
麦子学院机器学习基础(3)-最邻近规则归类(KNN算法)(python)
一.理论基础知识
1) 基于实例的归类学习 懒惰学习
操作步骤
2) 为了判断未知实例的类别,以所有已知实例作为参照
3)选择参数K
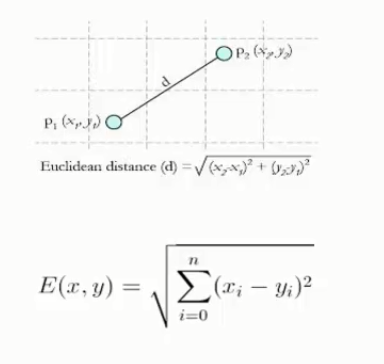
4)计算未知实例和所有已知实例的距离
5)选择最近k个实例
6)根据少数服从多数的投票法则,让未知实例归类为K个最邻近样本中最多数的列别
细节:
关于K
关于距离的衡量方法
常见的衡量方法有解析几何 余弦值 相关度 曼哈顿距离...
曼哈顿距离:水平方向走的距离+竖直方向走的距离
算法的优缺点:
优点:简单 易于理解 容易实现 通过对K的选择可具备丢噪音数据的健壮性
缺点:需要大量存储空间存储所有已知实例 算法复杂度高 当其样本分布不均匀的时候 容易受到实例数量过多的样本主导作用
改进版本;
考虑距离 根据距离增加权重
二 代码实战与应用
1)利用sklearn机器学习库实现
''' 利用Python中的scikit-learn库进行KNN算法调用 ''' from sklearn import neighbors #导入邻近算法模块 from sklearn import datasets #导入一些数据集 knn = neighbors.KNeighborsClassifier() #定义一个KNN算法的分类器 iris = datasets.load_iris() #导入著名的数据集 iris # print(iris) knn.fit(iris.data,iris.target) #建立模型 pred_label = knn.predict([[0.1,0.2,0.3,0.4]]) print(pred_label)
2)自己编写模块实现
''' @file name:KNN_self.py @brief:自己编写函数库实现KNN算法 @author:Mr ywxk @date:2018/1/24 ''' import csv import random import math import operator #加载数据文件 将数据分为训练集和测试集 def load_datasets(filename,split,training_set=[],test_set=[]): with open(filename,'rt') as cvfile: lines = csv.reader(cvfile) dataset = list(lines) for x in range(len(dataset)-1): for y in range(4): dataset[x][y] = float(dataset[x][y]) if random.random() < split: training_set.append(dataset[x]) else: test_set.append(dataset[x]) #计算两个向量之间的距离 def cal_dis(ins1,ins2,length): distance = 0 for x in range(length): distance += pow((ins1[x]-ins2[x]),2) return math.sqrt(distance) #寻找k个近邻之间的距离 def get_neighbors(training_set,test_instance,k): distance = [] length = len(test_instance)-1 for x in range(len(training_set)): dist = cal_dis(test_instance,training_set[x],length) distance.append((training_set[x],dist)) distance.sort(key = operator.itemgetter(1)) neighbors = [] for x in range(k): neighbors.append(distance[x][0]) return neighbors def get_res(neighbors): class_votes = {} for x in range(len(neighbors)): res = neighbors[x][-1] if res in class_votes: class_votes[res] += 1 else: class_votes[res] = 1 sorted_votes = sorted(class_votes.items(),key = operator.itemgetter(1),reverse=True) return sorted_votes[0][0] def get_accuracy(test_set,prediction): correct = 0 for x in range(len(test_set)): if test_set[x][-1] == prediction[x]: correct += 1 return (correct/float(len(test_set))) * 100.0 from KNN_fun_self import * training_set = [] test_set = [] split = 0.67 load_datasets(r'C:\Users\25478\Desktop\Python\KNN\iris.data.txt',split,training_set,test_set) print('train set:\n'+ repr(len(training_set))) print('test set:\n' + repr(len(test_set))) predictions = [] k = 3 for x in range(len(test_set)): neighbors = get_neighbors(training_set,test_set[x],k) res = get_res(neighbors) predictions.append(res) print('perdiction' + repr(res) + 'actual' + repr(test_set[x][-1])) accuracy = get_accuracy(test_set,predictions) print('accuracy:' + repr(accuracy) + '%')
