跟着我一起学习大数据——Hadoop
hadoop配置文件:http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.9.0/
一:Hadoop简介
总结下起源于Nutch项目,社区贡献最多是Tom White,之后被雅虎关注,发展越来越好,在医疗健康领域和分子生物领域有很多应用
能做的事:可以搭建一个处理数据的基础平台;、
1.提高读取速度
原理:想要读100T数据,在一个硬盘上时间肯定会很长,但是如果将其分布在100个硬盘上,再将硬盘文件共享,此时读取数据的速度就能提升100倍。
如果要这样实现就需要解决两个主要问题:1)不同硬盘的故障问题,hadoop提供HDFS(Hadoop Distribute FileSystem)分布式文件系统,基本通过保存文件副本的方式,解决出现硬盘故障问题
2)确保每个硬盘拿来的数据正确,提供了MapReduce(一个编程模式)抽象出这些硬盘读写问题并将其转换为map和reduce两部分
官网主页:http://hadoop.apache.org
资源库:http://hadoopbook.com
Hadoop初始版本:Hadoop Common(基础模块,网络通信);Hadoop HDFS( 分布式存储);Hadoop MapReduce(分布式计算)
Hadoop后来版本:多了一个Hadoop YARN(负责资源管理,资源调度,类似Hadoop的操作系统),基于这个层面有了很多应用层面的框架出现(HIVE,Strom,Spark,Flink,MapReduce)
二:MapReduce
通过例子:从国家天气数据中,找到每年的最高气温,文件都是以日志二进制形式保存;
对于这种情况,就非常适合用Hodoop的MapReduce来解决了,主要解题思路:先将每年日志文件通过map函数变为特定集合,再通过reduce函数,在每个map中元素做reduce函数处理这里是取最大值,这样mapreduce就找到每年的最大气温了
Hadoop Streaming 是MapReduce的API
概述:
<1>将分布式计算作业拆分成两个阶段:Mapper和Reducer
<2>Shuffle流程:连接Mapper和Reducer阶段
I.shuffle写入流程
mapper任务将输出数据写到本地磁盘上
II.shuffle读取流程
reducer任务从mapper磁盘上远程读取数据信息
<3>使用场景:离线批处理,速度慢
<4>缺点:各个task任务需要不断申请释放资源,过多使用磁盘
流程图:
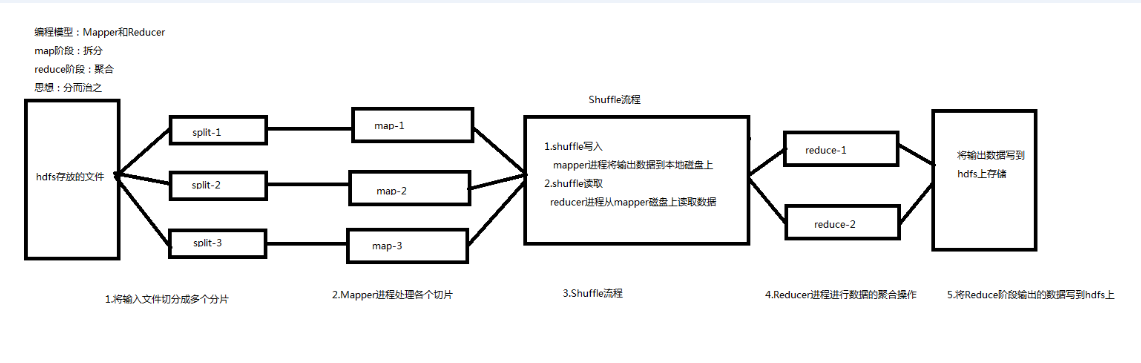
<1>输入文件切片
<2>mapper进程处理切片
<3>shuffle流程
<4>reducer进程聚合数据
<5>输出文件
2.1 具体聊聊
1)案例运行方式
a.单机运行
<1>导入window支持的两个文件:winutils.exe和hadoop.dll放到C:\java\hadoop-2.6.0-cdh5.9.0\bin目录下
<2>配置HADOOP_HOME环境变量(需要重启机器)
临时配置环境变量:System.setProperty("hadoop.home.dir","C:\java\hadoop-2.6.0-cdh5.9.0");
<3>修改NativeIO类,将access0调用处直接换成true
WardCount例子:单机运行java方式mapreduce方式


package org.mapreduce.test; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.SequenceFile.CompressionType; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.compress.GzipCodec; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat; public class WordCount { //临时配置HADOOP_HOME环境变量 static { System.setProperty("hadoop.home.dir", "E:\\hadoop-2.6.0-cdh5.9.0"); } /** * 默认MapReduce是通过TextInputFormat进行切片,并交给Mapper进行处理 * TextInputFormat:key:当前行的首字母的索引,value:当前行数据 * Mapper类参数:输入key类型:Long,输入Value类型:String,输出key类型:String,输出Value类型:Long * MapReduce为了网络传输时序列化文件比较小,执行速度快,对基本类型进行包装,实现自己的序列化 * @author Administrator * */ public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> { LongWritable one = new LongWritable(1); /** * 将每行数据拆分,拆分完输出每个单词和个数 */ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException { String words = value.toString(); //将每行数据拆分成各个单词 String[] wordArr = words.split(" "); //遍历各个单词 for (String word : wordArr) { //输出格式<单词,1> context.write(new Text(word), one); } } } /** * 进行全局聚合 * Reducer参数:输入key类型:String,输入Value类型:Long,输出key类型:String,输出Value类型:Long * @author Administrator * */ public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> { /** * 将map输出结果进行全局聚合 * key:单词, values:个数[1,1,1] */ @Override protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException { Long sum = 0L; for (LongWritable value : values) { //累加单词个数 sum += value.get(); } //输出最终数据结果 context.write(key, new LongWritable(sum)); } } /** * 驱动方法 * @param args * @throws IllegalArgumentException * @throws IOException * @throws ClassNotFoundException * @throws InterruptedException */ public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException { //0.创建一个Job Configuration conf = new Configuration(); //连接hadoop环境 // conf.set("fs.defaultFS", "hdfs://hadoop-senior01.test.com:8020"); Job job = Job.getInstance(conf, "word-count"); //通过类名打成jar包 job.setJarByClass(WordCount.class); //1.输入文件 FileInputFormat.addInputPath(job, new Path(args[0])); //2.编写mapper处理逻辑 job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); //3.shuffle流程(暂时不用处理) //4.编写reducer处理逻辑 job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); //5.输出文件 FileOutputFormat.setOutputPath(job, new Path(args[1])); //6.运行Job boolean result = job.waitForCompletion(true); System.out.println(result ? 1 : 0); } }
自定义的 NativeIO:(通过对原生的做修改)
/** * Licensed to the Apache Software Foundation (ASF) under one * or more contributor license agreements. See the NOTICE file * distributed with this work for additional information * regarding copyright ownership. The ASF licenses this file * to you under the Apache License, Version 2.0 (the * "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ package org.apache.hadoop.io.nativeio; import java.io.File; import java.io.FileDescriptor; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import java.io.RandomAccessFile; import java.lang.reflect.Field; import java.nio.ByteBuffer; import java.nio.MappedByteBuffer; import java.nio.channels.FileChannel; import java.util.Map; import java.util.concurrent.ConcurrentHashMap; import org.apache.hadoop.classification.InterfaceAudience; import org.apache.hadoop.classification.InterfaceStability; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.CommonConfigurationKeys; import org.apache.hadoop.fs.HardLink; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.SecureIOUtils.AlreadyExistsException; import org.apache.hadoop.util.NativeCodeLoader; import org.apache.hadoop.util.Shell; import org.apache.hadoop.util.PerformanceAdvisory; import org.apache.commons.logging.Log; import org.apache.commons.logging.LogFactory; import sun.misc.Unsafe; import com.google.common.annotations.VisibleForTesting; /** * JNI wrappers for various native IO-related calls not available in Java. * These functions should generally be used alongside a fallback to another * more portable mechanism. */ @InterfaceAudience.Private @InterfaceStability.Unstable public class NativeIO { public static class POSIX { // Flags for open() call from bits/fcntl.h public static final int O_RDONLY = 00; public static final int O_WRONLY = 01; public static final int O_RDWR = 02; public static final int O_CREAT = 0100; public static final int O_EXCL = 0200; public static final int O_NOCTTY = 0400; public static final int O_TRUNC = 01000; public static final int O_APPEND = 02000; public static final int O_NONBLOCK = 04000; public static final int O_SYNC = 010000; public static final int O_ASYNC = 020000; public static final int O_FSYNC = O_SYNC; public static final int O_NDELAY = O_NONBLOCK; // Flags for posix_fadvise() from bits/fcntl.h /* No further special treatment. */ public static final int POSIX_FADV_NORMAL = 0; /* Expect random page references. */ public static final int POSIX_FADV_RANDOM = 1; /* Expect sequential page references. */ public static final int POSIX_FADV_SEQUENTIAL = 2; /* Will need these pages. */ public static final int POSIX_FADV_WILLNEED = 3; /* Don't need these pages. */ public static final int POSIX_FADV_DONTNEED = 4; /* Data will be accessed once. */ public static final int POSIX_FADV_NOREUSE = 5; /* Wait upon writeout of all pages in the range before performing the write. */ public static final int SYNC_FILE_RANGE_WAIT_BEFORE = 1; /* Initiate writeout of all those dirty pages in the range which are not presently under writeback. */ public static final int SYNC_FILE_RANGE_WRITE = 2; /* Wait upon writeout of all pages in the range after performing the write. */ public static final int SYNC_FILE_RANGE_WAIT_AFTER = 4; private static final Log LOG = LogFactory.getLog(NativeIO.class); private static boolean nativeLoaded = false; private static boolean fadvisePossible = true; private static boolean syncFileRangePossible = true; static final String WORKAROUND_NON_THREADSAFE_CALLS_KEY = "hadoop.workaround.non.threadsafe.getpwuid"; static final boolean WORKAROUND_NON_THREADSAFE_CALLS_DEFAULT = true; private static long cacheTimeout = -1; private static CacheManipulator cacheManipulator = new CacheManipulator(); public static CacheManipulator getCacheManipulator() { return cacheManipulator; } public static void setCacheManipulator(CacheManipulator cacheManipulator) { POSIX.cacheManipulator = cacheManipulator; } /** * Used to manipulate the operating system cache. */ @VisibleForTesting public static class CacheManipulator { public void mlock(String identifier, ByteBuffer buffer, long len) throws IOException { POSIX.mlock(buffer, len); } public long getMemlockLimit() { return NativeIO.getMemlockLimit(); } public long getOperatingSystemPageSize() { return NativeIO.getOperatingSystemPageSize(); } public void posixFadviseIfPossible(String identifier, FileDescriptor fd, long offset, long len, int flags) throws NativeIOException { NativeIO.POSIX.posixFadviseIfPossible(identifier, fd, offset, len, flags); } public boolean verifyCanMlock() { return NativeIO.isAvailable(); } } /** * A CacheManipulator used for testing which does not actually call mlock. * This allows many tests to be run even when the operating system does not * allow mlock, or only allows limited mlocking. */ @VisibleForTesting public static class NoMlockCacheManipulator extends CacheManipulator { public void mlock(String identifier, ByteBuffer buffer, long len) throws IOException { LOG.info("mlocking " + identifier); } public long getMemlockLimit() { return 1125899906842624L; } public long getOperatingSystemPageSize() { return 4096; } public boolean verifyCanMlock() { return true; } } static { if (NativeCodeLoader.isNativeCodeLoaded()) { try { Configuration conf = new Configuration(); workaroundNonThreadSafePasswdCalls = conf.getBoolean( WORKAROUND_NON_THREADSAFE_CALLS_KEY, WORKAROUND_NON_THREADSAFE_CALLS_DEFAULT); initNative(); nativeLoaded = true; cacheTimeout = conf.getLong( CommonConfigurationKeys.HADOOP_SECURITY_UID_NAME_CACHE_TIMEOUT_KEY, CommonConfigurationKeys.HADOOP_SECURITY_UID_NAME_CACHE_TIMEOUT_DEFAULT) * 1000; LOG.debug("Initialized cache for IDs to User/Group mapping with a " + " cache timeout of " + cacheTimeout/1000 + " seconds."); } catch (Throwable t) { // This can happen if the user has an older version of libhadoop.so // installed - in this case we can continue without native IO // after warning PerformanceAdvisory.LOG.debug("Unable to initialize NativeIO libraries", t); } } } /** * Return true if the JNI-based native IO extensions are available. */ public static boolean isAvailable() { return NativeCodeLoader.isNativeCodeLoaded() && nativeLoaded; } private static void assertCodeLoaded() throws IOException { if (!isAvailable()) { throw new IOException("NativeIO was not loaded"); } } /** Wrapper around open(2) */ public static native FileDescriptor open(String path, int flags, int mode) throws IOException; /** Wrapper around fstat(2) */ private static native Stat fstat(FileDescriptor fd) throws IOException; /** Native chmod implementation. On UNIX, it is a wrapper around chmod(2) */ private static native void chmodImpl(String path, int mode) throws IOException; public static void chmod(String path, int mode) throws IOException { if (!Shell.WINDOWS) { chmodImpl(path, mode); } else { try { chmodImpl(path, mode); } catch (NativeIOException nioe) { if (nioe.getErrorCode() == 3) { throw new NativeIOException("No such file or directory", Errno.ENOENT); } else { LOG.warn(String.format("NativeIO.chmod error (%d): %s", nioe.getErrorCode(), nioe.getMessage())); throw new NativeIOException("Unknown error", Errno.UNKNOWN); } } } } /** Wrapper around posix_fadvise(2) */ static native void posix_fadvise( FileDescriptor fd, long offset, long len, int flags) throws NativeIOException; /** Wrapper around sync_file_range(2) */ static native void sync_file_range( FileDescriptor fd, long offset, long nbytes, int flags) throws NativeIOException; /** * Call posix_fadvise on the given file descriptor. See the manpage * for this syscall for more information. On systems where this * call is not available, does nothing. * * @throws NativeIOException if there is an error with the syscall */ static void posixFadviseIfPossible(String identifier, FileDescriptor fd, long offset, long len, int flags) throws NativeIOException { if (nativeLoaded && fadvisePossible) { try { posix_fadvise(fd, offset, len, flags); } catch (UnsupportedOperationException uoe) { fadvisePossible = false; } catch (UnsatisfiedLinkError ule) { fadvisePossible = false; } } } /** * Call sync_file_range on the given file descriptor. See the manpage * for this syscall for more information. On systems where this * call is not available, does nothing. * * @throws NativeIOException if there is an error with the syscall */ public static void syncFileRangeIfPossible( FileDescriptor fd, long offset, long nbytes, int flags) throws NativeIOException { if (nativeLoaded && syncFileRangePossible) { try { sync_file_range(fd, offset, nbytes, flags); } catch (UnsupportedOperationException uoe) { syncFileRangePossible = false; } catch (UnsatisfiedLinkError ule) { syncFileRangePossible = false; } } } static native void mlock_native( ByteBuffer buffer, long len) throws NativeIOException; /** * Locks the provided direct ByteBuffer into memory, preventing it from * swapping out. After a buffer is locked, future accesses will not incur * a page fault. * * See the mlock(2) man page for more information. * * @throws NativeIOException */ static void mlock(ByteBuffer buffer, long len) throws IOException { assertCodeLoaded(); if (!buffer.isDirect()) { throw new IOException("Cannot mlock a non-direct ByteBuffer"); } mlock_native(buffer, len); } /** * Unmaps the block from memory. See munmap(2). * * There isn't any portable way to unmap a memory region in Java. * So we use the sun.nio method here. * Note that unmapping a memory region could cause crashes if code * continues to reference the unmapped code. However, if we don't * manually unmap the memory, we are dependent on the finalizer to * do it, and we have no idea when the finalizer will run. * * @param buffer The buffer to unmap. */ public static void munmap(MappedByteBuffer buffer) { if (buffer instanceof sun.nio.ch.DirectBuffer) { sun.misc.Cleaner cleaner = ((sun.nio.ch.DirectBuffer)buffer).cleaner(); cleaner.clean(); } } /** Linux only methods used for getOwner() implementation */ private static native long getUIDforFDOwnerforOwner(FileDescriptor fd) throws IOException; private static native String getUserName(long uid) throws IOException; /** * Result type of the fstat call */ public static class Stat { private int ownerId, groupId; private String owner, group; private int mode; // Mode constants public static final int S_IFMT = 0170000; /* type of file */ public static final int S_IFIFO = 0010000; /* named pipe (fifo) */ public static final int S_IFCHR = 0020000; /* character special */ public static final int S_IFDIR = 0040000; /* directory */ public static final int S_IFBLK = 0060000; /* block special */ public static final int S_IFREG = 0100000; /* regular */ public static final int S_IFLNK = 0120000; /* symbolic link */ public static final int S_IFSOCK = 0140000; /* socket */ public static final int S_IFWHT = 0160000; /* whiteout */ public static final int S_ISUID = 0004000; /* set user id on execution */ public static final int S_ISGID = 0002000; /* set group id on execution */ public static final int S_ISVTX = 0001000; /* save swapped text even after use */ public static final int S_IRUSR = 0000400; /* read permission, owner */ public static final int S_IWUSR = 0000200; /* write permission, owner */ public static final int S_IXUSR = 0000100; /* execute/search permission, owner */ Stat(int ownerId, int groupId, int mode) { this.ownerId = ownerId; this.groupId = groupId; this.mode = mode; } Stat(String owner, String group, int mode) { if (!Shell.WINDOWS) { this.owner = owner; } else { this.owner = stripDomain(owner); } if (!Shell.WINDOWS) { this.group = group; } else { this.group = stripDomain(group); } this.mode = mode; } @Override public String toString() { return "Stat(owner='" + owner + "', group='" + group + "'" + ", mode=" + mode + ")"; } public String getOwner() { return owner; } public String getGroup() { return group; } public int getMode() { return mode; } } /** * Returns the file stat for a file descriptor. * * @param fd file descriptor. * @return the file descriptor file stat. * @throws IOException thrown if there was an IO error while obtaining the file stat. */ public static Stat getFstat(FileDescriptor fd) throws IOException { Stat stat = null; if (!Shell.WINDOWS) { stat = fstat(fd); stat.owner = getName(IdCache.USER, stat.ownerId); stat.group = getName(IdCache.GROUP, stat.groupId); } else { try { stat = fstat(fd); } catch (NativeIOException nioe) { if (nioe.getErrorCode() == 6) { throw new NativeIOException("The handle is invalid.", Errno.EBADF); } else { LOG.warn(String.format("NativeIO.getFstat error (%d): %s", nioe.getErrorCode(), nioe.getMessage())); throw new NativeIOException("Unknown error", Errno.UNKNOWN); } } } return stat; } private static String getName(IdCache domain, int id) throws IOException { Map<Integer, CachedName> idNameCache = (domain == IdCache.USER) ? USER_ID_NAME_CACHE : GROUP_ID_NAME_CACHE; String name; CachedName cachedName = idNameCache.get(id); long now = System.currentTimeMillis(); if (cachedName != null && (cachedName.timestamp + cacheTimeout) > now) { name = cachedName.name; } else { name = (domain == IdCache.USER) ? getUserName(id) : getGroupName(id); if (LOG.isDebugEnabled()) { String type = (domain == IdCache.USER) ? "UserName" : "GroupName"; LOG.debug("Got " + type + " " + name + " for ID " + id + " from the native implementation"); } cachedName = new CachedName(name, now); idNameCache.put(id, cachedName); } return name; } static native String getUserName(int uid) throws IOException; static native String getGroupName(int uid) throws IOException; private static class CachedName { final long timestamp; final String name; public CachedName(String name, long timestamp) { this.name = name; this.timestamp = timestamp; } } private static final Map<Integer, CachedName> USER_ID_NAME_CACHE = new ConcurrentHashMap<Integer, CachedName>(); private static final Map<Integer, CachedName> GROUP_ID_NAME_CACHE = new ConcurrentHashMap<Integer, CachedName>(); private enum IdCache { USER, GROUP } public final static int MMAP_PROT_READ = 0x1; public final static int MMAP_PROT_WRITE = 0x2; public final static int MMAP_PROT_EXEC = 0x4; public static native long mmap(FileDescriptor fd, int prot, boolean shared, long length) throws IOException; public static native void munmap(long addr, long length) throws IOException; } private static boolean workaroundNonThreadSafePasswdCalls = false; public static class Windows { // Flags for CreateFile() call on Windows public static final long GENERIC_READ = 0x80000000L; public static final long GENERIC_WRITE = 0x40000000L; public static final long FILE_SHARE_READ = 0x00000001L; public static final long FILE_SHARE_WRITE = 0x00000002L; public static final long FILE_SHARE_DELETE = 0x00000004L; public static final long CREATE_NEW = 1; public static final long CREATE_ALWAYS = 2; public static final long OPEN_EXISTING = 3; public static final long OPEN_ALWAYS = 4; public static final long TRUNCATE_EXISTING = 5; public static final long FILE_BEGIN = 0; public static final long FILE_CURRENT = 1; public static final long FILE_END = 2; public static final long FILE_ATTRIBUTE_NORMAL = 0x00000080L; /** * Create a directory with permissions set to the specified mode. By setting * permissions at creation time, we avoid issues related to the user lacking * WRITE_DAC rights on subsequent chmod calls. One example where this can * occur is writing to an SMB share where the user does not have Full Control * rights, and therefore WRITE_DAC is denied. * * @param path directory to create * @param mode permissions of new directory * @throws IOException if there is an I/O error */ public static void createDirectoryWithMode(File path, int mode) throws IOException { createDirectoryWithMode0(path.getAbsolutePath(), mode); } /** Wrapper around CreateDirectory() on Windows */ private static native void createDirectoryWithMode0(String path, int mode) throws NativeIOException; /** Wrapper around CreateFile() on Windows */ public static native FileDescriptor createFile(String path, long desiredAccess, long shareMode, long creationDisposition) throws IOException; /** * Create a file for write with permissions set to the specified mode. By * setting permissions at creation time, we avoid issues related to the user * lacking WRITE_DAC rights on subsequent chmod calls. One example where * this can occur is writing to an SMB share where the user does not have * Full Control rights, and therefore WRITE_DAC is denied. * * This method mimics the semantics implemented by the JDK in * {@link java.io.FileOutputStream}. The file is opened for truncate or * append, the sharing mode allows other readers and writers, and paths * longer than MAX_PATH are supported. (See io_util_md.c in the JDK.) * * @param path file to create * @param append if true, then open file for append * @param mode permissions of new directory * @return FileOutputStream of opened file * @throws IOException if there is an I/O error */ public static FileOutputStream createFileOutputStreamWithMode(File path, boolean append, int mode) throws IOException { long desiredAccess = GENERIC_WRITE; long shareMode = FILE_SHARE_READ | FILE_SHARE_WRITE; long creationDisposition = append ? OPEN_ALWAYS : CREATE_ALWAYS; return new FileOutputStream(createFileWithMode0(path.getAbsolutePath(), desiredAccess, shareMode, creationDisposition, mode)); } /** Wrapper around CreateFile() with security descriptor on Windows */ private static native FileDescriptor createFileWithMode0(String path, long desiredAccess, long shareMode, long creationDisposition, int mode) throws NativeIOException; /** Wrapper around SetFilePointer() on Windows */ public static native long setFilePointer(FileDescriptor fd, long distanceToMove, long moveMethod) throws IOException; /** Windows only methods used for getOwner() implementation */ private static native String getOwner(FileDescriptor fd) throws IOException; /** Supported list of Windows access right flags */ public static enum AccessRight { ACCESS_READ (0x0001), // FILE_READ_DATA ACCESS_WRITE (0x0002), // FILE_WRITE_DATA ACCESS_EXECUTE (0x0020); // FILE_EXECUTE private final int accessRight; AccessRight(int access) { accessRight = access; } public int accessRight() { return accessRight; } }; /** Windows only method used to check if the current process has requested * access rights on the given path. */ private static native boolean access0(String path, int requestedAccess); /** * Checks whether the current process has desired access rights on * the given path. * * Longer term this native function can be substituted with JDK7 * function Files#isReadable, isWritable, isExecutable. * * @param path input path * @param desiredAccess ACCESS_READ, ACCESS_WRITE or ACCESS_EXECUTE * @return true if access is allowed * @throws IOException I/O exception on error */ public static boolean access(String path, AccessRight desiredAccess) throws IOException { return true; } /** * Extends both the minimum and maximum working set size of the current * process. This method gets the current minimum and maximum working set * size, adds the requested amount to each and then sets the minimum and * maximum working set size to the new values. Controlling the working set * size of the process also controls the amount of memory it can lock. * * @param delta amount to increment minimum and maximum working set size * @throws IOException for any error * @see POSIX#mlock(ByteBuffer, long) */ public static native void extendWorkingSetSize(long delta) throws IOException; static { if (NativeCodeLoader.isNativeCodeLoaded()) { try { initNative(); nativeLoaded = true; } catch (Throwable t) { // This can happen if the user has an older version of libhadoop.so // installed - in this case we can continue without native IO // after warning PerformanceAdvisory.LOG.debug("Unable to initialize NativeIO libraries", t); } } } } private static final Log LOG = LogFactory.getLog(NativeIO.class); private static boolean nativeLoaded = false; static { if (NativeCodeLoader.isNativeCodeLoaded()) { try { initNative(); nativeLoaded = true; } catch (Throwable t) { // This can happen if the user has an older version of libhadoop.so // installed - in this case we can continue without native IO // after warning PerformanceAdvisory.LOG.debug("Unable to initialize NativeIO libraries", t); } } } /** * Return true if the JNI-based native IO extensions are available. */ public static boolean isAvailable() { return NativeCodeLoader.isNativeCodeLoaded() && nativeLoaded; } /** Initialize the JNI method ID and class ID cache */ private static native void initNative(); /** * Get the maximum number of bytes that can be locked into memory at any * given point. * * @return 0 if no bytes can be locked into memory; * Long.MAX_VALUE if there is no limit; * The number of bytes that can be locked into memory otherwise. */ static long getMemlockLimit() { return isAvailable() ? getMemlockLimit0() : 0; } private static native long getMemlockLimit0(); /** * @return the operating system's page size. */ static long getOperatingSystemPageSize() { try { Field f = Unsafe.class.getDeclaredField("theUnsafe"); f.setAccessible(true); Unsafe unsafe = (Unsafe)f.get(null); return unsafe.pageSize(); } catch (Throwable e) { LOG.warn("Unable to get operating system page size. Guessing 4096.", e); return 4096; } } private static class CachedUid { final long timestamp; final String username; public CachedUid(String username, long timestamp) { this.timestamp = timestamp; this.username = username; } } private static final Map<Long, CachedUid> uidCache = new ConcurrentHashMap<Long, CachedUid>(); private static long cacheTimeout; private static boolean initialized = false; /** * The Windows logon name has two part, NetBIOS domain name and * user account name, of the format DOMAIN\UserName. This method * will remove the domain part of the full logon name. * * @param Fthe full principal name containing the domain * @return name with domain removed */ private static String stripDomain(String name) { int i = name.indexOf('\\'); if (i != -1) name = name.substring(i + 1); return name; } public static String getOwner(FileDescriptor fd) throws IOException { ensureInitialized(); if (Shell.WINDOWS) { String owner = Windows.getOwner(fd); owner = stripDomain(owner); return owner; } else { long uid = POSIX.getUIDforFDOwnerforOwner(fd); CachedUid cUid = uidCache.get(uid); long now = System.currentTimeMillis(); if (cUid != null && (cUid.timestamp + cacheTimeout) > now) { return cUid.username; } String user = POSIX.getUserName(uid); LOG.info("Got UserName " + user + " for UID " + uid + " from the native implementation"); cUid = new CachedUid(user, now); uidCache.put(uid, cUid); return user; } } /** * Create a FileInputStream that shares delete permission on the * file opened, i.e. other process can delete the file the * FileInputStream is reading. Only Windows implementation uses * the native interface. */ public static FileInputStream getShareDeleteFileInputStream(File f) throws IOException { if (!Shell.WINDOWS) { // On Linux the default FileInputStream shares delete permission // on the file opened. // return new FileInputStream(f); } else { // Use Windows native interface to create a FileInputStream that // shares delete permission on the file opened. // FileDescriptor fd = Windows.createFile( f.getAbsolutePath(), Windows.GENERIC_READ, Windows.FILE_SHARE_READ | Windows.FILE_SHARE_WRITE | Windows.FILE_SHARE_DELETE, Windows.OPEN_EXISTING); return new FileInputStream(fd); } } /** * Create a FileInputStream that shares delete permission on the * file opened at a given offset, i.e. other process can delete * the file the FileInputStream is reading. Only Windows implementation * uses the native interface. */ public static FileInputStream getShareDeleteFileInputStream(File f, long seekOffset) throws IOException { if (!Shell.WINDOWS) { RandomAccessFile rf = new RandomAccessFile(f, "r"); if (seekOffset > 0) { rf.seek(seekOffset); } return new FileInputStream(rf.getFD()); } else { // Use Windows native interface to create a FileInputStream that // shares delete permission on the file opened, and set it to the // given offset. // FileDescriptor fd = NativeIO.Windows.createFile( f.getAbsolutePath(), NativeIO.Windows.GENERIC_READ, NativeIO.Windows.FILE_SHARE_READ | NativeIO.Windows.FILE_SHARE_WRITE | NativeIO.Windows.FILE_SHARE_DELETE, NativeIO.Windows.OPEN_EXISTING); if (seekOffset > 0) NativeIO.Windows.setFilePointer(fd, seekOffset, NativeIO.Windows.FILE_BEGIN); return new FileInputStream(fd); } } /** * Create the specified File for write access, ensuring that it does not exist. * @param f the file that we want to create * @param permissions we want to have on the file (if security is enabled) * * @throws AlreadyExistsException if the file already exists * @throws IOException if any other error occurred */ public static FileOutputStream getCreateForWriteFileOutputStream(File f, int permissions) throws IOException { if (!Shell.WINDOWS) { // Use the native wrapper around open(2) try { FileDescriptor fd = NativeIO.POSIX.open(f.getAbsolutePath(), NativeIO.POSIX.O_WRONLY | NativeIO.POSIX.O_CREAT | NativeIO.POSIX.O_EXCL, permissions); return new FileOutputStream(fd); } catch (NativeIOException nioe) { if (nioe.getErrno() == Errno.EEXIST) { throw new AlreadyExistsException(nioe); } throw nioe; } } else { // Use the Windows native APIs to create equivalent FileOutputStream try { FileDescriptor fd = NativeIO.Windows.createFile(f.getCanonicalPath(), NativeIO.Windows.GENERIC_WRITE, NativeIO.Windows.FILE_SHARE_DELETE | NativeIO.Windows.FILE_SHARE_READ | NativeIO.Windows.FILE_SHARE_WRITE, NativeIO.Windows.CREATE_NEW); NativeIO.POSIX.chmod(f.getCanonicalPath(), permissions); return new FileOutputStream(fd); } catch (NativeIOException nioe) { if (nioe.getErrorCode() == 80) { // ERROR_FILE_EXISTS // 80 (0x50) // The file exists throw new AlreadyExistsException(nioe); } throw nioe; } } } private synchronized static void ensureInitialized() { if (!initialized) { cacheTimeout = new Configuration().getLong("hadoop.security.uid.cache.secs", 4*60*60) * 1000; LOG.info("Initialized cache for UID to User mapping with a cache" + " timeout of " + cacheTimeout/1000 + " seconds."); initialized = true; } } /** * A version of renameTo that throws a descriptive exception when it fails. * * @param src The source path * @param dst The destination path * * @throws NativeIOException On failure. */ public static void renameTo(File src, File dst) throws IOException { if (!nativeLoaded) { if (!src.renameTo(dst)) { throw new IOException("renameTo(src=" + src + ", dst=" + dst + ") failed."); } } else { renameTo0(src.getAbsolutePath(), dst.getAbsolutePath()); } } public static void link(File src, File dst) throws IOException { if (!nativeLoaded) { HardLink.createHardLink(src, dst); } else { link0(src.getAbsolutePath(), dst.getAbsolutePath()); } } /** * A version of renameTo that throws a descriptive exception when it fails. * * @param src The source path * @param dst The destination path * * @throws NativeIOException On failure. */ private static native void renameTo0(String src, String dst) throws NativeIOException; private static native void link0(String src, String dst) throws NativeIOException; /** * Unbuffered file copy from src to dst without tainting OS buffer cache * * In POSIX platform: * It uses FileChannel#transferTo() which internally attempts * unbuffered IO on OS with native sendfile64() support and falls back to * buffered IO otherwise. * * It minimizes the number of FileChannel#transferTo call by passing the the * src file size directly instead of a smaller size as the 3rd parameter. * This saves the number of sendfile64() system call when native sendfile64() * is supported. In the two fall back cases where sendfile is not supported, * FileChannle#transferTo already has its own batching of size 8 MB and 8 KB, * respectively. * * In Windows Platform: * It uses its own native wrapper of CopyFileEx with COPY_FILE_NO_BUFFERING * flag, which is supported on Windows Server 2008 and above. * * Ideally, we should use FileChannel#transferTo() across both POSIX and Windows * platform. Unfortunately, the wrapper(Java_sun_nio_ch_FileChannelImpl_transferTo0) * used by FileChannel#transferTo for unbuffered IO is not implemented on Windows. * Based on OpenJDK 6/7/8 source code, Java_sun_nio_ch_FileChannelImpl_transferTo0 * on Windows simply returns IOS_UNSUPPORTED. * * Note: This simple native wrapper does minimal parameter checking before copy and * consistency check (e.g., size) after copy. * It is recommended to use wrapper function like * the Storage#nativeCopyFileUnbuffered() function in hadoop-hdfs with pre/post copy * checks. * * @param src The source path * @param dst The destination path * @throws IOException */ public static void copyFileUnbuffered(File src, File dst) throws IOException { if (nativeLoaded && Shell.WINDOWS) { copyFileUnbuffered0(src.getAbsolutePath(), dst.getAbsolutePath()); } else { FileInputStream fis = null; FileOutputStream fos = null; FileChannel input = null; FileChannel output = null; try { fis = new FileInputStream(src); fos = new FileOutputStream(dst); input = fis.getChannel(); output = fos.getChannel(); long remaining = input.size(); long position = 0; long transferred = 0; while (remaining > 0) { transferred = input.transferTo(position, remaining, output); remaining -= transferred; position += transferred; } } finally { IOUtils.cleanup(LOG, output); IOUtils.cleanup(LOG, fos); IOUtils.cleanup(LOG, input); IOUtils.cleanup(LOG, fis); } } } private static native void copyFileUnbuffered0(String src, String dst) throws NativeIOException; }
b.远程调用运行
含义:windows系统的代码直接连接linux系统的hadoop环境进行运行,运行结果可以存到本地或HDFS服务器上
conf.set("fs.defaultFS", "hdfs://hadoop-senior01.test.com:8020");
c.打jar包放到hadoop集群中运行
<1>两种方式打jar包
I.eclipse打jar包
II.maven打jar包
<2>放到linux环境中运行
bin/yarn jar hadoop-test.jar file:/opt/module/hadoop-2.6.0/LICENSE.txt file:/opt/out
d.InputFormat
<1>功能
I.对输入文件进行切分,生成InputSplit切片
II.创建RecordReader,将InputSplit交给Mapper进程读取
<2>子类
DBInputFormat/FileInputFormat
FileInputFormat:TextInputFormat/KeyValueTextInputFormat/SequenceFileInputFormat/NLineInputFormat/CombineFileInputFormat
<3>SequenceFileInputFormat使用
I.生成SequenceFile文件(<k,v>形式的二进制文件)
II.map/reduce/驱动方法
job.setInputFormatClass(SequenceFileInputFormat.class);
WardCount(这里的是将入参变为由下面一个脚本执行获得的SequenceFile文件做处理到yarn平台)
package sequencefile; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.SequenceFile.CompressionType; import org.apache.hadoop.io.compress.DefaultCodec; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat; public class WordCount { //临时配置HADOOP_HOME环境变量 static { System.setProperty("hadoop.home.dir", "E:\\hadoop-2.6.0-cdh5.9.0"); } /** * 默认MapReduce是通过TextInputFormat进行切片,并交给Mapper进行处理 * TextInputFormat:key:当前行的首字母的索引,value:当前行数据 * Mapper类参数:输入key类型:Long,输入Value类型:String,输出key类型:String,输出Value类型:Long * MapReduce为了网络传输时序列化文件比较小,执行速度快,对基本类型进行包装,实现自己的序列化 * @author Administrator * */ public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> { LongWritable one = new LongWritable(1); /** * 将每行数据拆分,拆分完输出每个单词和个数 */ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException { String words = value.toString(); //将每行数据拆分成各个单词 String[] wordArr = words.split(" "); //遍历各个单词 for (String word : wordArr) { //输出格式<单词,1> context.write(new Text(word), one); } } } /** * 进行全局聚合 * Reducer参数:输入key类型:String,输入Value类型:Long,输出key类型:String,输出Value类型:Long * @author Administrator * */ public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> { /** * 将map输出结果进行全局聚合 * key:单词, values:个数[1,1,1] */ @Override protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException { Long sum = 0L; for (LongWritable value : values) { //累加单词个数 sum += value.get(); } //输出最终数据结果 context.write(key, new LongWritable(sum)); } } /** * 驱动方法 * @param args * @throws IllegalArgumentException * @throws IOException * @throws ClassNotFoundException * @throws InterruptedException */ public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException { //0.创建一个Job Configuration conf = new Configuration(); //连接hadoop环境 // conf.set("fs.defaultFS", "hdfs://hadoop-senior01.test.com:8020"); Job job = Job.getInstance(conf, "word-count"); //通过类名打成jar包 job.setJarByClass(WordCount.class); //1.输入文件 FileInputFormat.addInputPath(job, new Path(args[0])); //指定以SequenceFileInputFormat处理sequencefile文件 job.setInputFormatClass(SequenceFileInputFormat.class); //2.编写mapper处理逻辑 job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); //3.shuffle流程(暂时不用处理) //4.编写reducer处理逻辑 job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); //5.输出文件 FileOutputFormat.setOutputPath(job, new Path(args[1])); //序列化文件的压缩类型:None、Block、Record SequenceFileOutputFormat.setOutputCompressionType(job, CompressionType.BLOCK); //压缩格式:default、gzip、lz4、snappy SequenceFileOutputFormat.setOutputCompressorClass(job, DefaultCodec.class); //指定输出格式为序列化文件输出 job.setOutputFormatClass(SequenceFileOutputFormat.class); //6.运行Job boolean result = job.waitForCompletion(true); System.out.println(result ? 1 : 0); } }
GenerateSequenceFile
package sequencefile; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.SequenceFile; import org.apache.hadoop.io.SequenceFile.Writer; import org.apache.hadoop.io.Text; /** * 生成sequencefile文件 * @author Administrator * */ public class GenerateSequenceFile { public static void main(String[] args) throws IOException { //1.sequenceFile文件是通过SequenceFile类生成的 //createWriter方法参数:conf:hadop配置项,name:文件名, //keyClass:key的数据类型;valClass:值得数据类型 //指定文件名称 Writer.Option name = Writer.file(new Path("file:/e:/sf")); //指定key的类型 Writer.Option keyClass = Writer.keyClass(LongWritable.class); //指定value的类型 Writer.Option valClass = Writer.valueClass(Text.class); //hadoop配置项 Configuration conf = new Configuration(); //创建输出流 Writer writer = SequenceFile.createWriter(conf, name, keyClass, valClass); //读取文本文件 FileSystem fs = FileSystem.get(conf); FSDataInputStream in = fs.open(new Path("file:/e:/words.txt")); String line = null; Long num = 0L; while ((line = in.readLine())!=null) { //不断递增key值 num++; //输出每行数据到sequencefile中 writer.append(new LongWritable(num), new Text(line)); } IOUtils.closeStream(writer); } }
e.输入切片(InputSplit)
<1>什么时候切分
client端进行切分,切分后交给YARN服务器执行
<2>切片中存储的内容
数据长度、数据存储位置
<3>切片大小
minSize = max{minSplitSize, mapred.min.split.size}
maxSize = mapred.max.split.size
splitSize = max{minSize, min{maxSize, blockSize}}
<4>切片数量(mapper进程数量)
总文件大小/切片大小
f.reduce个数
g.outputFormat
<1>功能
I.判断输出目录是否存在
II.将结果输出到表或文件汇总
<2>子类
DBOutputFormat/FileOutputFormat
FileOutputFormat:TextOutputFormat/MapFileOutputFormat/SequenceFileOutputFormat/MultipleOutputs
<3>SequenceFileOutputFormat使用
I.生成SequenceFile文件(<k,v>形式的二进制文件)
II.map/reduce/驱动方法
job.setInputFormatClass(SequenceFileInputFormat.class);
h.partitioner分区器
<1>功能
I.位置:在mapper和reducer处理逻辑之间,shuffle写入流程开始的时候
II.将map输出结果分发到不同的reduce上
III.分区数和reducer数量一样
<2>Partitioner子类
HashPartitioner、KeyFieldBasedPartitioner、BinaryPartitioner、TotalOrderedPartitioner
2.2.Shuffle流程

1)位置
在mapper和reducer处理逻辑之间,连接map和reduce的纽带
2)功能
Shuffle的本义就是洗牌、混洗,把有规律有一定规则的数据尽量转为一组无规律的数据,越随机越好。MapReduce中的Shuffle更像是洗牌的逆过程,把一组无规律的数据变为一组有规律的数据
从shuffle写入流程(map端)到shuffle读取流程(reduce端)整个过程可以被广义的称为Shuffle。Shuffle横跨Map端和Reduce端,在Map端包含Splill写过程,在Reduce端包含copy和sort读过程
3)写入流程
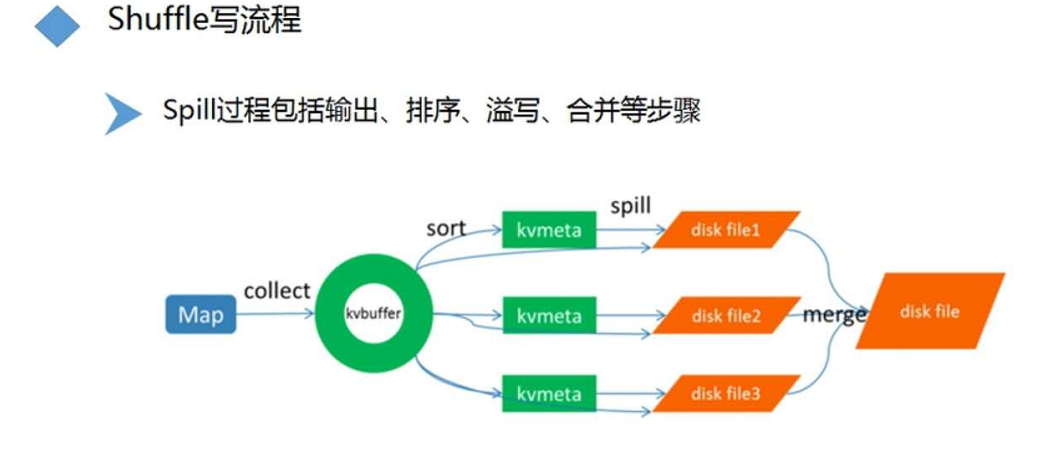
a.map输出数据经过分区,分区完后通过collect收集到内存环形缓冲区kvbuffer
b.sort将缓冲区中的数据排序
<1>按分区排序
<2>每个分区中数据按key进行排序
c.spill线程溢写到本地磁盘
每次缓冲区满就溢写,会产生很多小文件
d.merge合并将小文件合并到大文件
4)读取流程
a.copy
reduce端通过HTTP协议从mapper磁盘上读取相应分区的数据
b.merge-sort
<1>如果读取的数据在reduce内存中能放得下,就直接放到内存中。当内存空间达到一定阈值,就merge成一个磁盘文件
<2>如果读取过来的数据内存放不下,就直接输出到磁盘上。
每个mapper过来的数据,就建一个文件。当文件数达到一定阈值,就merge成一个大文件。
三:HDFS 分布式文件系统
3.1 设计原则
1)超大文件;2)流数据访问;3)商用硬件;4)低时间延迟的数据访问;5)大量的小文件;6)度用户写入,任意修改文件
3.2 概念
3.2.1 块
一般文件系统有块的概念512字节,是数据读写最小单元,但是HDFS分布式文件系统也有块的概念,确实默认128M大小,弄这么大的原因:
1)最小化寻址开销
2)有了这个块的概念,一个文件可以存在在不同的网络空间
3)使用抽象块而非整个文件作为存储单元,大大简化存储子系统的设计
fsck命令可以查看块信息
3.2.2 namenode和datanode
namenode:管理文件命名空间,维护整个系统树和整个系统树内所有的文件和目录,这些信息在磁盘上以文件形式永久保存在本地磁盘:命名空间镜像文件+编辑日志文件
datanode:文件系统的工作节点,他根据需要存储检索数据块
客户端POSIX:可移植操作系统界面的文件系统接口,通过他与namenode,datanode交互
联邦HDFS:namenode在内存中保存文件系统中每个文件和每个数据块的应用关系,意味着对于一个拥有大量文件的超大集群来说,存在限制了系统横向扩展的瓶颈,次数通过这个模式就可以解决
想要访问方法:客户端需要使用客户端挂载的数据表将文件路径映射到namenode
3.2.3 块缓存
datanode从磁盘中读取块,对于频繁访问的文件,其对应的块可以被显示的缓存起来,用户或者应用可以通过增加一个cache directive 来告诉namenode需要缓存哪些文件及缓存多久
3.2.4 HDFS高可用
通过NFS或者日志管理器QJM的机制在活动namenode失效之后,备用namenode能快速切换(热切换),如果配用的namenode也坏了,管理员也可以申明一个namenode冷启动
3.2.5 文件系统
文件系统的基本操作如:%hadoop fa -copyFromLocal input/docs/qq.txt \ hdfs://localhost/user/qq.txt;//将本地文件复制到HDFS中
HDFS具备一定的权限机制
由于Hadoop的抽象的文件系统概念,HDFS只是其中一个实现,定义了很多接口可供java调用;
这些Hadoop的api处理java直接调用还可以通过http调用,但是不到万不得已不用通过这个方式,会有延时(内部通过HttpFS代理,WebHDFS)
HttpFS:提供代理
WebHDFS:http接口都是通过这个协议开发的
libhdfs:C语言库,可允许你调用hadoop的api
HFS:通过NFSv3网关将HFDS挂载为本地客户端的文件系统是可行的(如何配置你可以自己百度小伙子)
FUSE:用户空间文件系统,允许将用户空间实现的文件系统作为Unix文件系统集成(HFS相对来说更好推荐)
3.2.6 Java接口
1)从Hadoop的URL中读取数据:
2)通过FileSystem API读取数据:FSDataInputStream对象
3)写入数据:FSDataOutputStream
4)创建目录:create()
5)查询文件系统:文件元数据:FileStatus:包含了文件长度、块大小、副本、修改时间、所有者及权限信息;FileSystem的listStatus列出文件
3.2.7 文件模式
可用通过通配符方式匹配到更多文件globStatus():返回路径模式与指定模式匹配的所有FileStatus对象组成的数组(正则表达式模式如:*,?[ab]......)
PathFilter对象:通配符模式
删除数据:delete()
一致模式:hflush,hsync
通过distcp并行复制:%hadoop distcp file1 file2
保证HDFS集群的均衡,对系统性能是非常棒的条件,可通过均衡器(balancer)达到这一点
3.3 深入了解
1)三大组件
NameNode、DataNode、SecondaryNameNode
2)NameNode
a.作用
存储元数据(文件名、创建时间、大小、权限、文件与block块映射关系)
b.数据存储目录
dfs.namenode.name.dir
3)DataNode
a.作用
存储真实的数据信息
b.数据存储目录
dfs.datanode.data.dir
c.block块:默认128M,通过dfs.blocksize设置
d.副本策略
<1>默认是3个副本,通过dfs.replication配置
<2>存放形式:
I.如果客户端在集群中,第一个副本放到客户端机器上;否则第一个副本随机挑选一个不忙的机器
II.第二个副本放到和第一个副本不同的机架上的一个服务器上
III.第三个副本放到和第二个副本相同机架不同服务器上
IV.如果还有更多副本,就随机存放
e.DataNode与NameNode通信
<1>DN启动后向NN进行注册,注册完后周期性(1小时)向NN上传块报告(blockreport)
blockreport:block与datanode的映射关系(第二映射关系)
作用:DN通过上传块报告,能更新NN内存中的映射关系
<2>DN发送心跳(3s)给NN,超过10m,就认为DN不可用了
4)SecondaryNameNode
a.作用
减轻NameNode压力,将edits编辑日志文件和fsimage镜像文件进行合并
b.执行流程
<1>周期性发送请求给NN,获取fsimage和edits
<2>NN收到请求后,生成一个空的edits.new文件
<3>NN给SNN发送fsimage和edits
<4>SNN将fsimage文件加载到内存,合并edits文件
<5>SNN生成新的镜像文件fsimage.ckpt
<6>SNN发送fsimage.ckpt给NN
<7>NN将fsimage.ckpt替换fsimage文件,将edits.new重命名为edits文件
5)读写流程
a.写入流程
<1>客户端给NN通信,创建文件
<2>NN判断文件是否存在,是否有权限,如果有就创建文件,否则失败报错
<3>客户端将数据进行切片,放到缓冲区队列中;每个切片都需要给NN发送请求,NN给客户端返回DN列表
<4>客户端连接DN列表写入数据
<5>DN根据副本策略将数据发送给其他DN
<6>DN给客户端返回ACK包,如果成功就执行下一个切片,如果失败就重试
b.读取流程
<1>客户端给NN通信,读取文件
<2>NN查找文件与block块关系,block与DN关系返回给客户端
<3>客户端创建输入流,根据NN返回的关系,去DN查找block数据
<4>DN查找block块数据,返回给客户端
<5>客户端通过校验和比对block是否损坏。如果损坏,就取另外DN上的block块;如果没有,就读取下一个block块
6)安全模式
a.含义
客户端只能进行查看,不能进行写入、删除操作
b.作用
NN启动后进入安全模式,检查数据块和DN的完整性
c.判断条件
<1>副本数达到要求的block块数占所有block块总数的比例
dfs.namenode.replication.min:副本数最小要求,默认1
dfs.namenode.safemode.threshold-pct:比例 0.999f
<2>可用DN数达到要求
dfs.namenode.safemode.min.datanodes:最小可用DN数,默认0
<3>前两个条件满足后维护一段时间
dfs.namenode.safemode.extension:维持一段时间,默认1ms
3.4 HDFS命令行及Java API操作
1)HDFS命令行
a.bin/hdfs dfs命令:
<1> -help:查看有哪些命令
<2> -mkdir:创建目录,-p:创建多个目录
<3> -put:上传本地文件到HDFS服务器上
-copyFromLocal
-moveFromLocal
<4> -ls:查看指定目录下有哪些文件和子目录,-R:递归地查看有哪些文件和目录
<5> -du(s):查看目录或文件的大小
-count 【-q】
<6> -mv/-cp:移动/复制目录或文件
<7> -rm -r:删除目录或文件,-r:递归删除
<8> -get:将服务器上的文件下载到本地
-copyToLocal
-moveToLocal
<9> -cat/-text:查看服务器上文本格式的文件
b.bin/hdfs dfsadmin命令
<1>-report:查看文件系统的基本信息和统计信息
<2>-safemode enter | leave | wait : 安全模式命令
<3>-refreshNodes : 重新读取hosts和exclude文件,在新增节点和注销节点时使用
<4>-finalizeUpgrade : 终结HDFS的升级操作
<5>-setQuota <quota> <dirname>:为每个目录<dirname>设置配额<quota>
<6>-clrQuota <dirname>:为每个目录清楚配额设定
2)HDFS Java API操作(filesystem)
参考:http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.9.0/api/index.html
创建目录:mkdirs 上传文件:create/put或者copyFormLocalFile 列出目录内容:listStatus 显示目录或者目录的元数据:getFlieStatus 下载文件:open/get获得copyToLocalFile 删除文件或者目录:delete
下面是java调用方法类方法实例:
package org.hdfs.test; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; public class HdfsTest { public static void main(String[] args) { // // 获取访问入口:FileSystem // FileSystem fileSystem = getHadoopFileSystem(); // System.out.println(fileSystem); // //创建目录 // boolean result = createPath("/test"); // System.out.println(result); // //创建文件 // boolean result = createFile("/test/test.txt", "hello world"); // System.out.println(result); //上传文件 //输出pathName可以是目录也可以是文件 // putFile2HDFS("E://word.txt", "/test"); //输出pathName必须是文件 // putFile2HDFS2("E://word.txt", "/test/word1.txt"); //获取元数据信息 // list("/test"); //下载文件 //第二个参数是文件路径 // getFileFromHDFS("/test/test.txt", "E://test"); //第二个参数是文件路径 // getFileFromHDFS2("/test/word1.txt", "E://word1"); //删除文件或目录 delete("/test"); } /** * 生成文件系统FileSystem * @return */ public static FileSystem getHadoopFileSystem() { Configuration conf = new Configuration(); //执行NameNode访问地址 conf.set("fs.defaultFS", "hdfs://hadoop-senior01.test.com:8020"); try { //通过调用FileSystem工厂模式get方法生成FileSystem FileSystem fileSystem = FileSystem.get(conf); return fileSystem; } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } return null; } /** * 创建目录 * @param pathName * @return */ public static boolean createPath(String pathName) { boolean result = false; //1.获取文件系统 FileSystem fileSystem = getHadoopFileSystem(); //2.调用文件系统的mkdirs创建目录 Path path = new Path(pathName); try { result = fileSystem.mkdirs(path); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } finally { //3.将文件系统关闭 close(fileSystem); } return result; } /** * 创建文件 * @param pathName * @return */ public static boolean createFile(String pathName, String content) { boolean result = false; //1.获取文件系统 FileSystem fileSystem = getHadoopFileSystem(); //2.调用文件系统create方法创建文件 try { //2.1创建文件 FSDataOutputStream out = fileSystem.create(new Path(pathName)); //2.2写入数据 out.writeUTF(content); result = true; } catch (IllegalArgumentException | IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } finally { //3.关闭文件系统 close(fileSystem); } return result; } /** * 上传文件 * @param srcPathName * @param dstPathName */ public static void putFile2HDFS(String srcPathName, String dstPathName) { //1.获取文件系统 FileSystem fileSystem = getHadoopFileSystem(); //2.调用文件系统中的copyFromLocalFile上传文件 try { fileSystem.copyFromLocalFile(new Path(srcPathName), new Path(dstPathName)); } catch (IllegalArgumentException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } finally { //3.关闭文件系统 close(fileSystem); } } /** * 上传文件(通过输入输出流) * @param srcPathName * @param dstPathName */ public static void putFile2HDFS2(String srcPathName, String dstPathName) { //1.获取文件系统 FileSystem fileSystem = getHadoopFileSystem(); //2.创建输出文件 try { //通过上传文件,生成输出流 FSDataOutputStream out = fileSystem.create(new Path(dstPathName)); //通过本地文件生成输入流 FileInputStream in = new FileInputStream(srcPathName); //通过IOUtils的copyBytes方法传递数据流 IOUtils.copyBytes(in, out, 4096, true); } catch (IllegalArgumentException | IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } finally { close(fileSystem); } } /** * 查看指定目录或文件的元数据信息 * @param pathName */ public static void list(String pathName) { //1.获取文件系统 FileSystem fileSystem = getHadoopFileSystem(); //2.调用文件系统的listStatus方法获取元数据列表信息 try { FileStatus[] list = fileSystem.listStatus(new Path(pathName)); for (FileStatus fileStatus : list) { boolean isDir = fileStatus.isDirectory(); String path = fileStatus.getPath().toString(); short replication = fileStatus.getReplication(); System.out.println(isDir + "::" + path + "::" + replication); } } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } finally { //3.关闭文件系统 close(fileSystem); } } /** * 下载文件 * @param srcPathName * @param dstPathName */ public static void getFileFromHDFS(String srcPathName, String dstPathName) { //1.获取文件系统 FileSystem fileSystem = getHadoopFileSystem(); //2.调用文件系统的copyToLocalFile方法下载文件 try { //由于本地是windows系统,没有安装hadoop环境,所以使用第四个参数指定使用本地文件系统 fileSystem.copyToLocalFile(false, new Path(srcPathName), new Path(dstPathName), true); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } finally { //3.关闭文件系统 close(fileSystem); } } /** * 下载文件 * @param srcPathName * @param dstPathName */ public static void getFileFromHDFS2(String srcPathName, String dstPathName) { //1.获取文件系统 FileSystem fileSystem = getHadoopFileSystem(); //2.通过输入输出流进行下载 try { //2.1hdfs文件通过输入流读取到内存 FSDataInputStream in = fileSystem.open(new Path(srcPathName)); //2.2内存中的数据通过输出流输出到本地文件中 // FileOutputStream out = new FileOutputStream(dstPathName); //3.3IOUtils的copyBytes方法复制数据流 // IOUtils.copyBytes(in, out, 4096, true); IOUtils.copyBytes(in, System.out, 4096, true); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } //3.关闭文件系统 close(fileSystem); } /** * 删除文件 * @param pathName */ public static void delete(String pathName) { //1.获取文件系统 FileSystem fileSystem = getHadoopFileSystem(); //2.调用文件系统的delete方法删除文件 try { fileSystem.delete(new Path(pathName), true); } catch (IllegalArgumentException | IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } finally { //3.关闭文件系统 close(fileSystem); } } /** * 关闭文件系统 * @param fileSystem */ public static void close(FileSystem fileSystem) { try { fileSystem.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } }; }
a.Hadoop默认支持权限控制,可将其关闭
hdfs-site.xml文件:dfs.permissions.enabled设置成false
注:需配置到服务器hdfs-site.xml中,服务器重启
b.获取文件元数据信息
副本策略:dfs.replication配置项在客户端进行指定
c.下载文件时候调用copyToLocalFile的问题
由于本地是windows系统,没有安装hadoop环境,所以使用第四个参数指定使用本地文件系统
fileSystem.copyToLocalFile(false, new Path(srcPathName), new Path(dstPathName), true);
四:YARN(资源调度和任何管理)
1.四大组件
ResourceManager(RM)、NodeManager(NM)、ApplicationMaster(AM)、Container
2.执行流程
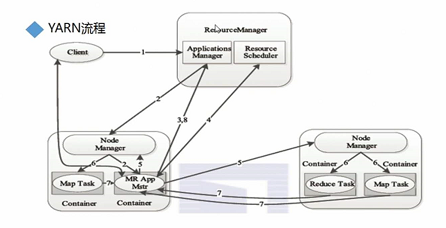
<1>client连接RM提交作业,RM给client一个JobId(注:ApplicationsManager和ResourceScheduler)
<2>RM中的ApplicationsManager连接一个NM,让NM创建一个AM处理客户端作业请求
<3>AM连接RM中ApplicationsManager申请NodeManager
<4>AM去ResourceScheduler给client的作业申请资源(cpu、内存、磁盘、网络)
<5>AM连接NM,发送client job作业程序和申请的资源cpu、内存、磁盘、网络)
<6>NM启动Container进程运行job的不同任务
<7>Container进程运行状态实时反馈给AM
<8>AM反馈任务状态信息给RM中的ApplicationsManager
<9>client端可以连接RM或AM查询job的执行情况
注:NM启动后去RM上进行注册,会不断发送心跳,说明处于存活状态
3.具体聊聊
1)资源调度
a.调度器(Resource Scheduler)
<1>FIFO Scheduler
按照作业提交顺序放到先进先出的队列中执行
<2>Capacity Scheduler(雅虎)
apache版本默认使用的
将不同作业放到不同队列中,每个队列按照FIFO或DRF进行分配资源
<3>Fair Scheduler(Facebook)
CDH版本默认使用的
动态划分或指定多个队列,每个队列按照Fair(默认)或FIFO或DRF(主资源公平算法)进行分配资源
注:DRF算法(主资源公平算法)
作业1:cpu资源是主资源
作业2:内存资源是主资源
b.Capacity Scheduler配置
<1>配置capacity-scheduler.xml:
yarn.scheduler.capacity.root.queues:prod,dev
yarn.scheduler.capacity.root.dev.queues:eng,science
yarn.scheduler.capacity.root.prod.capacity:40
yarn.scheduler.capacity.root.dev.capacity:60
yarn.scheduler.capacity.root.dev.maximun-capacity:75
yarn.scheduler.capacity.root.dev.eng.capacity:50
yarn.scheduler.capacity.root.dev.science.capacity:50
<2>配置yarn-site.xml:
yarn.resourcemanager.scheduler.class:
org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
c.运行Capacity Scheduler
<1>指定作业运行在哪个队列上mapreduce.job.queuename
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.9.0.jar wordcount -Dmapreduce.job.queuename=eng file:/opt/module/hadoop-2.6.0/NOTICE.txt file:/opt/output
<2>查看调度器
http://hadoop-senior01.test.com:8088中的scheduler
d.Fair Scheduler配置
<1>去掉yarn-site.xml中的yarn.resourcemanager.scheduler.class,保持默认
<2>直接运行作业的话,就创建一个以当前登录用户名为队列名的队列运行;
如果运行作业时指定了队列名,就在指定的队列中运行
<3>fair-scheduler.xml配置
<allocations>
<defaultQueueSchedulingPolicy>fair</defaultQueueSchedulingPolicy>
<queue name="prod">
<weight>40</weight>
<schedulingPolicy>fifo</schedulingPolicy>
</queue>
<queue name="prod">
<weight>60</weight>
<queue name="eng"/>
<queue name="science"/>
</queue>
<queuePlacementPolicy>
<rule name="specified" create="false"/>
<rule name="primaryGroup" create="false"/>
<rule name="default" queue="dev.eng"/>
</queuePlacementPolicy>
</allocations>
e.运行Fair Scheduler
<1>指定作业运行在哪个队列上mapreduce.job.queuename或不指定
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.9.0.jar wordcount -Dmapreduce.job.queuename=eng file:/opt/module/hadoop-2.6.0/NOTICE.txt file:/opt/output
<2>查看调度器
http://hadoop-senior01.test.com:8088中的scheduler
2)资源隔离(NodeManager)
a.含义
NodeManager运行多个container进程,进程需要的资源需要进行隔离,不让彼此产生干扰
b.隔离方式
内存隔离、CPU隔离
c.Yarn Container两种执行方式
DefaultContainerExecutor(内存隔离)和LinuxContainerExecutor(内存隔离、CPU隔离(cgroup))
注:两种方式的内存隔离都是采用线程监控方式
五:生态系统

1)Hadoop:分布式存储、分布式计算、资源调度与任务管理
hdfs、mapreduce、yarn、common
2)Lucene:索引检索工具包;Solr:索引服务器
3)Nutch:开源的搜索引擎
4)HBase/Cassandra:基于谷歌的BigTable开源的列式存储的非关系型数据库
5)Hive:基于SQL的分布式计算引擎,同时是一个数据仓库
Pig:基于Pig Latin脚本的计算引擎
6)Thrift/Avro:RPC框架,用于网络通信
7)BigTop:项目测试、打包、部署
8)Oozie/Azakban:大数据的工作流框架
9)Chukwa/Scribe/Flume:数据收集框架
10)Whirr:部署为云服务的类库
11)sqoop:数据迁移工具
12)Zookeeper:分布式协调服务框架
13)HAMA:图计算框架
14)Mahout:机器学习框架
六:安装配置
1.三个版本:单机、伪分布式、分布式
2.三个分支:apache版本(Apache基金会),cdh版本(cloudera公司),hdp版本(HortOnWorks公司)
资源下载路径:https://archive.cloudera.com/cdh5/cdh/5/;https://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.9.0.tar.gz
具体安装详情请看:hadoop的安装配置
3.单机(仅仅适用于单机运行分布式计算作业)
直接执行mapreduce-examples.jar案例
1)通过rz命令上传自己本地的hadoop安装包到linux服务上,我创建了一个/opt/software文件夹专门放安装包
2)解压:tar zxf hadoop-2.6.0-cdh5.9.0.tar.gz -C /opt/module(解压文件都指定文件夹中去module)
3)改名字:mv hadoop-2.6.0-cdh5.9.0 hadoop-2.6.0
4)测试小demo
创建input文件夹放很多xml文件;执行测试脚本: bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.9.0.jar grep input output 'dfs[a-z.]+'
查看结果:在output文件夹中出现succuss和另一个文件: cat part-r-00000(出现结果dfsadmin表示成功)
这单机版的hadoop没什么可以做的,这里只是他最简单的一个小demo
4.伪分布式
I.HDFS
<1>配置core-site.xml
fs.defaultFS
et/hadoop/core-site.xml(配置这目的:通过指定端口来访问HDFS的主节点NameNode) <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
<2>配置hdfs-site.xml
dfs.replication
etc/hadoop/hdfs-site.xml(hdfs配置指定块复制数,这里由于是伪分布式,所以指定多个也没用,块坏了还是跳不到其他地方的) <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
<3>格式化NameNode
bin/hdfs namenode -format
作用:清空NameNode目录下的所有数据,生成目录结构,初始化一些信息到文件中
(我们初始化的目录默认在:/tmp/hadoop-root/dfs/name/current/;副本默认在)
<4>启动HDFS各个进程
sbin/start-dfs.sh
或
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
sbin/hadoop-daemon.sh start secondarynamenode
如果报JAVA_HOME is not set and could not be found错误,重新指定java路径:vim etc/hadoop/hadoop-env.sh
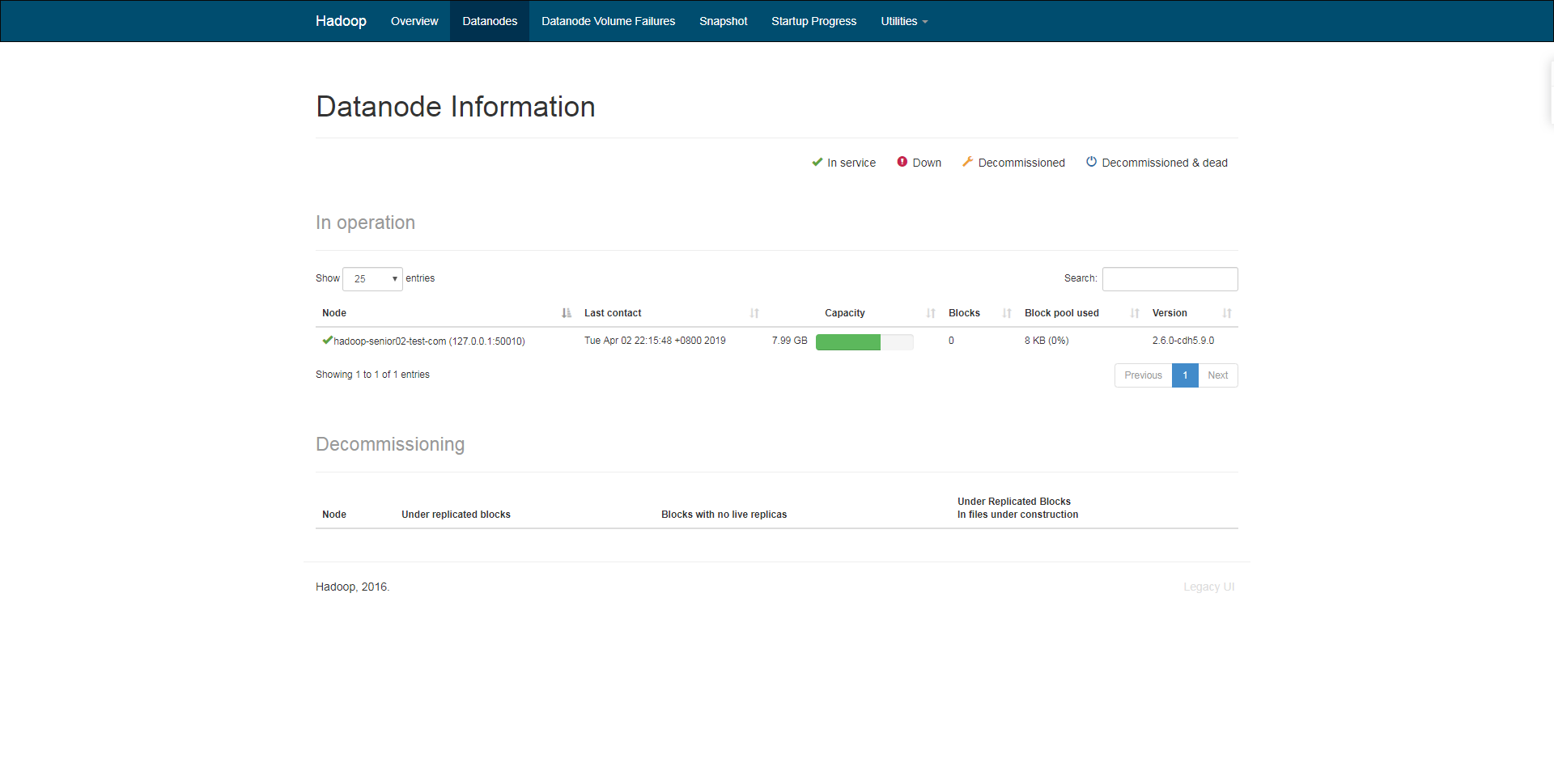
<5>浏览器访问
http://<主机名>:50070
注:50070是http协议的端口号;9000是RPC tcp协议的端口号,下图说明hdfs服务安装配置好了;关服务:sbin/stop-dfs.sh
II.YARN
<1>配置mapred-site.xml(指定mapreduce的选定方案:yarn而不是默认的mapreduce了)
etc/hadoop/mapred-site.xml
<configuration>
<properity>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</properity>
</configuration>
<2>配置yarn-site.xml(配置yarn要跑什么作业)
etc/hadoop/yarn-site.xml
<configuration>
<properity>
<name>yarn-nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</properity>
</configuration>
<3>启动YARN进程:ResourceManager、NodeManager
sbin/start-yarn.sh
或
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
<4>关闭YARN进程:sbin/stop-yarn.sh
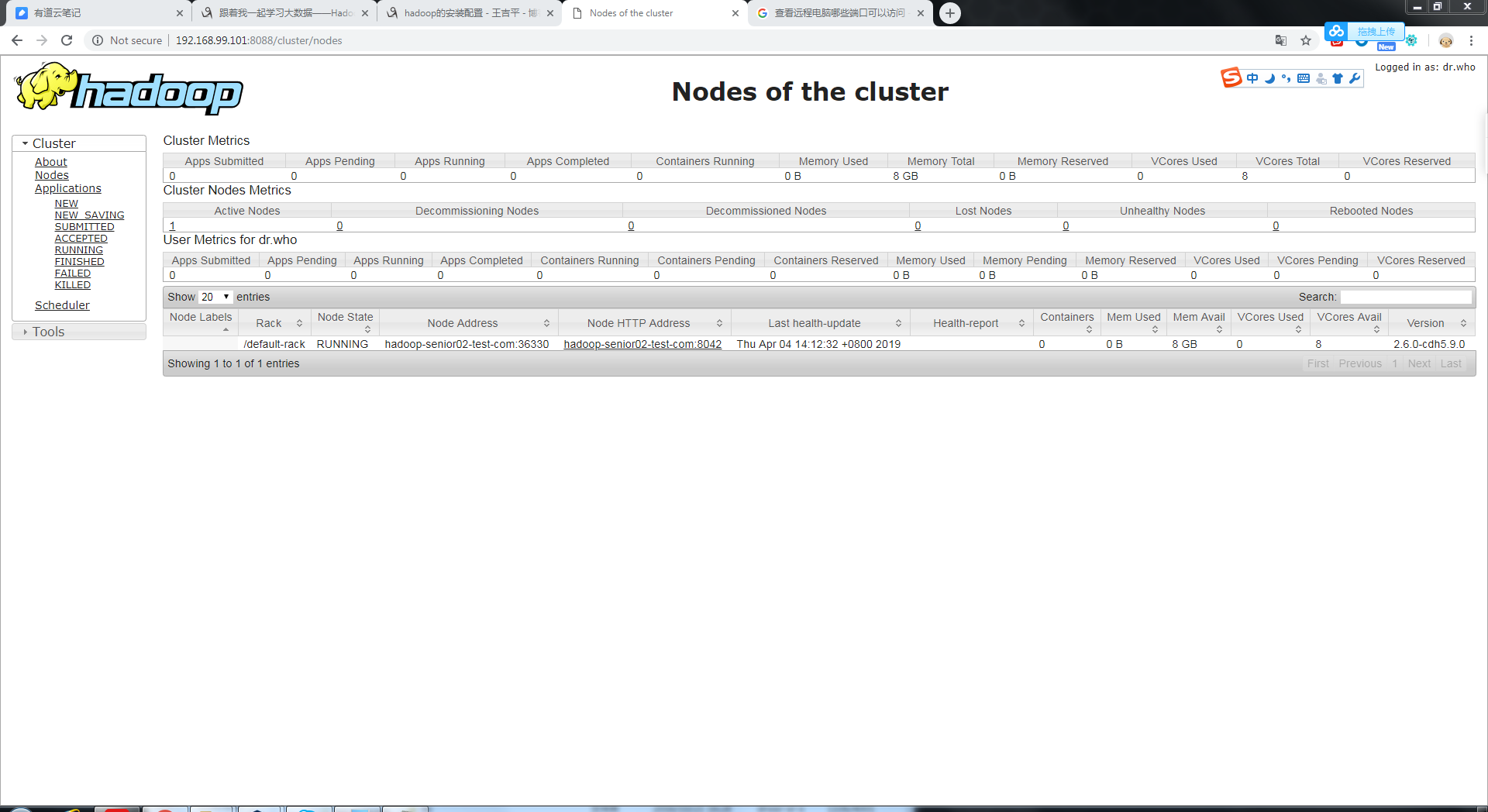
<4>浏览器访问
http://<主机名>:8088
注:8032是RPC tcp协议的端口号;8088是http协议的端口号
5.分布式环境搭建
1)先将之前伪分布式的配置复制到另一个文件夹
cp -r hadoop hadoop-pseudo(这里hadoop-pseudo我们就作为之前分布式的配置吧,我们接下来的操作时修改hadoop文件中的配置项为分布式)
2)配置namenode访问地址,配置secondarynamenode访问地址,配置resourcemanager访问地址,配置从节点的主机名
配置core-sit.xml(这里还是之前的不用变,指定namenode位置) <property>
<name>fs:default.name</name>
<value>hdfs://master:9000</value>
</property>
配置hdfs-sit.xml(这里配置的是secondary namenode 为namenode减轻压力,这里需要配置到第三台机子上hadoop-senior3-test-com)
<property>
<name>dfs:namenode.secondary.http-address</name>
<value>hadoop-senior03-test-com:50090</value>
</property>
配置yarn-site.xml(配置resourcemanager访问地址)
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce-shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-senior02-test-com</value>
</property>
配置$HADOOP_HOME/etc/hadoop/slaves文件 hadoop-senior1.test.com hadoop-senior2.test.com hadoop-senior3.test.com
3)这一台机器配置好了,需要将这些hadoop配置项复制到其他机器上
scp -r * root@hadoop-senior02-test-com:/opt/module/hadoop-2.6.0/etc/hadoop
4)配置三台电脑的免密码登录
5)配置聚合日志
a.含义:
I.分布式计算作业放到NodeManager运行,日志信息放在NodeManager本地目录:
yarn.nodemanager.log-dirs:${yarn.log.dir}/userlogs
II.通过配置将本地日志放到HDFS服务器上,即聚合日志的概念
b.配置yarn-site.xml
<!--启用日志聚合功能-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--存放多长时间-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>3600</value>
</property>
6)历史服务器
a.配置项
<!--RPC访问地址-->
mapreduce.jobhistory.address
<!--HTTP访问地址-->
mapreduce.jobhistory.webapp.address
b.启动/访问/停止
sbin/mr-jobhistory-daemon.sh start historyserver
yarn主界面跳转:http://<主机名>:19888
sbin/mr-jobhistory-daemon.sh stop historyserver
三:Hadoop高级部分
3.1 MapReduce案例
1)去重排序
需求:将原始数据中出现次数不超过一行的每行数据在输出文件中只出现一次,并按字典排序
原始数据:C:\java\eclipse\workspace\hadoop课程源码\src\demo\去重排序
原始数据:file_1 2012-3-1 a 2012-3-2 b 2012-3-3 c 2012-3-4 d 2012-3-5 a 2012-3-6 b 2012-3-7 c 2012-3-3 c 原始数据:file_2 2012-3-1 a 2012-3-2 b 2012-3-3 c 2012-3-4 d 2012-3-5 a 2012-3-6 b 2012-3-7 c 2012-3-3 c 原始数据:file_3 2012-3-1 a 2012-3-2 b 2012-3-3 c 2012-3-4 d 2012-3-5 a 2012-3-6 b 2012-3-7 c 2012-3-3 c
package com.itjmd.mapreduce; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 去重排序 * @author Administrator * */ public class DistictAndSort { /** * mapper处理类 * @author Administrator * */ public static class MyMapper extends Mapper<LongWritable, Text, Text, Text> { /** * map处理逻辑 * 将每行数据读取进来,转换成输出格式<行数据,""> */ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException { //直接输出行数据 context.write(value, new Text("")); } } /** * reducer处理类 * 将行数据进行去重 * @author Administrator * */ public static class MyReducer extends Reducer<Text, Text, Text, Text> { /** * reduce处理逻辑 * 将输入数据去重,并转换成输出格式<行数据,""> */ @Override protected void reduce(Text key, Iterable<Text> value, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException { //直接输出 context.write(key, new Text("")); } } //驱动方法 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //0.创建一个Job Configuration conf = new Configuration(); //连接hadoop环境 // conf.set("fs.defaultFS", "hdfs://hadoop-senior01.test.com:8020"); Job job = Job.getInstance(conf, "DistictAndSort"); //通过类名打成jar包 job.setJarByClass(DistictAndSort.class); //1.输入文件 for (int i = 0; i < args.length-1; i++) { FileInputFormat.addInputPath(job, new Path(args[i])); } //2.编写mapper处理逻辑 job.setMapperClass(MyMapper.class); // job.setMapOutputKeyClass(Text.class); // job.setMapOutputValueClass(Text.class); //3.shuffle流程(暂时不用处理) //4.编写reducer处理逻辑 job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); //5.输出文件 FileOutputFormat.setOutputPath(job, new Path(args[args.length-1])); //6.运行Job boolean result = job.waitForCompletion(true); System.out.println(result ? 1 : 0); } }
2)最高气温
需求:求取每年气温最高的是哪一天,气温是多少
原始数据:C:\java\eclipse\workspace\hadoop课程源码\src\demo\气温数据
分析:
a.Map拆分原始数据每一行,将年份抽取出来。输出格式<年份,日期:温度>
b.Reduce拆分日期:温度数据,将温度逐个分析,找到每年最大气温及日期
c.Reduce输出数据。输出格式:<日期,温度>
1990-01-01 -5 1990-06-18 35 1990-03-20 8 1989-05-04 23 1989-11-11 -3 1989-07-05 38 1989-07-05 38 1990-07-30 37
package com.itjmd.mapreduce; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.DoubleWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 每年最高气温是哪天,气温是多少 * @author Administrator * */ public class MaxTemp { /** * mapper处理类 * @author Administrator * */ public static class MyMapper extends Mapper<LongWritable, Text, Text, Text> { /** * map处理逻辑 * 将输入value进行拆分,拆分出年份,然后输出<年份,日期:温度> */ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException { //将输入value进行拆分 String line = value.toString(); String[] lineArr = line.split("\t"); //生成年份 String year = lineArr[0].substring(0, 4); //输出格式:<year,day:temp> context.write(new Text(year), new Text(lineArr[0] + ":" + lineArr[1])); } } /** * reducer处理类 * @author Administrator * */ public static class MyReducer extends Reducer<Text, Text, Text, DoubleWritable> { /** * reduce处理逻辑 * 求取每年气温最大值 */ @Override protected void reduce(Text key, Iterable<Text> value, Reducer<Text, Text, Text, DoubleWritable>.Context context) throws IOException, InterruptedException { double maxTemp = Long.MIN_VALUE; String maxDay = null; for (Text tempVal : value) { //生成数组[日期,温度] String tempValStr = tempVal.toString(); String[] tempValArr = tempValStr.split(":"); Double temp = Double.parseDouble(tempValArr[1]); //比较,获取最大值 maxTemp = temp > maxTemp ? temp : maxTemp; //获取天数 maxDay = tempValArr[0]; } //输出格式<day,temp> context.write(new Text(maxDay), new DoubleWritable(maxTemp)); } } //驱动方法 public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException { //0.创建一个Job Configuration conf = new Configuration(); //连接hadoop环境 // conf.set("fs.defaultFS", "hdfs://hadoop-senior01.test.com:8020"); Job job = Job.getInstance(conf, "max-temp"); //通过类名打成jar包 job.setJarByClass(MaxTemp.class); //1.输入文件 FileInputFormat.addInputPath(job, new Path(args[0])); //2.编写mapper处理逻辑 job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); //3.shuffle流程(暂时不用处理) //4.编写reducer处理逻辑 job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(DoubleWritable.class); //5.输出文件 FileOutputFormat.setOutputPath(job, new Path(args[1])); //6.运行Job boolean result = job.waitForCompletion(true); System.out.println(result ? 1 : 0); } }
3)单表关联
需求:从给出的父子关系数据表中找到祖父祖孙的关系
原始数据:C:\java\eclipse\workspace\hadoop课程源码\src\demo\单表关联\单表关联.txt
分析:
a.map将原数据拆分,输出左表数据。数据格式<parent,child>
b.Map同时输出右表数据,输出格式<child,parent>
c.Reduce连接左表的parent列和右表的child列
child parent
Tom Luck
Tom Jack
Jone Luck
Jone Jack
Lucy Marry
Lucy Ben
Jack Alice
Jack Jesse
Terry Alice
Terry Jesses
Philip Terry
Philip Alma
Mark Terry
Mark Alma
package com.itjmd.mapreduce; import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 单表关联 * @author Administrator * */ public class SingleJoin { //临时配置HADOOP_HOME环境变量 static { System.setProperty("hadoop.home.dir", "C:\\java\\hadoop-2.6.0-cdh5.9.0"); } /** * Mapper处理类 * @author Administrator * */ public static class MyMapper extends Mapper<LongWritable, Text, Text, Text> { /** * map处理逻辑 * 将输入数据转成两个表记录:1.<子,父> 2.<父,子> */ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException { //拆分每行数据 String line = value.toString(); String[] lineArr = line.split("\\s+"); //过滤文件头 if (!"child".equals(lineArr[0])) { //1:向上,父母辈; 2:向下,孩子辈 //输出对应的<子,父> context.write(new Text(lineArr[0]), new Text("1:" + lineArr[1])); //输出对应的<父,子> context.write(new Text(lineArr[1]), new Text("2:" + lineArr[0])); } } } /** * Reducer处理类 * @author Administrator * */ public static class MyReducer extends Reducer<Text, Text, Text, Text> { /** * Reduce处理逻辑 * 将输入集合数据拆分成孙子辈列表和祖父辈列表,然后将两个列表进行合并,生成<孙子辈,祖父辈>关系 */ @Override protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException { //孙子辈列表 List<String> grandChildList = new ArrayList<String>(); //祖父辈列表 List<String> grandParentList = new ArrayList<String>(); for (Text tempVal : values) { String tempValStr = tempVal.toString(); String[] tempValArr = tempValStr.split(":"); if ("2".equals(tempValArr[0])) { //1.找出孙子辈列表 grandChildList.add(tempValArr[1]); } else if ("1".equals(tempValArr[0])) { //2.找出祖父辈列表 grandParentList.add(tempValArr[1]); } } //3.将两个列表进行关联,获取<孙子辈,祖父辈>关系 for (String grandChild : grandChildList) { for (String grandParent : grandParentList) { //输出<孙子辈,祖父辈> context.write(new Text(grandChild), new Text(grandParent)); } } } } //驱动方法 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //0.创建一个Job Configuration conf = new Configuration(); //连接hadoop环境 // conf.set("fs.defaultFS", "hdfs://hadoop-senior01.test.com:8020"); Job job = Job.getInstance(conf, "single-join"); //通过类名打成jar包 job.setJarByClass(SingleJoin.class); //1.输入文件 FileInputFormat.addInputPath(job, new Path(args[0])); //2.编写mapper处理逻辑 job.setMapperClass(MyMapper.class); //3.shuffle流程(暂时不用处理) //4.编写reducer处理逻辑 job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); //5.输出文件 FileOutputFormat.setOutputPath(job, new Path(args[1])); //6.运行Job boolean result = job.waitForCompletion(true); System.out.println(result ? 1 : 0); } }
4)多表关联
需求:将订单明细表和商品表中的数据关联
原始数据:C:\java\eclipse\workspace\hadoop课程源码\src\demo\多表关联
detail order_id item_id amount 12 sp001 2 12 sp002 4 12 sp003 3 12 sp001 2 13 sp001 2 13 sp002 4 iteminfo item_id item_type sp001 type001 sp002 type002 sp003 type002
package com.itjmd.mapreduce; import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class ReduceJoin { //临时配置HADOOP_HOME环境变量 static { System.setProperty("hadoop.home.dir", "C:\\java\\hadoop-2.6.0-cdh5.9.0"); } /** * mapper处理类 * @author Administrator * */ public static class MyMapper extends Mapper<LongWritable, Text, Text, Text> { /** * map处理逻辑 * 1.判断是哪个表 * 2.针对不同的表输出不同的数据 */ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException { //1.判断是哪个表文件 String fileName = ((FileSplit)context.getInputSplit()).getPath().getName(); //2.切分每行数据 String line = value.toString(); if (line.contains("item_id")) return; String[] lineArr = line.split("\t"); //输出格式的1:订单明细表;2:商品表 if ("detail.txt".equals(fileName)) { //订单明细表,输出格式<item_id,"1:order_id:amount"> context.write(new Text(lineArr[1]), new Text("1\t" + lineArr[0] + "\t" + lineArr[2])); } else if ("iteminfo.txt".equals(fileName)) { //商品表,输出格式<item_id,"2:item_type"> context.write(new Text(lineArr[0]), new Text("2\t" + lineArr[1])); } } } /** * reducer处理类 * @author Administrator * */ public static class MyReducer extends Reducer<Text, Text, Text, Text> { /** * reduce处理逻辑 * 1.将相同商品id的订单明细信息和商品信息进行拆分,拆分后存到响应的订单明细列表和商品列表中 * 2.将订单明细列表和商品列表进行嵌套遍历 */ @Override protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException { //0.定义订单明细列表和商品信息列表 List<String> orderDetailList = new ArrayList<String>(); List<String> itemInfoList = new ArrayList<String>(); //1.将相同商品id的订单明细信息和商品信息进行拆分,拆分后存到响应的订单明细列表和商品列表中 for (Text tempVal : values) { String tempValStr = tempVal.toString(); String[] tempValArr = tempValStr.split("\t"); if ("1".equals(tempValArr[0])) { //订单明细表 orderDetailList.add(tempValStr.substring(2)); } else { //商品表 itemInfoList.add(tempValArr[1]); } } //2.将订单明细列表和商品列表进行嵌套遍历 for (String itemInfo : itemInfoList) { for (String orderDetail : orderDetailList) { context.write(key, new Text(itemInfo + "\t" + orderDetail)); } } } } //驱动方法 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //0.创建一个Job Configuration conf = new Configuration(); //连接hadoop环境 // conf.set("fs.defaultFS", "hdfs://hadoop-senior01.test.com:8020"); Job job = Job.getInstance(conf, "reduce-join"); //通过类名打成jar包 job.setJarByClass(ReduceJoin.class); //1.输入文件 for (int i = 0; i < args.length-1; i++) { FileInputFormat.addInputPath(job, new Path(args[i])); } //2.编写mapper处理逻辑 job.setMapperClass(MyMapper.class); //3.shuffle流程(暂时不用处理) //4.编写reducer处理逻辑 job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); //5.输出文件 FileOutputFormat.setOutputPath(job, new Path(args[args.length-1])); //6.运行Job boolean result = job.waitForCompletion(true); System.out.println(result ? 1 : 0); } }
注意:reduceJoin会产生数据倾斜的问题
商品类(数据分布均匀)与订单明细表(热门商品id会有很多条)
方案:订单明细表中map输出的key添加10000内随机数后缀,将生成的新的key分发到不同的reduce task上商品表中的map输出需要扩容10000条,输出到各个reduce task上
reduce 将两个表的map数据进行合并,将后缀删除
5)mapJoin原理与例子
原理:
3.2 HDFS HA架构部署
3.3 HDFS Federation 架构部署
3.4 YARN HA 架构部署
3.5 Hadoop性能调优

 浙公网安备 33010602011771号
浙公网安备 33010602011771号