Vision Transformer
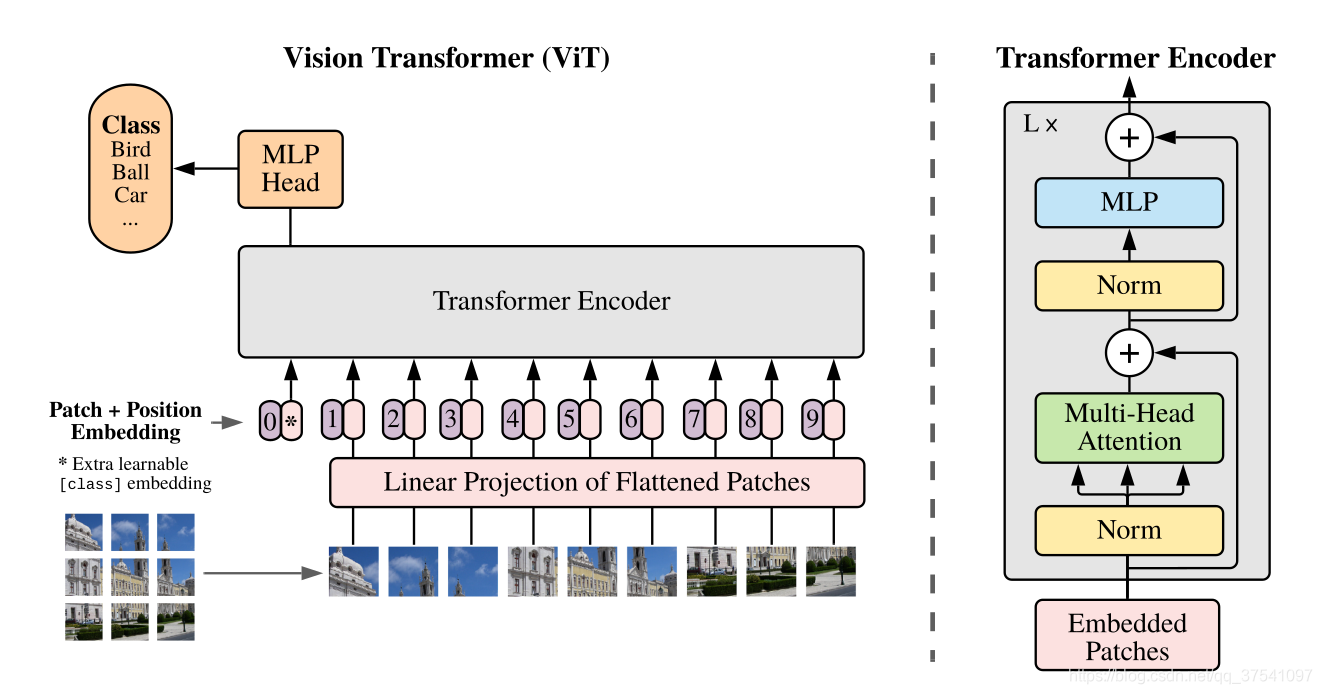
Embedding
对于标准的Transformer模块,要求输入的是token(向量)序列,即二维矩阵[num_token, token_dim]。
但对于图像数据而言,其数据格式为[H, W, C]是三维矩阵明显不是Transformer想要的。
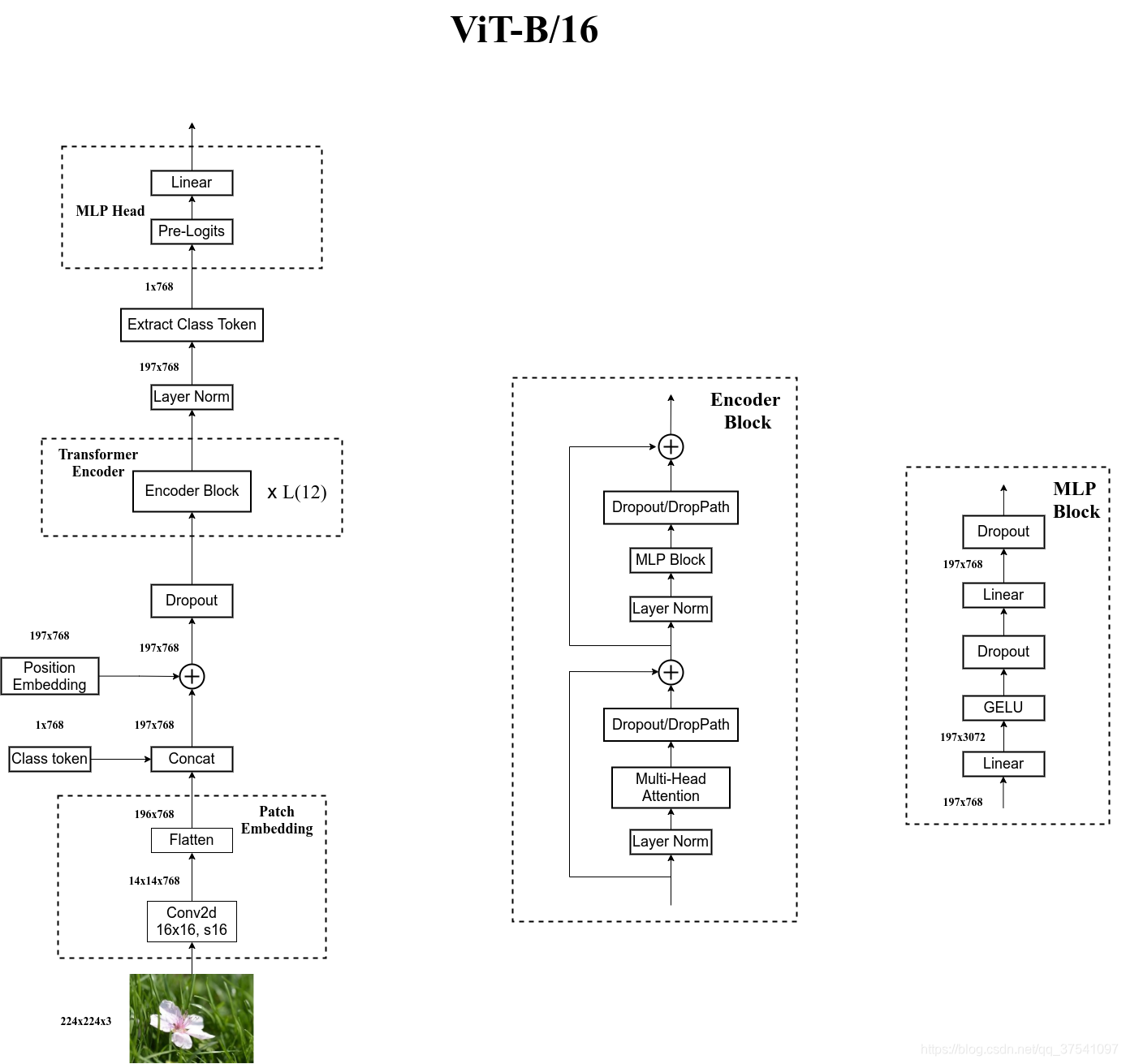
所以需要先通过一个Embedding层来对数据做个变换。首先将一张图片按给定大小分成一堆Patches。以ViT-B/16为例,将输入图片[224x224x3]按照[16x16x3]大小的Patch进行划分,划分后会得到196个Patches。
在代码实现中,直接使用一个卷积核大小为16x16,步距为16,卷积核个数为768的卷积来实现。通过卷积[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768],196个长度为768的向量(token),此时正好变成了一个二维矩阵,正是Transformer想要的。
接着再加上一个可训练的class token变为[197, 768],然后给每个向量加上Position Embedding
网络总架构
Vision Transformer只用到了transformer的encoder部分