梯度下降法优化
梯度下降优化
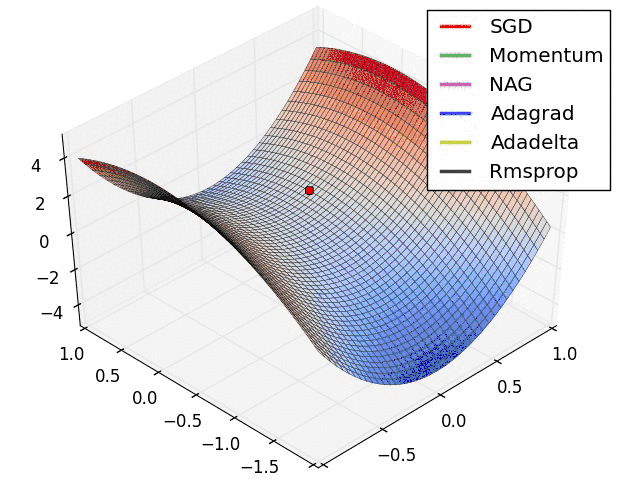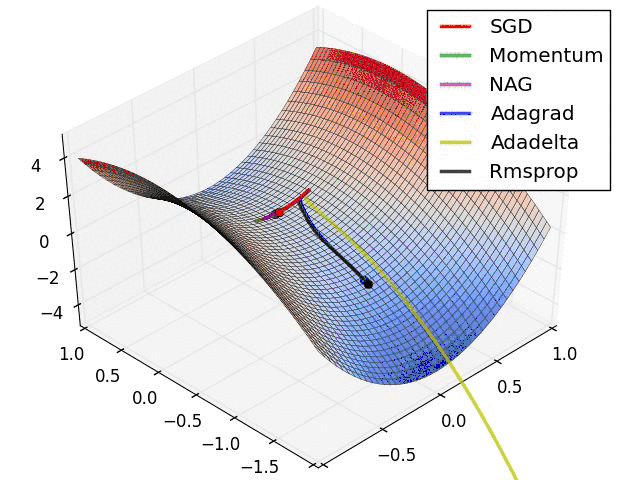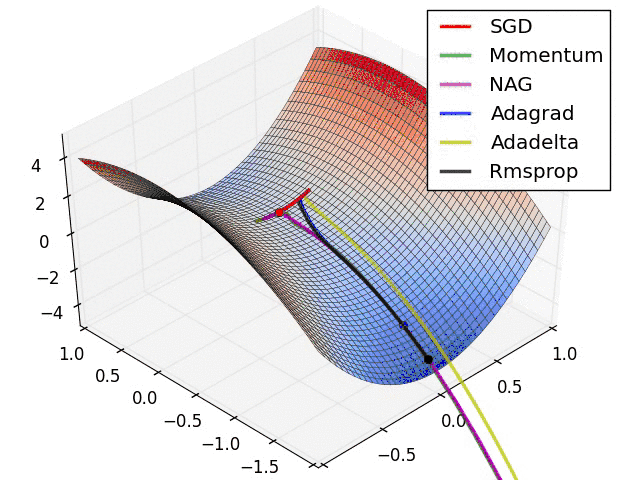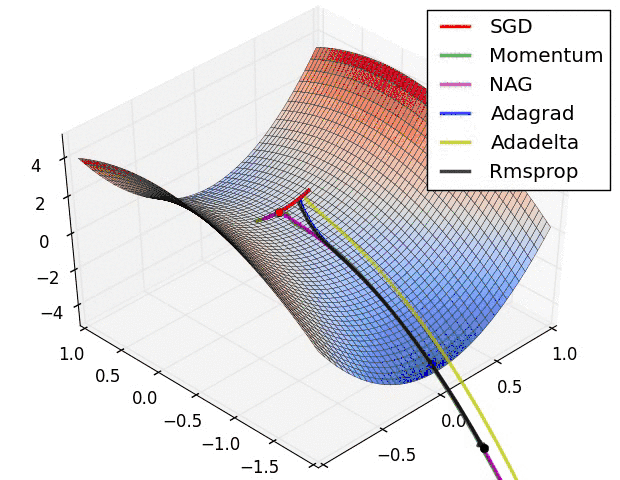
为何要优化
梯度下降是求每个点的梯度,然后从该点减去一个极小量,去进行梯度下降
但计算机是无法计算极小量的,所以必须有一个确定的步长,即学习率
根据一定步长来下山肯定会与最优的梯度下降路径有所偏差,那么如何去减小这个偏差就为梯度下降的优化带来了可能性。
批量梯度下降法(Batch Gradient Descent)
批量梯度下降法,是梯度下降法最常用的形式,具体做法也就是在更新参数时使用所有的样本来进行更新。
这样需要把所有数据都计算一遍才能走一步,而且可能使损失函数陷入局部最小
$\theta_i = \theta_i - \alpha\sum\limits_{j=1}^{m}(h_\theta(x_0^{(j)}, x_1^{(j)}, ...x_n^{(j)}) - y_j)x_i^{(j)}$
随机梯度下降法(Stochastic Gradient Descent)
随机梯度下降法,其实和批量梯度下降法原理类似,区别在与求梯度时没有用所有的m个样本的数据,而是仅仅选取一个样本j来求梯度。
$\theta_i = \theta_i - \alpha (h_\theta(x_0^{(j)}, x_1^{(j)}, ...x_n^{(j)}) - y_j)x_i^{(j)}$
随机梯度下降法由于每次仅仅采用一个样本来迭代,训练速度很快
SGD具有很强的波动性
- 一方面,波动性使得SGD可以跳到新的和潜在更好的局部最优
- 另一方面,这使得最终收敛到特定最小值的过程变得复杂,因为SGD会一直持续波动,难以收敛
小批量梯度下降法(Mini-batch Gradient Descent)
小批量梯度下降法是批量梯度下降法和随机梯度下降法的折衷,也就是对于m个样本,采用x个子样本来迭代
减少参数更新的方差,这样可以得到更加稳定的收敛结果
动量法 Momentum
上述的梯度下降法还是有一定的缺陷,例如在横轴方向上一直向前,但在纵轴方向上上下波动,此时可以依据历史数据去修正纵轴上的分量。
引入变量$v$充当速度的角色,代表参数在参数空间移动的方向和速度(假设参数为单位质量,则其可看作参数的动量),即可解决这一震荡问题,加快收敛
指数加权移动平均法 Exponentially Weighted Moving Average (EWMA)
$V_{(t)}=\beta V_{(t-1)}+(1-\beta) \nabla W_{(t)i}$
这是一个递推关系式,因为$\beta<0$,那么离当前点越远的历史数据权重越小
参数更新$W_{(t)i}=W_{(t-1)i}-\eta\nabla V_{t}$
可以理解为以前的更新有一定的惯性(物理里的动量),本次更新需要将这一部分抵消
Nesterov
Nesterov accelerated gradient(NAG)
不仅增加了动量项,并且在计算梯度时,使用了根据动量项预先估计的参数,在Momentum的基础上进一步加快收敛,提高响应性
AdaGrad
依据历史数据自适应学习率
适合稀疏数据(特征较少,信息不充足)

Adam
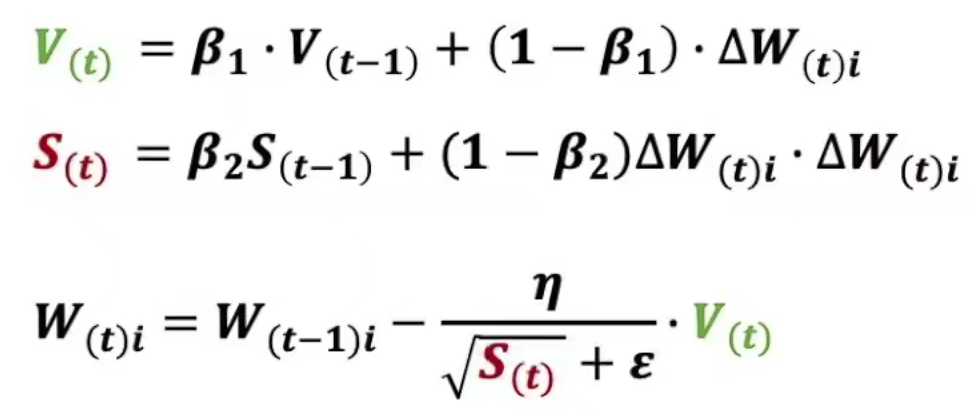
未完待续。。。
