MoCo: Momentum Contrast Learning
Introduction
首先横向对比一下
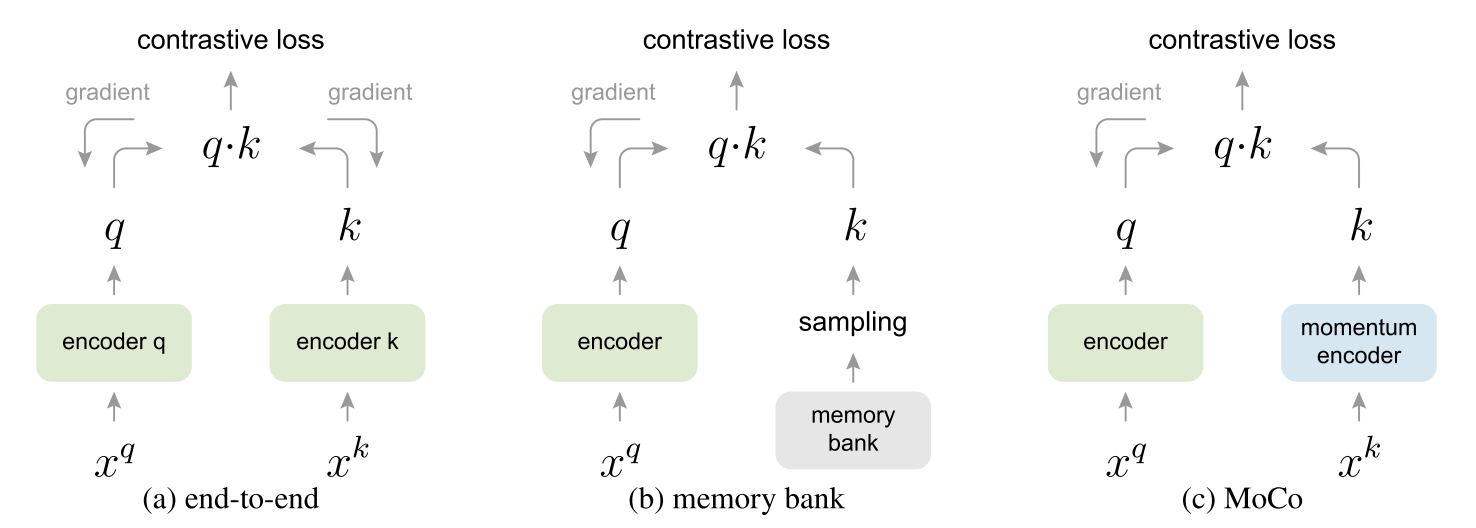
本文提出过去的对比学习
- The dictionary size is coupled with the mini-batch size.
- It's challenged by large mini-batch optimization.
- The sampled keys are essentially about the encoders at multiple different steps all over the past epoch and thus are less consistent.
这篇文章的想法是想要学习到好的特征表示就要有大量的负样本
Our hypothesis is that good features can be learned by a large dictionary that covers a rich set of negative samples.
Method
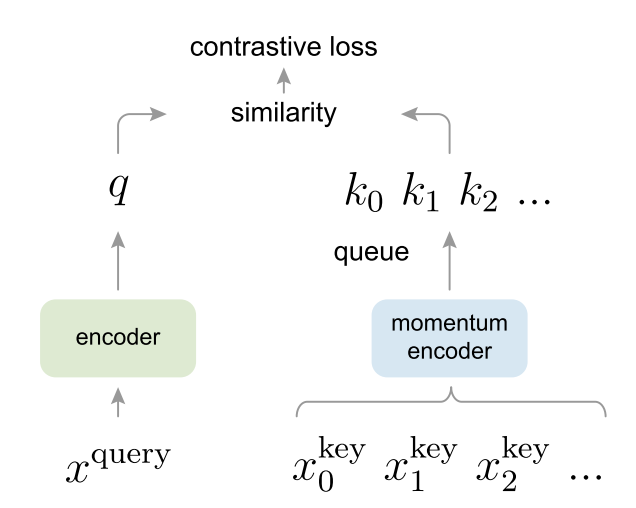
Dictionary
跟SimCLR一样,也是经过不同的augmentation,得到query和key,然后构造正负样本,来自同一图片的不同augmentation构成正样本对
然后计算query和key之间的相似度来计算loss
改进的地方是有一个queue,不仅存放当前的representation,还保存了之前的representation
The dictionary is built as a queue, with the current mini-batch enqueued and the oldest mini-batch dequeued, decoupling it from the mini-batch size.
This method enables a large and consistent dictionary for learning visual representations.
这样就有来自不同batch的更多的negative samples
维护这个先进先出的queue意味着这个dictionary是dynamic的
The current mini-batch is enqueued to the dictionary, and the oldest mini-batch in the queue is removed.
momentum update
因为这个队列特别大,所以使用反向传播去更新key encoder是非常intractable的
更新策略是:在更新了query encoder之后,使用移动平均来更新key的encoder
这里作者提到把momentum coefficient设置大一点效果更好(default m = 0.999),并且称之为"a slowly progressing key encoder"
Contrast Loss
Loss就是InfoNCE
Pseudocode
f_k.params=f_q.params # initialize
for x in loader: # load a minibatch x with N samples
x_q=aug(x) # a randomly augmented version
x_k=aug(x) # another randomly augmented version
q = f_q.forward(x_q) # queries NxC
k = f_k.forward(x_k) # keys NxC
k = k.detach() # no gradient to keys
# positive logits Nx1
l_pos = bmm(q.view(N,1,C), k.view(N,C,1))# bmm batch matrix multiplication
# negative logits: NxK
l_neg = mm(q.view(N,C), queue.view(C,K)) # mm matrix multiplication
# logits: Nx(1+K)
logits = cat([l_pos, l_neg], dim=1)
# contrastive loss
labels = zeros(N) # positives are the 0-th
loss = CrossEntropyLoss(logits/t, labels)
# SGD update: query network
loss.backward()
update(f_q.params)
# momentum update: key network
f_k.params = m*f_k.params+(1-m)*f_q.params
# update dictionary
enqueue(queue, k) # enqueue the current minibatch
dequeue(queue) # dequeue the earliest minibatch
Experiments
论文的ablation study提到了BN会防止模型学习到更好的representation,这是因为在BN中用到了一个batch中所有样本的信息,不同样本的信息就会泄露给对方,使得模型很容易找到low contrast loss,结果容易过拟合
The model appears to “cheat” the pretext task and easily finds a low-loss solution. This is possibly because the intra-batch communication among samples (caused by BN) leaks information.
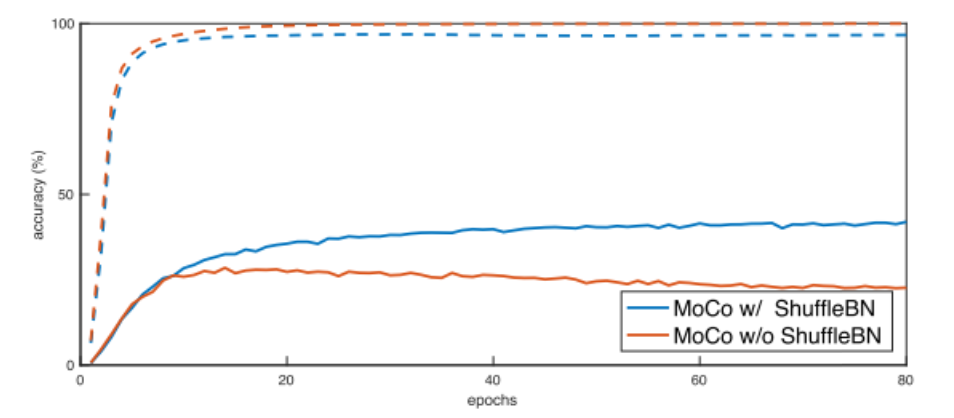
为了避免这种情况,作者通过Shuffling BN来解决该问题
在训练时使用多个GPU,在每个GPU上分别进行BN(常规操作),对于key encoder,在当前mini-batch中打乱样本的顺序,再把它们送到GPU上分别进行BN,然后再恢复样本的顺序;对于query encoder,不改变样本的顺序
这样就够保证用于计算查询和其正键值的批统计值出自两个不同的子集。
These experiments suggest that without shuffling BN, the sub-batch statistics can serve as a “signature” to tell which sub-batch the positive key is in. Shuffling BN can remove this signature and avoid such cheating.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号