智谱开源CogAgent的最新模型CogAgent-9B-20241220,全面领先所有开闭源GUI Agent模型
在现代数字世界中,图形用户界面(GUI)是人机交互的核心。然而,尽管大型语言模型(LLM)如ChatGPT在处理文本任务上表现出色,但在理解和操作GUI方面仍面临挑战,因此最近一年来,在学界和大模型社区中,越来越多的研究者和开发者们开始关注VLM-based GUI Agent。2023年12月,智谱发布了CogAgent,第一个基于视觉语言模型(Visual Language Model, VLM)的开源 GUI agent 模型,而在最近,最新的CogAgent模型 CogAgent-9B-20241220发布,让LLM操作GUI在技术上更进了一步。
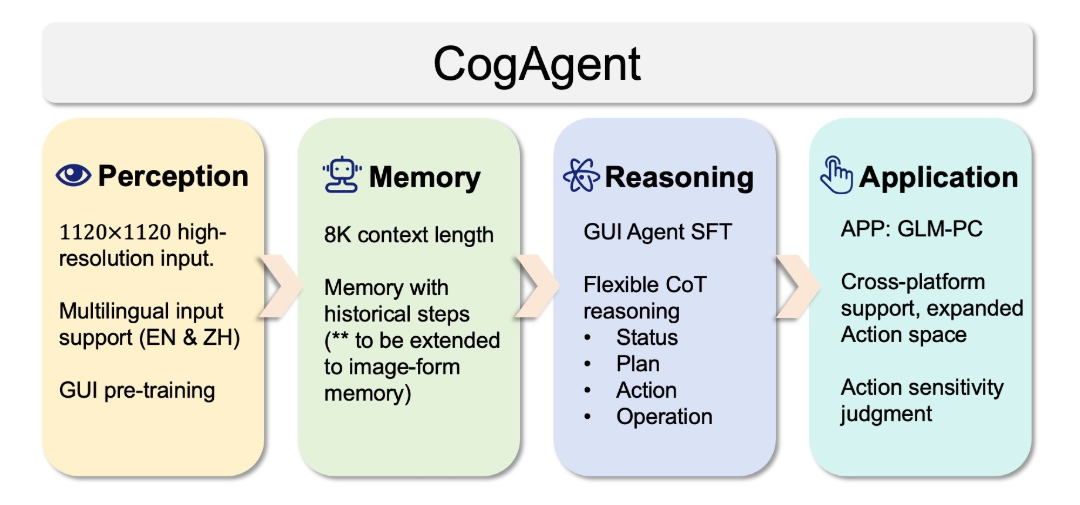
1. CogAgent的诞生与发展#
CogAgent是基于视觉语言模型的开源GUI代理模型。它的独特之处在于仅依赖于屏幕截图作为输入,不需要HTML等文本表征。这使得CogAgent能够在各种基于GUI交互的场景中应用,如个人电脑、手机、车机设备等。随着CogAgent的发布,越来越多的研究者和开发者开始关注VLM-based GUI Agent的研究。
1.1 CogAgent-9B-20241220的发布#
CogAgent-9B-20241220是CogAgent团队经过一年迭代优化后的最新版本。该版本基于GLM-4V-9B双语开源VLM基座模型,通过数据采集与优化、多阶段训练与策略改进等方法,使其在GUI感知、推理预测准确性、动作空间完善性、任务的普适和泛化性上得到了大幅提升。
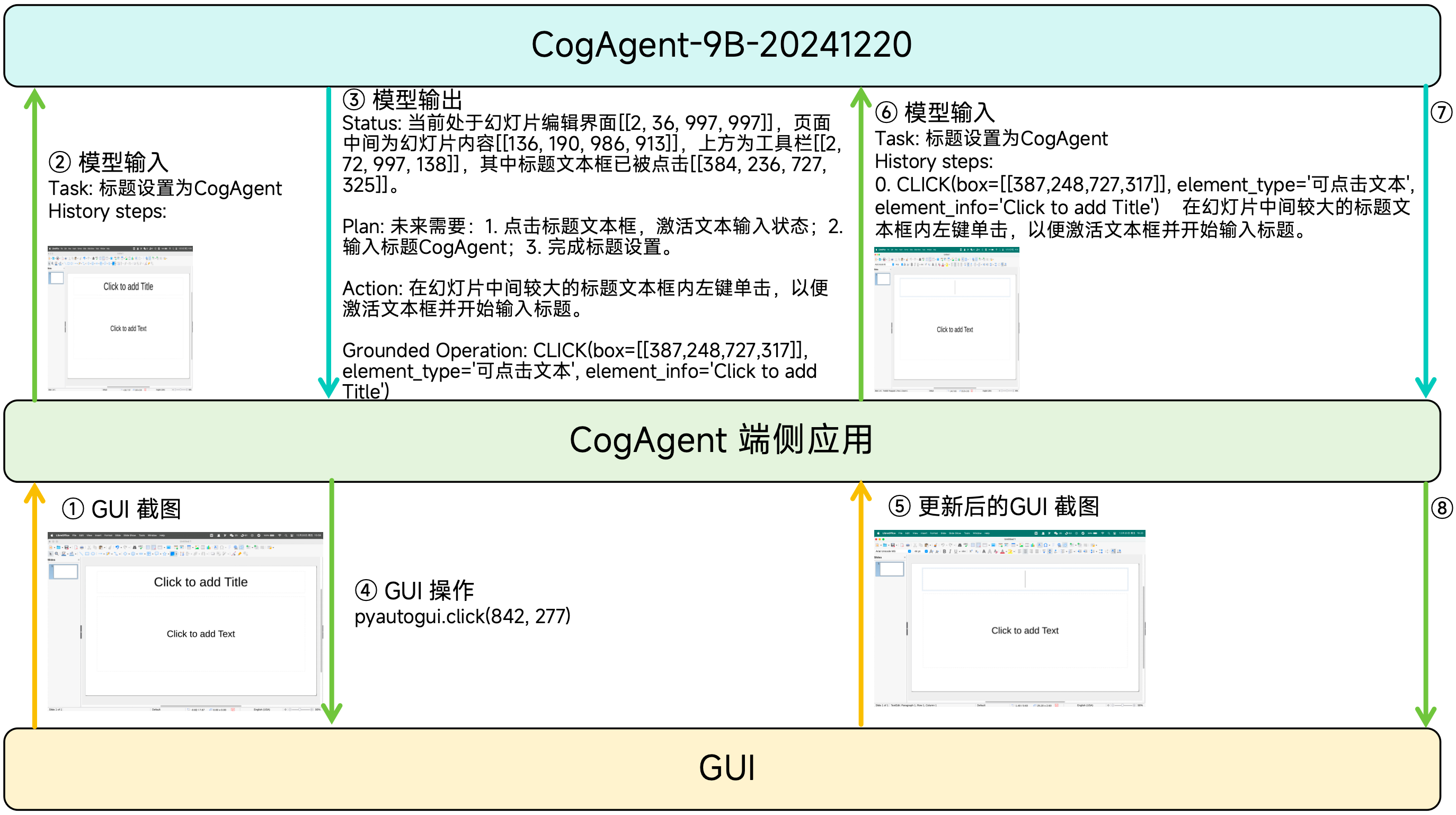
1.2 CogAgent 执行过程#
下图展示了CogAgent-9B-20241220执行用户指令的过程。
- 以 GUI 截图为唯一的环境输入,结合已经完成的动作历史,计算当前 GUI 截图中最合适的动作。
- 根据更新后的历史动作和截图,计算后续的操作
- 重复上述过程,直到CogAgent认为指令执行完毕
2. CogAgent-9B的技术架构与优化#
CogAgent-9B-20241220在模型基座、视觉处理模块、数据集丰富与完善、预训练策略优化、后训练策略改进等方面进行了全面的升级。
2.1 模型基座和结构升级#
CogAgent使用更强大的视觉语言模型GLM-4V-9B作为基座模型,大幅提升了模型的基座图像理解性能。在视觉处理模块上,CogAgent实现了更高效统一的视觉处理模块,支持1120*1120原生高分辨率图像输入。
2.2 数据集丰富与完善#
CogAgent团队广泛收集并整合了多种数据集,包括无监督数据和GUI指令微调数据集。这些数据集的丰富性和多样性为CogAgent提供了更广泛的训练和测试基础,使其能够更好地适应实际应用场景。
2.3 预训练与后训练策略优化#
在预训练阶段,CogAgent引入了GUI Grounding预训练方法,通过屏幕截图和layout对,构造界面子区域和layout表征的对应关系。在后训练阶段,CogAgent采用了更科学的GUI agent后训练策略,使模型具备了更强的分析、推理、预测能力。
3. CogAgent-9B的应用与性能评估#
CogAgent-9B-20241220在多个数据集上的测试结果显示了其卓越的性能。尤其是在Screenspot、OmniAct、CogAgentBench-basic-cn、OSworld等数据集上,CogAgent均取得了领先的成绩。
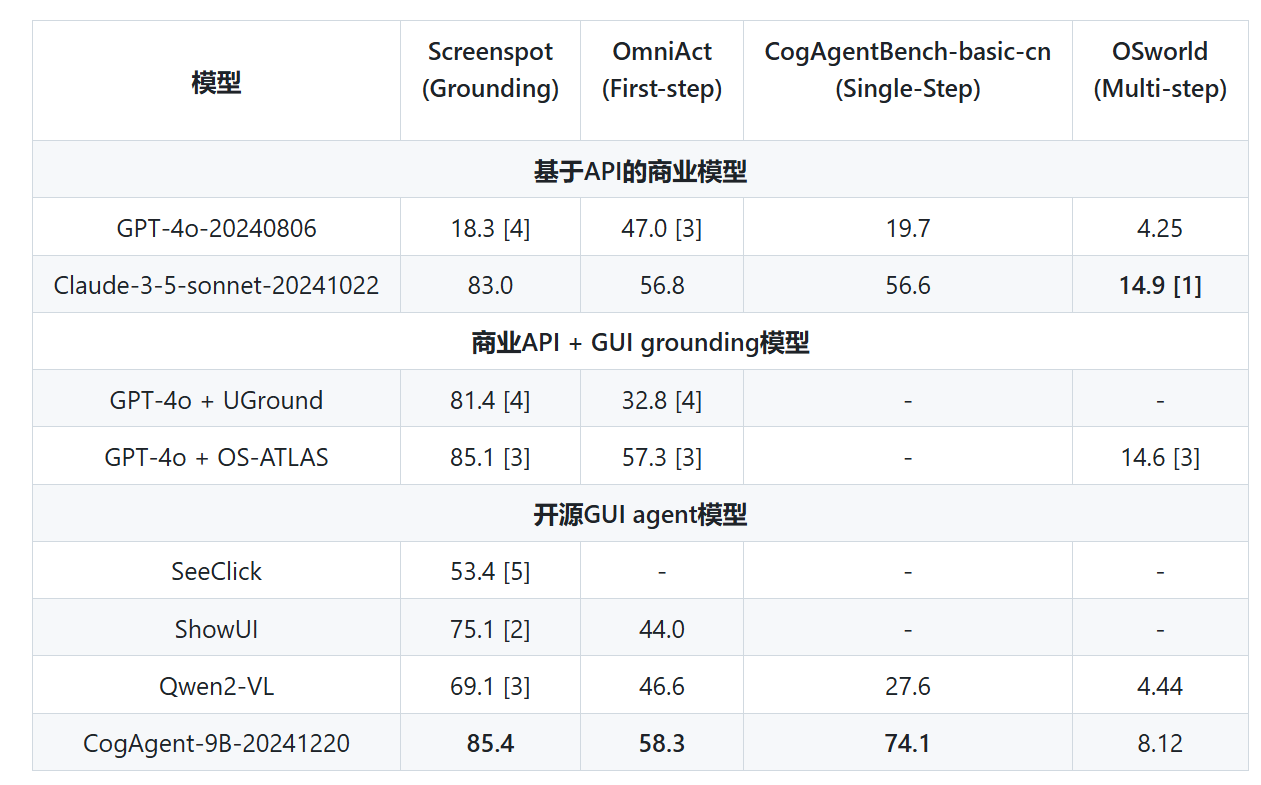
CogAgent-9B-20241220模型在多平台、多类别的 GUI agent 及 GUI grounding benchmarks 上取得了当前最优的结果。
4. GUI Agent的未来展望#
随着CogAgent-9B-20241220的发布,GUI Agent的研究和工程热又迈入一个新的台阶,智谱表示此版CogAgent模型已被应用于智谱AI的GLM-PC产品 (https://cogagent.aminer.cn/home 申请内测),预计25年Q1会开展公测。
在之前,智谱发布了AutoGLM,通过CogAgent控制手机实现点餐、买票等操作,节省用户时间。我的理解这些场景还不是刚需,但是非常有潜力变成一个更通用的入口,不过手机终归还不是生产力平台,GLM-PC产品则更让人值得期待,杀死RPA的最后一根稻草。
现在豆包在强化浏览器的功能,就是要将豆包app打造为一个高生产力的入口平台,或许不远的将来,就能看到豆包支持操作PC各类应用的功能。
未来,GUI Agent产品有望在更多的应用领域中得到应用,如智能家居、智能座舱等,为用户提供更智能、更便捷的交互体验。
关注作者

作者: JadePeng
出处:https://www.cnblogs.com/xiaoqi/p/18633509/CogAgent
版权:本文采用「署名-非商业性使用-相同方式共享 4.0 国际(欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接) 」知识共享许可协议进行许可。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步