DGP
Rethinking Knowledge Graph Propagation for Zero-Shot Learning
Summary
- Dense graph propagation with less layers (2 layers) to avoid knowledge dilution among distant nodes
- Use distance weighting scheme
Intro
Problem 1
GCNs perform a form of Laplacian smoothing, where feature representations will become more similar as depth increases and thus knowledge are washed out due to averaging over the graph.
Solution 1
And GCN with a small number of layers could avoid smoothing, but only immediate neighbors influence a given node
Propose DGP to add connection among distant nodes based on a node’s relationship to its ancestors and descendants
Problem 2
All descendants/ancestors would be included in the one-hop neighborhood and would be weighed equally
Solution 2
Introducing distance-based shared weights to distinguish contribution of different nodes.
Methods
GCN
The zero-shot task can then be expressed as predicting a new set of weights for each of the unseen classes in order to extend the output layer of the CNN.
\(W\) the ground truth weights are obtained by extracting the last layer of a pretrained CNN.
During the inference phase, the features of new images are extracted from the CNN and the classifiers predicted by the GCN are used to classify the features.
Dense Graph Propagation Module
A dense graph connectivity scheme consists of two phases(descendant propagation and ancestor propagation)
- nodes are connected to all their ancestors
- nodes are connected to all descendants
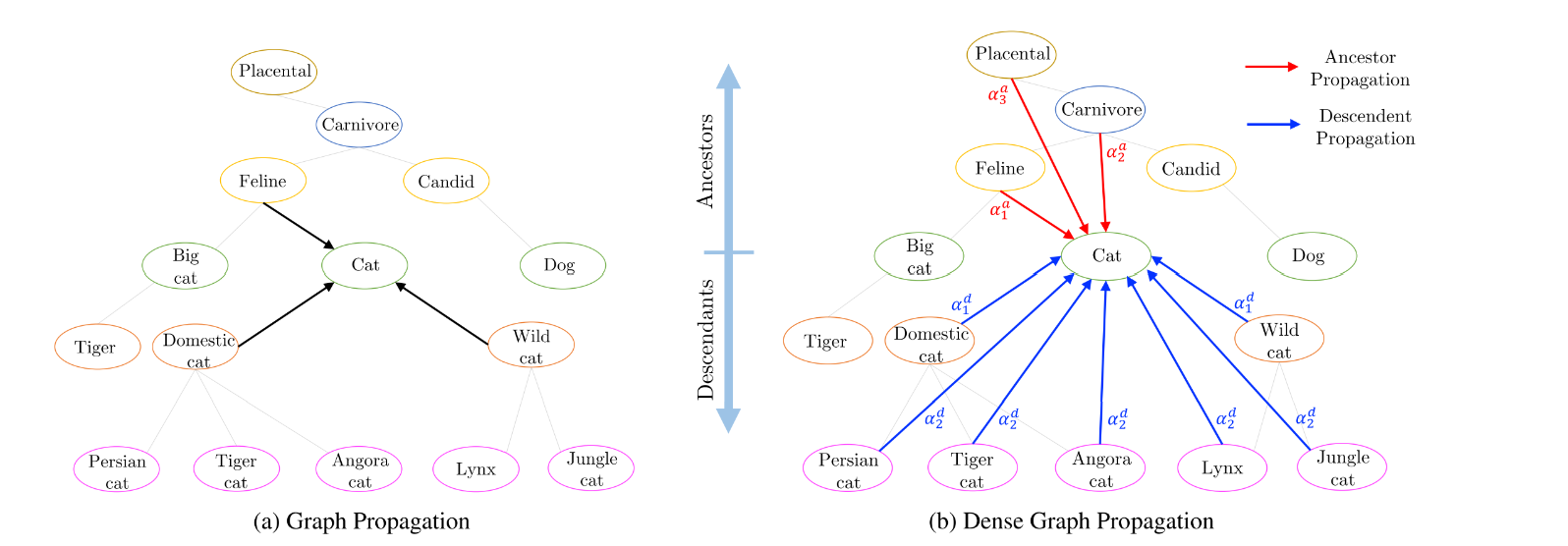
Note, as a given node is the descendant of its ancestors, the difference between the two adjacency matrices is a reversal of their edges \(A_d=A_a^T\)
DGP propagation rule
\(X \in \R^{N\times S}\)(N nodes S features) is the feature matrix
\(A \in \R^{N\times N}\) is a symmetric adjacency matrix (connections between classes)
\(D\) normalizes rows in A to ensure that the scale of the feature representations is not modified by A
Leaky ReLU
Distance weighting scheme
To avoid different nodes contribute the same, introduce distance weighting scheme that compute weight on the knowledge graph not the dense graph.
And use Softmax to normalize the weights.
The author mentions that there is alike attention but not exactly. And if use attention, the performance will drop. Perhaps model is overfitting with sparsely labeled graph.

Experiments
-
train the DGP to predict the last layer weights of a pre-trained CNN
DGP takes as input the combined knowledge graph for all seen and unseen classes, where each class is represented by a word embedding vector that encodes the class name.
-
train the CNN by optimizing the cross-entropy classification loss on the seen classes
Freeze the last layer weights and just update the remaining
Thoughts
Why predict the last layer's weights?
Predict new weights to extend the pre-trained CNN, in order to adapt CNN classifier to unseen classes
The result is limited by pre-trained model (gt is pre-trained weights)
Why DGP with more layers don't work?
