
麦子学院机器学习基础(2)-决策树算法与应用(python)
督学习算法之一—决策树算法
本节课课件地址:
file:///E:/BaiduNetdiskDownload/[%E8%A7%86%E9%A2%91%E8%AF%BE%E7%A8%8B]%E9%BA%A6%E5%AD%90%E5%AD%A6%E9%99%A2_%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E5%9F%BA%E7%A1%80%E4%BB%8B%E7%BB%8D-%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/%E8%AF%BE%E4%BB%B6/3.1%20%E5%86%B3%E7%AD%96%E6%A0%91(decision%20tree)%E7%AE%97%E6%B3%95.html
算法性能的评估:准确率 速度 强壮性 可规模性 可解释性
1. 什么是决策树/判定树
判定树是一个类似于流程图的树结构,其中,每个内部节点表示在一个属性上的测试,每个分支代表一个属性输出,而每一个树叶结点代表类或类分布,树的最顶层是根结点,下面是模型图和一个实例
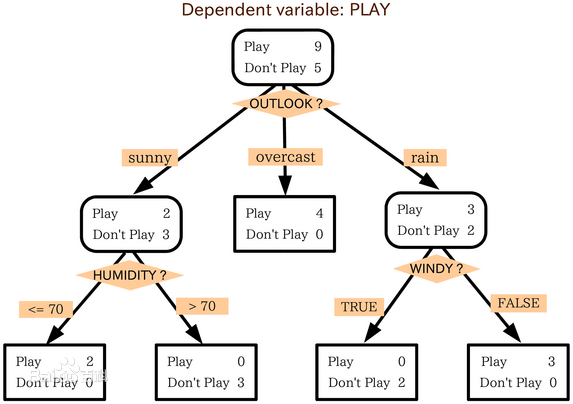
2. 如何让创建决策树
2.1 熵的概念
一条信息的信息量大小和它的不确定性有直接的关系,信息量的度量就等于不确定性的多少。信息量的计算公式如下所示:
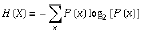
2.2 决策时归纳算法
实例,以下是对是否购买计算机的群体的一项数据调查:
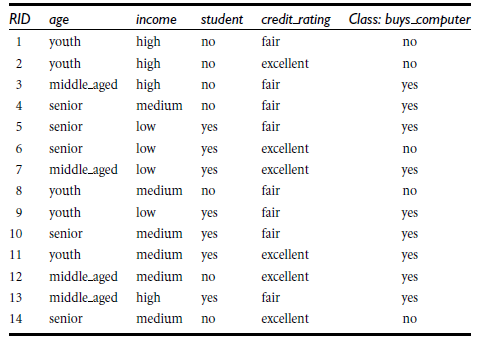
已知从结果上来看的信息量是:

当知道年龄分布后的结果信息量:
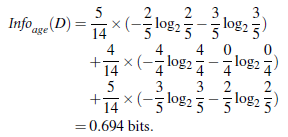
依次类推,分别可以求得在其他条件已知的情况下的信息量

依次类推,当将age作为第一个结点之后,会得到新生成的三个结点,然后再次重复计算,将三个结点按照决策树原理再次进行分类,知道分类结果唯一。
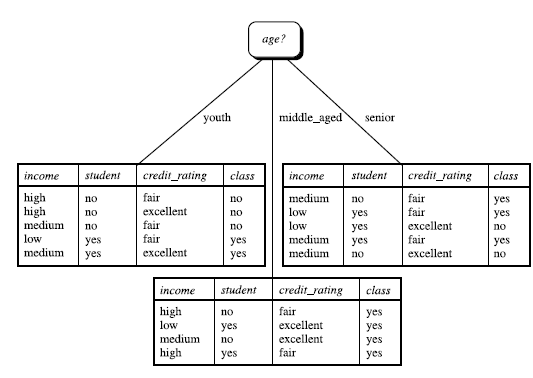
2.2分类停止的条件:
1.给定条件的结点所有样本属于同一样类
2.找不到可以分类该结点的属性
3.决策树的优点与缺点
优点:
直观 便于理解 小规模数据集有效
缺点:处理连续性变量不好 错误增加的比较快 不适用于大规模数据集
4.代码实践-决策树应用
#决策时的应用算法 """ scikit-learn 强大的机器学习库 达到商用级别 对数据输入的要求 对所有的特征值必须是数值型 """ # print("hello world") from sklearn.feature_extraction import DictVectorizer import csv from sklearn import preprocessing #需要使用到预处理 from sklearn import tree #需要使用到树 from sklearn.externals.six import StringIO #读写功能 all_csv_data = open(r'C:\Users\25478\Desktop\Python\DT.csv','rt') #读取表格数据 reader = csv.reader(all_csv_data) #利用模块中的reader函数读取出来 header = next(reader) #取第一行 # print(header) feature_list = [] label_list = [] for row in reader: label_list.append(row[len(row)-1]) #print(row) row_dict = {} for i in range(1,len(row)-1): row_dict[header[i]] = row[i] feature_list.append(row_dict) #print(feature_list) vec = DictVectorizer() dummyX = vec.fit_transform(feature_list).toarray() # print("dummyX:\n" + str (dummyX)) #在特征值上将字符型的转化为数值 # print(vec.get_feature_names()) lb = preprocessing.LabelBinarizer() #在标签上进行二进制化 dummyY = lb.fit_transform(label_list) # print("dummyY:\n" + str(dummyY)) clf = tree.DecisionTreeClassifier(criterion = 'entropy') clf = clf.fit(dummyX,dummyY) # print("clf=:"+str(clf)) with open("dt.dot",'w') as f: f = tree.export_graphviz(clf,feature_names=vec.get_feature_names(),out_file= f) OneRowX = dummyX[0,:] print("OneRowX:\n"+str(OneRowX)) newRowX = OneRowX newRowX[0] = 1 newRowX[1] = 0 print("NewRowX:\n"+str(newRowX)) predY = clf.predict(newRowX) print("predY:"+str(predY))
