批标准化 Batch Normalization
什么是BN

变换后的各个维度的均值为0,方差为1,通过这样的操作将每一层,每个神经元的输出都变为服从同一分布的变量,但是这样的操作会改变网络的表征能力
所有为了保留网络的原始信息尺度,在对每一维度进行变换后再做一次仿射变换,引入仿射变换的权值和偏置是可以学习的
为什么要BN
解决梯度消失问题
在神经网络中, 数据分布对训练会产生影响
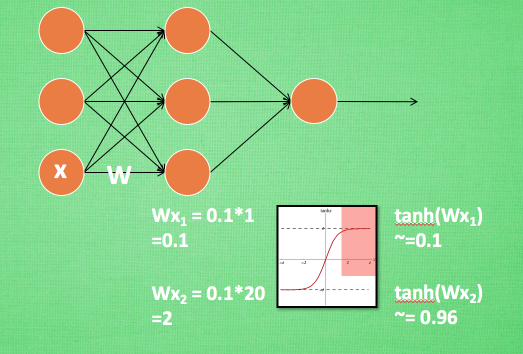
比如某个神经元\(x\)的值为1,某个\(W\)的初始值为 0.1,这样后一层神经元计算结果就是\(Wx = 0.1\),另一个\(x = 20\),这样\(Wx=2\)
现在还不能看出什么问题, 但是当加上一层激活函数激活这个\(Wx\)值的时候, 问题就来了
如果使用tanh激,\(Wx\)的值就变成了0.1和1, 接近于1的部分已经处于激活函数的饱和阶段(梯度消失),也就是如果\(x\)无论再怎么扩大, tanh输出值也还是接近1
换句话说, 神经网络在初始阶段已经不对那些比较大的\(x\)特征范围敏感了
想象一下我轻轻拍自己的感觉和重重打自己的感觉居然没什么差别, 这就证明我的感官系统失效了
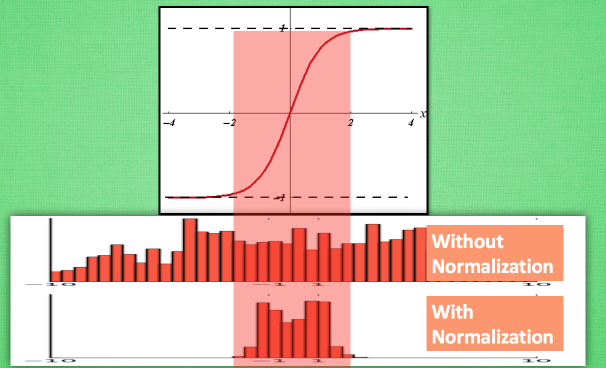
从图中可以看出,数据值越靠近0梯度越大,越远离0梯度越接近0,我们通过BN改变数据分布到0附近,从而解决梯度消失问题
同样也可减轻梯度爆炸问题:详见博客
加速了模型的收敛
和对原始特征做归一化类似,BN使得每一维数据对结果的影响是相同的,由此就能加速模型的收敛速度
正则化
BN层和正规化/归一化不同,BN层是在mini-batch中计算均值方差,因此会带来一些较小的噪声,在神经网络中添加随机噪声可以带来正则化的效果
甚至可以代替dropout,L1 L2正则?
解决了Internal Covariate Shift(ICS)问题?
在训练过程中,浅层因为噪声样本或者激活函数设计不当等原因造成的分布误差会随着前向传播至Loss function, 这一误差随后又在梯度反向传播中被进一步放大
这个貌似被推翻了,容我改天研究一下
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
BN效果
这样经过BN就把数据分布控制在激活函数的敏感区域,防止梯度消失的问题
BN的位置
一般是放在激活函数层之前
常用组合形式如下
CONV/FC -> BN -> ReLu -> Dropout -> CONV/FC

 浙公网安备 33010602011771号
浙公网安备 33010602011771号