01:open-falcon入门篇
open-falcon其他篇
目录:
1.1 openfalcon介绍 返回顶部
openfalcon官网: https://book.open-falcon.org/zh/
1、openfalcon特点
1. 数据采集免配置: 无需预定义agent自动发现、支持plugin、支持主动push
2. 容量水平扩展: 生产环境每秒20多万此数据收集、告警、存储、绘图
3. 告警策略易于管理: 支持策略模板、模板继承和覆盖、报警接收人为用户组
4. 报警事件自动化处理: 触发阀值之后支持callback,便于嵌入自动化逻辑
5. 人性化告警设置: 支持最大告警次数、告警级别、告警恢复通知、告警暂停、不同时段不同阀值、支持维护周期、支持报警合并
6. 历史数据高效查询: 秒级返回上百个指标一年的历史数据
7. 架构设计高可用: 整个系统同核心单点、易运维、易部署
2、openfalcon与zabbix比优点
1. 模板支持继承的同时支持覆盖策略项
2. 数据采集免配置,节省人力成本
3. 较为强大的数据模型
4. tag化描述告警策略each(metric=qps project=falcon module=jedge)>100
5. 水平扩展,多IDC支持
1.2 open-falcon架构 返回顶部
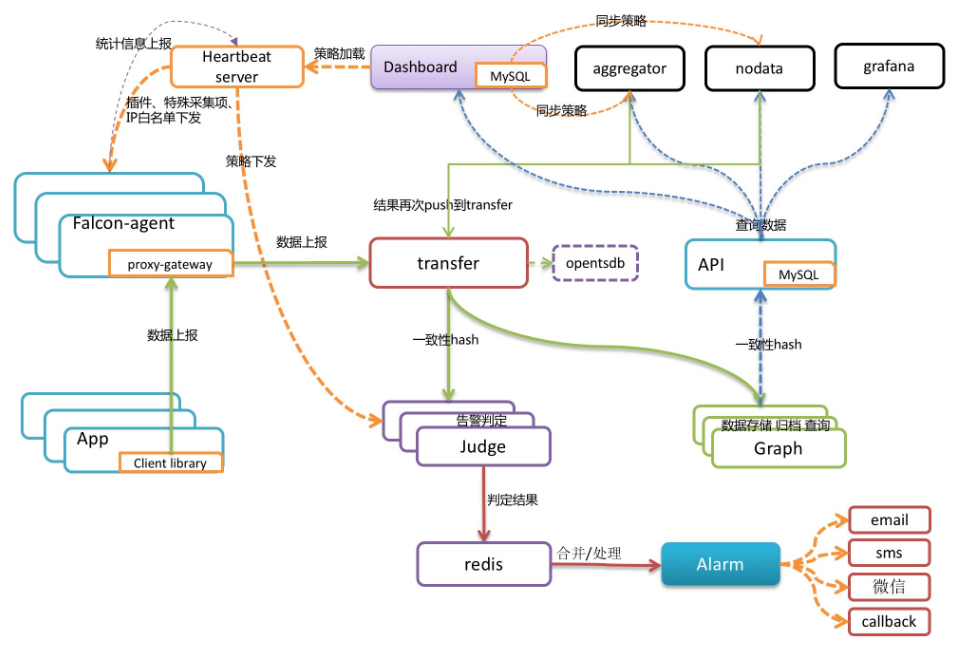
part01:数据采集&上报
1、agent(数据采集组件):golang项目
1. 需要监控的服务器都要安装falcon-agent,falcon-agent是一个golang开发的daemon程序,用于自发现的采集单机的各种数据和指标
2. agent提供了一个http接口/v1/push用于接收用户手工push的一些数据,然后通过长连接迅速转发给Transfer。
3. 部署好agent后,能自动获取到系统的基础监控指标,并上报给transfer,agent与transfer建立了TCP长连接,每隔60秒发送一次数据到transfer。
2、 transfer(数据上报)
1. transfer进程负责分发从agent上送的监控指标数据,并根据哈希分片。
2. 将数据分发给judge进程和graph进程,供告警判定和绘图。
部署说明:
部署完成transfer组件后,请修改agent的配置,使其指向正确的transfer地址。
在安装完graph和judge后,请修改transfer的相应配置、使其能够正确寻址到这两个组件。
part02: 告警
3、judge(告警判断)
1.Judge从Heartbeat server获取所有的报警策略,并判断transfer推送的指标数据是否触发告警。
2. 若触发了告警,judge将会产生告警事件,这些告警事件会写入Redis(使用Redis消息队列)。
3. redis中告警事件,供处理告警事件的Alarm进程转发告警消息,或是Email,或是手机短信等。
部署说明:
Judge监听了一个http端口,提供了一个http接口:/count,访问之,可以得悉当前Judge实例处理了多少数据量。
推荐一个Judge实例处理50万~100万数据,用个5G~10G内存的服务器。
4、Alarm(告警)
https://book.open-falcon.org/zh_0_2/distributed_install/alarm.html
1. Alarm进程监听Redis中的消息队列,并将judge产生的告警事件转发给微信、短信和邮件三种REST接口,REST接口才是具体的发送动作。
2. 另外,关于告警,每条告警策略都会定义不同的优先级,Redis中的消息队列也按优先级划分。
3. Alarm不仅消费告警事件,优先级比较低的报警,其合并逻辑都是在alarm中做,所以目前Alarm进程只能部署一个实例。
4. 已经发送出去的告警事件,Alarm将会负责写入MySQL。
说明:
1)我们在配置报警策略的时候配置了报警级别,比如P0/P1/P2等等,每个及别的报警都会对应不同的redis队列
2)alarm去读取这个数据的时候我们希望先读取P0的数据,再读取P1的数据,最后读取P5的数据,因为我们希望先处理优先级高的。
3)已经发送的告警信息,alarm会写入MySQL中保存,这样用户就可以在dashboard中查阅历史报警。
4)针对同一个策略发出的多条报警,在MySQL存储的时候,会聚类;历史报警保存的周期,是可配置的,默认为7天。
注:alarm是个单点。对于未恢复的告警是放到alarm的内存中的,alarm还需要做报警合并,故而alarm只能部署一个实例。后期需要想办法改进。
part03:归档&绘图
5、graph(数据存储&归档)
1. graph进程接收从transfer推送来的指标数据,操作rrd文件存储监控数据。
2. graph也为API进程提供查询接口,处理query组件的查询请求、返回绘图数据。
6、API(提供统一的restAPI操作接口) :go的后端模块
1. API组件,提供统一的绘图数据查询入口 (提供http接口))。
2. API组件接收查询请求,根据一致性哈希算法去相应的graph实例查询不同metric的数据,然后汇总拿到的数据,最后统一返回给用户。
补充说明:
部署完成api组件后,请修改dashboard组件的配置、使其能够正确寻址到api组件。
请确保api组件的graph列表 与 transfer的配置 一致。
8、dashboard(趋势图web界面):python的web项目
1. dashboard是面向用户的查询界面,在这里,用户可以看到push到graph中的所有数据,并查看其趋势图。
2. dashboard模块配置 报警策略,并把策略同步给:aggregator、nodata、grafana。
9、Aggregator
1. 集群聚合模块,聚合某集群下的所有机器的某个指标的值,提供一种集群视角的监控体验。
10、Nodata
1. nodata用于检测监控数据的上报异常。
2. nodata和实时报警judge模块协同工作,过程为: 配置了nodata的采集项超时未上报数据,nodata生成一条默认的模拟数据;
3. 用户配置相应的报警策略,收到mock数据就产生报警。
4. 采集项上报异常检测,作为judge模块的一个必要补充,能够使judge的实时报警功能更加可靠、完善。
11、grafana(生成更详细图形)
part04:报警策略配置
12、web portal(报警策略配置):最新open-falcon中此模块功能合并到Dashboard模块中
1. web portal是python写的django项目,用户可以在这里配置报警策略,存入mysql
2. Portal的数据库中有一个host表,维护了公司所有机器的信息,比如hostname、ip等等。
3. HBS会将agent发送心跳信息给HBS的时候的hostname、ip等信息告诉HBS,HBS负责更新host表。
13、hbs:Heartbeat server(心跳服务)
1. 功能1: agent发送心跳信息给HBS的时,会把hostname、ip、agent version、plugin version等信息告诉HBS,HBS负责更新web portal 的host表。
2. 功能2: hbs会从从dashboard模块中获取 报警策略配置 并缓存到本地,所有Judge从hbs中获取报警策略
作者:学无止境
出处:https://www.cnblogs.com/xiaonq
生活不只是眼前的苟且,还有诗和远方。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号