
GPU 内存的分级(gpu memory hierarchy)
小普 中科院化学所在读博士研究生
研究课题,计算机模拟并行软件的开发与应用
Email: yaopu2019@126.com (欢迎和我讨论问题)
摘要(Abstact)
GPU 的存储是多样化的, 其速度和数量并不相同,了解GPU存储对于程序的性能调优有着重要的意义。本文介绍如下几个问题:
1.内存类型有什么?2)查询自己设备的内存大小 3)内存访问速度4)不同级别的存储关系5)使用注意事项。各种存储结构的优缺点。
正文
GPU结构图
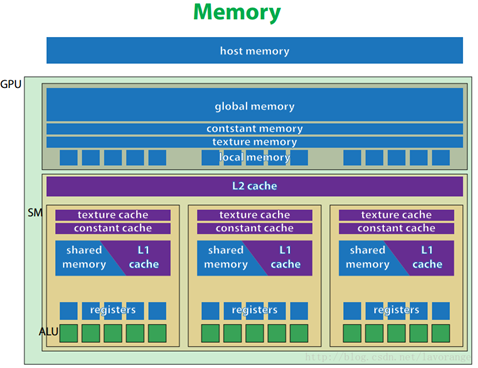
①寄存器内存(Register memory)
优点:访问速度的冠军!
缺点:数量有限
使用:在__global__函数 ,或者___device__ 函数内,定义的普通变量,就是寄存器变量。
例子:
1 //kernel.cu 2 3 __global__ void register_test() 4 5 { 6 7 int a = 1.0; 8 9 double b = 2.0; 10 11 } 12 13 14 15 //main.cu 16 17 int main() 18 19 { 20 21 int nBlock = 100; 22 23 register_test <<<nBlock,128>>>(); 24 25 return 0; 26 27 } 28 29 30 31
②共享内存(Shared memory)
优点:
1缓存速度快 比全局内存 快2两个数量级
2 线程块内,所有线程可以读写。
3 生命周期与线程块同步
缺点:大小有限制
使用:关键词 __shared__ 如 __shared__ double A[128];
适用条件:
使用场合,如规约求和 : a = sum A[i]
如果不是频繁修改的变量,比如矢量加法。
是编程优化中的重要手段!
C[i] = A[i] + B[i] 则没有必要将A,B进行缓存到shared memory 中。
1 /kernel.cu 2 3 __global__ void shared_test() 4 5 { 6 7 __shared__ double A[128]; 8 9 int a = 1.0; 10 11 double b = 2.0; 12 13 int tid = threadIdx.x; 14 15 A[tid] = a; 16 17 }
另外一种开辟shared memory 的方式
kernel 函数内,声明方式
extern __shared__ unsigned int s_out[];
执行 kernel_func<<n_block,block_size,shared_mem_size>>>();
③全局内存 (Global Memory)
优点:
1空间最大(GB级别)
2.可以通过cudaMemcpy 等与Host端,进行交互。
3.生命周期比Kernel函数长
4.所有线程都能访问
缺点:访存最慢
1 //kernel.cu 2 3 __global__ void shared_test(int *B) 4 5 { 6 7 double b = 2.0; 8 9 int tid = threadIdx.x; 10 11 int id = blockDim.x*128 + threadIdx.x; 12 13 int a = B[id] ; 14 15 }
④纹理内存
优点,比普通的global memory 快
缺点:使用起来,需要四个步骤,麻烦一点
适用场景:比较大的只需要读取array,采用纹理方式访问,会实现加速
使用的四个步骤(这里以1维float数组为例子),初学者,自己手敲一遍代码!!!
第一步,声明纹理空间,全局变量:
texture<float, 1, cudaReadModeElementType> tex1D_load;
第二步,绑定纹理
第三步,使用
第四步,解绑定
具体看代码,(最好自己敲一遍!)
1 #include <iostream> 2 3 #include <time.h> 4 5 #include <assert.h> 6 7 #include <cuda_runtime.h> 8 9 #include "helper_cuda.h" 10 11 #include <iostream> 12 13 #include <ctime> 14 15 #include <stdio.h> 16 17 18 19 using namespace std; 20 21 22 23 texture<float, 1, cudaReadModeElementType> tex1D_load; 24 25 //第一步,声明纹理空间,全局变量 26 27 28 29 __global__ void kernel(float *d_out, int size) 30 31 { 32 33 //tex1D_load 为全局变量,不在参数表中 34 35 int index; 36 37 index = blockIdx.x * blockDim.x + threadIdx.x; 38 39 if (index < size) 40 41 { 42 43 d_out[index] = tex1Dfetch(tex1D_load, index); //第三步,抓取纹理内存的值 44 45 //从纹理中抓取值 46 47 printf("%f\n", d_out[index]); 48 49 } 50 51 } 52 53 54 55 int main() 56 57 { 58 59 int size = 120; 60 61 size_t Size = size * sizeof(float); 62 63 float *harray; 64 65 float *d_in; 66 67 float *d_out; 68 69 70 71 harray = new float[size]; 72 73 checkCudaErrors(cudaMalloc((void **)&d_out, Size)); 74 75 checkCudaErrors(cudaMalloc((void **)&d_in, Size)); 76 77 78 79 //initial host memory 80 81 82 83 for (int m = 0; m < 4; m++) 84 85 { 86 87 printf("m = %d\n", m); 88 89 for (int loop = 0; loop < size; loop++) 90 91 { 92 93 harray[loop] = loop + m * 1000; 94 95 } 96 97 //拷贝到d_in中 98 99 checkCudaErrors(cudaMemcpy(d_in, harray, Size, cudaMemcpyHostToDevice)); 100 101 102 103 //第二步,绑定纹理 104 105 checkCudaErrors(cudaBindTexture(0, tex1D_load, d_in, Size)); 106 107 //0表示没有偏移 108 109 110 111 int nBlocks = (Size - 1) / 128 + 1; 112 113 kernel<<<nBlocks, 128>>>(d_out, size); //第三步 114 115 cudaUnbindTexture(tex1D_load); //第四,解纹理 116 117 getLastCudaError("Kernel execution failed"); 118 119 checkCudaErrors(cudaDeviceSynchronize()); 120 121 } 122 123 delete[] harray; 124 125 cudaUnbindTexture(&tex1D_load); 126 127 checkCudaErrors(cudaFree(d_in)); 128 129 checkCudaErrors(cudaFree(d_out)); 130 131 return 0; 132 133 }
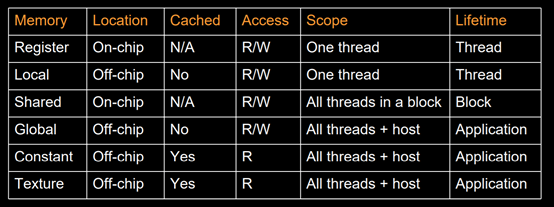
总结如下表
要点:
1 在同一个warp内,多线线程访问一个bank的不同地址,造成confict,影响shared memory 的速度。
2 解决bank confict的方法: padding。
3 const memory 用于存储固定常量,比如固定的参数等。
结束语
小普 中科院化学所在读博士研究生
研究课题,计算机模拟并行软件的开发与应用
Email: yaopu2019@126.com (欢迎和我讨论问题,私信和邮件都OK!)
让程序使得更多人受益!
参考文献
1) CUDA专家手册 GPU编程权威指南 [M] 2014
2) CUDA Toolkit Documentation v10.1.168 https://docs.nvidia.com/cuda/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号