Teradata - 提取或替换字符串中一部分文本
1、提取或替换的函数
| 类型 | 函数 | 功能 | 示例 |
| 提取 | SUBSTR |
提取字符串的一部分 |
#从位置5开始,提取3个字符 SUBSTR("SQL Tutorial", 5, 3) #输出test_t_e SUBSTR("test_t_e_t",1,instr('test_t_e_t','_',1,2)+2)
|
| 截取 | SUBSTRING |
SUBSTRING(s,n,len) |
|
| 移除 |
TRIM |
修剪字符串中的空格或移除掉一个字串中的字头或字尾
|
#去掉左边指定的字符串
|
| 分割 |
STRTOK |
STRTOK(instring,delimiter,tokennum) (1)instring:字符串或字符串表达式。 (2)delimiter:分隔符列表,字符串每个字符都会做为分隔符,如果不指定则默认使用空格做分隔符。 (3)tokennum:返回分隔的第几部分,默认第一部分。 |
|
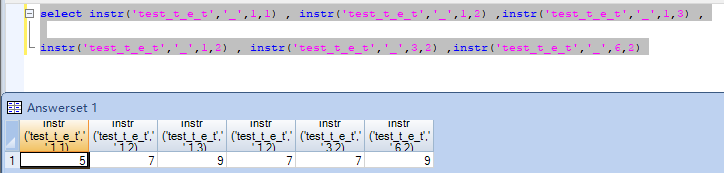
| 定位 | INSTR |
instr('test_t_e_t','_',1,2)
|
 |
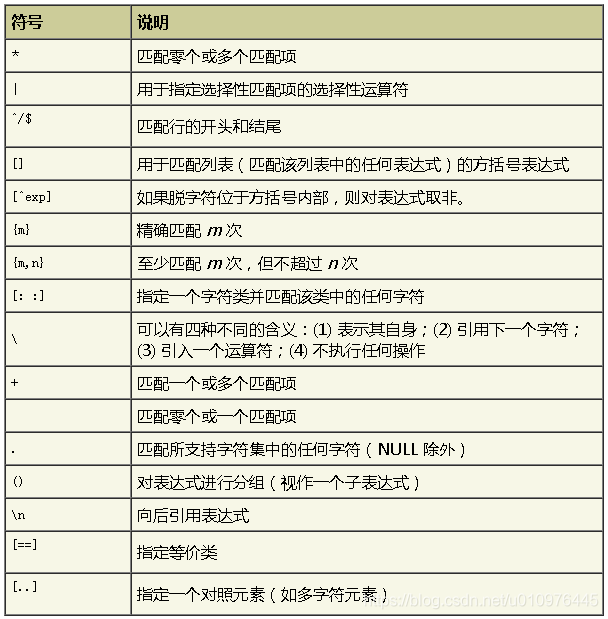
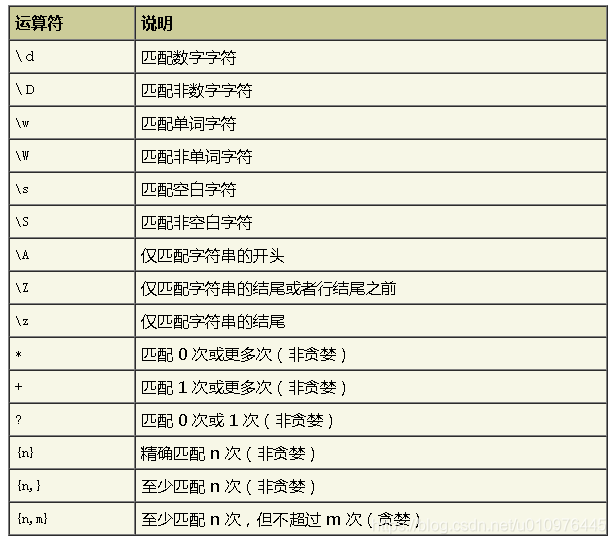
| 正则表达式函数 | regexp_similar |
查看字符串包含某子串的位置,包含则返回首个匹配位置,不包含则返回0 |
|
| 正则表达式函数 | REGEXP_LIKE |
类似于 LIKE 运算符,但执行正则表达式匹配而不是简单的模式匹配 |
|
| 正则表达式函数 | regexp_instr | 在给定字符串中搜索某个正则表达式模式,并返回匹配项的位置 | |
| 正则表达式函数 | regexp_substr | 搜索某个正则表达式模式并使用替换字符串替换它,返回第一个匹配的子串 |
#提取中文字符 sel regexp_substr('mint choc中文11国1','\d+') |
| 正则表达式函数 | regexp_replace | 搜索某个正则表达式模式并使用替换字符串替换它,替换所有匹配子串 | |
| 替换 |
oreplace |
#将字段中的aaa替换为bbb
SELECT DISTINCT TA, oreplace(TA,'aaa','bbb') TA1 FROM table1 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号