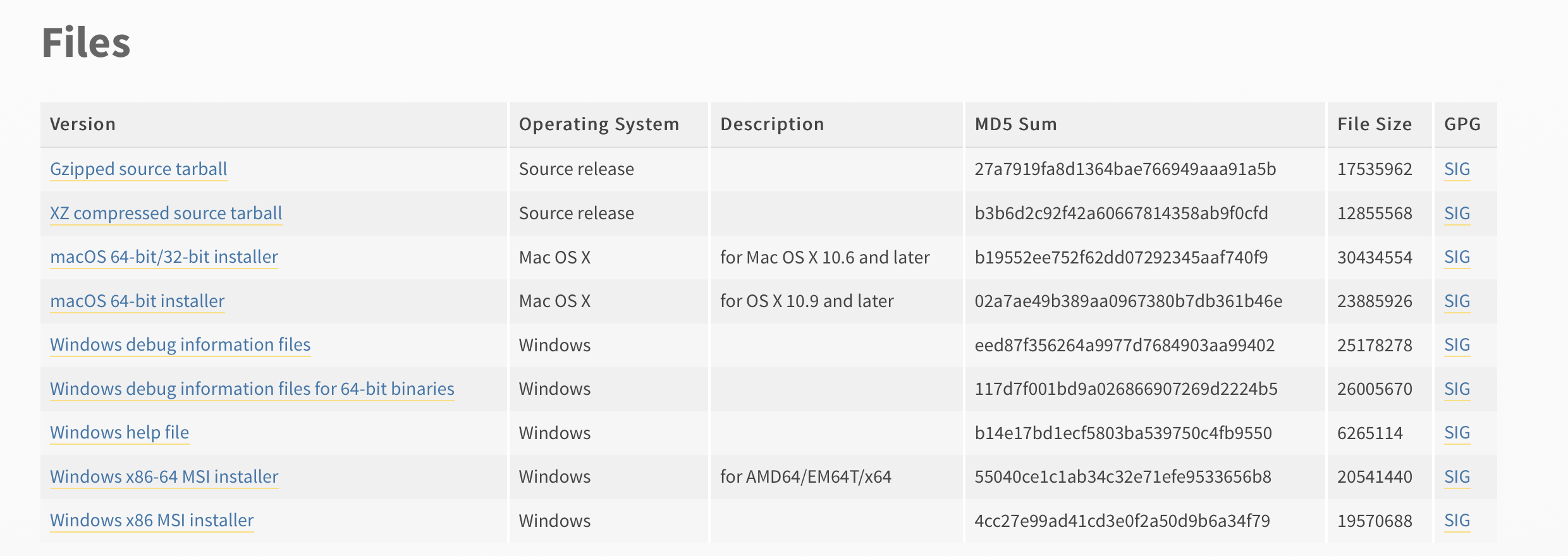
首先:去官网https://www.python.org/
选择download —>windows ,python版本我选择2.7.17--Windows x86-64 MSI installer 如果你的电脑下载好,安装失败可以选下面一个Windows x86 MSI installer重新下载安装。
python安装好之后一般默认路径是在c盘,这时候,我们需要配置一下系统环境path,因为当前的cmd+r进dos执行python还认不到。
搜索环境,打开系统配置面板。


上面填的2个路径,其中script是用来配置python安装的库的路径环境,因为接下来还需要安装pip.
2.安装pip
进入官网,https://pypi.org/project/pip/#downloads下载选择最新的即可。
如果你没有解压缩的工具,可以使用命令,搜索powershell,进入命令界面:
tar -zxvf pip-20.3.1.tar
如果有的话,直接解压,打开cmd命令(cmd+r输入cmd enter进入):
cd /你的pip文件夹目录第一次层
python setup.py install
好了,安装完毕。
接下来安装所需要的一些库文件,打开cmd命令(cmd+r输入cmd enter进入):
xls和xlsx库的使用参考上篇:[Python]Mac实现处理读写xlsx xls excel文件格式(含中文处理方法)
a. pip install openpyxl
b. pip install xlrd
c. pip install uniout
d. pip install numpy
windows excel中文处理
windows跟mac电脑不一样,首先需要注意下:
LF:"\n",Linux的换行符;CRLF:"\r\n",Windows的换行符。
也就说,如果脚本编写的换行符不一样,你拿mac写好的脚本丢到windows执行可能会有问题。
不过我没遇见,可能我写的还没牵扯到吧,我这边统一是LF。
第二个,windows的编码采用gbk,在mac那边是utf-8显示没问题,但是到了windows 你必须要按照gbk 编码才可以,不然中文显示会乱码。
先写一下windows我的编码声明:
#-*- coding: utf-8
from openpyxl import load_workbook,Workbook
import xlrd
import os
import numpy as np
import uniout
#指定设置utf-8编码
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
workbook = Workbook()
sheet_output.title = "sheet_export"
sheet_output.append(["名称","年龄","输出一","输出二"])
#这里的array是一组包含中文的列表,对于任何跟中文有关的部分我都有按照如下进行解码编码
#encode里面的ignore参数,是因为gbk会有解析不了的字符,例如®,所以我选择忽略它(因为没有找到哪个编码能解析出来 - -)。
a = tempData[("名称").decode("utf-8").encode("gbk","ignore")]
...
#这一步,前面如果你取出的数据需要保存生成文件,则需要先按gbk解码在按utf-8编码
sheet_output.append([a.decode('gbk').encode("utf-8"),b.decode('gbk').encode("utf-8"),c.decode('gbk').encode("utf-8"),d.decode('gbk').encode("utf-8")])
workbook.save('export.xlsx')
这样就搞定了,可能需求不一样,不过差不多就是这个思想,想获取中文格式的数据,就要先解码再按gbk进行编码,得到这个数据后,注意最后数据导出部分,按照gbk编码后的东西要按gbk解码才能拿到,同时要考虑特殊字符,所以编码的时候最好加一个ignore参数。

