
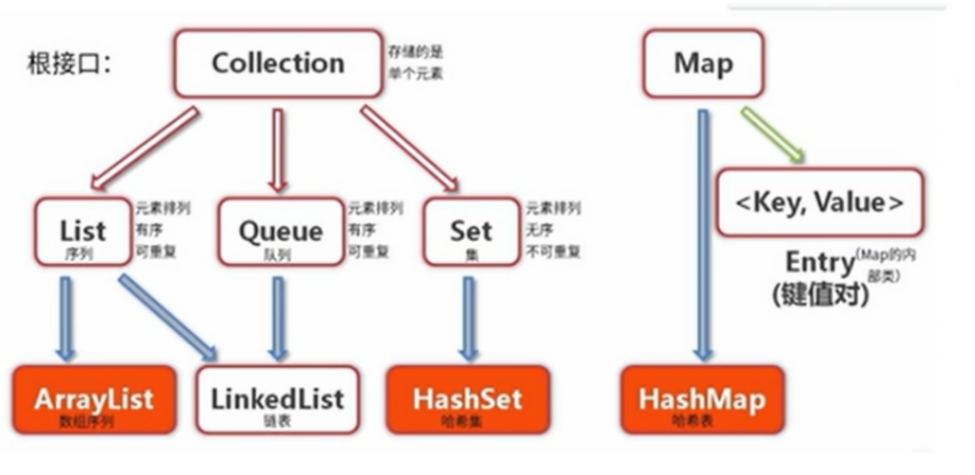
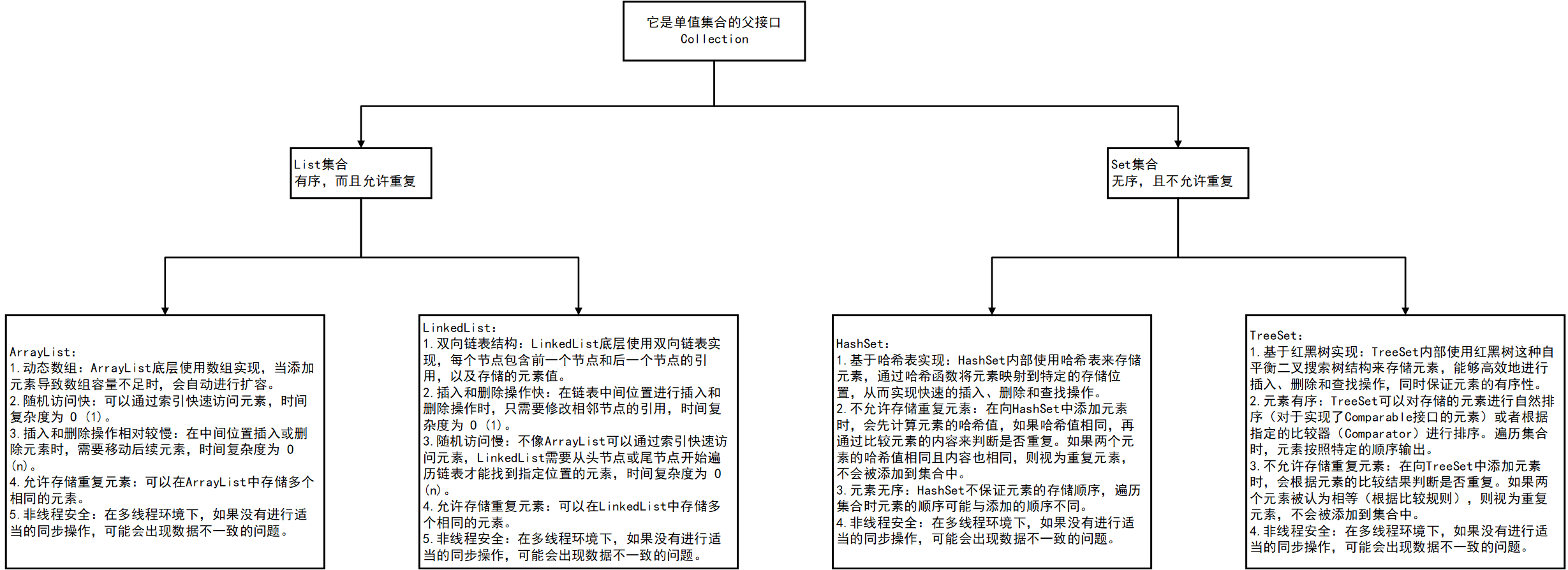
集合
数组的缺点
语法: 动态数组:数据类型[] 数组名=new 数据类型[lenght];
静态数组:数组类型[] 数组名={元素1,元素2,元素3,元素4,元素5......};
缺点: 存放的元素类型固定。而且数组的长度固定的。我们在实际开发中存放元素的个数可能不确定,这时就无法使用数组。
手动编写一个可扩展的数组类
import java.util.Arrays;
public class MyArray {
private Object[] arr;//声明了一个数组
private int size=0;//表示数组的下标索引。
public MyArray() {
arr=new Object[10];//在无参构造中,给一个默认值。。。。
}
public MyArray(int length) {
if(length<0){
throw new RuntimeException("你输入的长度有误!");//长度必须大于0
}
arr = new Object[length];//创建数组
}
public void add(Object o){
if(size>= arr.length){//判断数组是否已放满,这里用==也可
Object[] tmp=new Object[arr.length*2];//将数组扩容
for (int i = 0; i < arr.length; i++) {
tmp[i]=arr[i];//老数组的值赋值给新数组
}
arr=tmp;//数组名改回原来数组名
}//完成扩容
arr[size]=o;//为数组添加数值
size++;//记录数组中数据的个数
}
public Object get(int index){
if(index<0||index>= arr.length){//判断索引是否越界
throw new RuntimeException("数组下标越界...");
}
return arr[index];//返回位置数值
}
public int Size(){
return size;//数组存入数据的个数
}
@Override
public String toString() {
return "MyArray{" +
"arr=" + Arrays.toString(arr) +
'}';
}
}
- 我们上面自己手动编写了一个可扩展的数组类,那么该类就无限的往里面添加元素。
我们都能相同自己编写一个可扩展的数组类,那么java开发人员,它们也一定能想到。 - java开发员根据不同的数据结构,比如 集合 线性结构 队列 映射结构等而开发出来的类称为集合框架。
集合框架
Vector
public class Vector
extends AbstractList
implements List, RandomAccess, Cloneable, Serializable
Vector类实现了可扩展的对象数组。 像数组一样,它包含可以使用整数索引访问的组件。 但是, Vector的大小可以根据需要增长或缩小,以适应在创建Vector之后添加和删除元素
与新集合实现不同, Vector是同步的。 如果不需要线程安全的实现,建议使用ArrayList代替Vector 。
面试: ArrayList和Vector的区别?
Vector是同步。而ArrayList是异步的。
创建Vector类的对象
@Test
public void test01(){
Vector v=new Vector();//创建Vector对象默认10
Vector v2=new Vector(12);//创建Vector对象并指定数组的大小
}
增删改查
增添
import org.junit.Test;
import java.util.Vector;
public class demo02 {
@Test
public void test01(){
Vector v=new Vector();//Vector默认空间为10
//增加元素
v.add(1);
v.add("2");
v.add(1.1);
v.add('4');
v.add(1.1f);
v.add(null);
v.add(true);
v.add("小木不痞");
Vector v1=new Vector(2);
v1.add("hello");
v1.add("hello");
v.addAll(v1);//将v1中的元素一个一个放进集合。
v.add(v1);//将一整个集合v1放进v中
//因为Vector为Object数据类型,所以这里的Vector中基本什么数据类型都可以放,
v.add(1,"小木"); //原本在位置1上添加元素。 1原来的元素都要后移。
System.out.println(v); Vector v=new Vector();//Vector默认空间为10
//增加元素
v.add(1);
v.add("2");
v.add(1.1);
v.add('4');
v.add(1.1f);
v.add(null);
v.add(true);
Vector v1=new Vector(2);
v1.add("hello");
v1.add("hello");
v.add(v1);
//因为Vector为Object数据类型,所以这里的Vector中基本什么数据类型都可以放,
v.add(1,"小木"); //原本在位置1上添加元素。 1原来的元素都要后移。
System.out.println(v);
}
}
修改
//修改
v.set(1,"小木不痞");//对象名.set(索引,改后内容);
System.out.println(v);
删除
//删除
v.remove("小木不痞");//根据内容删除,只删索引靠前的内容
System.out.println(v);
v.remove(1);//根据索引删除,如果索引和内容一样优先默认删除索引位置内容
v.remove((Integer)1);//想要删除数字的话,需要对数字进行转型
System.out.println(v);
v.clear();//清空
System.out.println(v);
查询
Object o=v.get(1);//查询索引为1位置上的内容
System.out.println(o);
int size=v.size();//查询数组长度
System.out.println(size);
boolean xiaomu=v.contains("小木不痞");//判断是否在集合中存在此内容。
System.out.println(xiaomu);
boolean empty=v.isEmpty();//判断集合是否为空
System.out.println(empty);
for (int i = 0; i < v.size(); i++) {
Object o1=v.get(i);
System.out.println(o1);
ArrayList集合
public class ArrayList
extends AbstractList
implements List
可调整大小的数组的实现List接口。 实现所有可选列表操作,并允许所有元素,包括null 。 除了实现List 接口之外,该类还提供了一些方法来操纵内部使用的存储列表的数组的大小。 (这个类是大致相当于Vector,不同之处在于它是不同步的)。
添加元素
import org.junit.Test;
import java.util.ArrayList;
public class demo03 {
@Test
public void testAdd(){
//对象集合容器,改容器只能储存对象。
ArrayList list=new ArrayList();
list.add("hello");
list.add(12);//12(int)---->自动装箱为(Integer),然后放进ArrayList中
list.add(null);
list.add(1,"word");//规定添加位置,规则和Vector一样。
ArrayList list1=new ArrayList();
list1.add("小木");
list1.add("不痞");
list.add(list1);//把一个集合中的元素添加到当前集合中。
System.out.println(list);
}
}
修改
//修改
@Test
public void testUpdate(){
ArrayList list=new ArrayList();
list.add("java1");
list.add("java2");
list.add("java3");
list.add("java4");
list.add("java5");
list.add("java6");
list.add("java7");
list.add("java8");
list.add("java9");
list.add("java10");
list.set(1,"小木");//修改下标为1位置的内容
System.out.println(list);
List list1=list.subList(1,7);//截取集合,不能超范围,超出会出现异常...
System.out.println(list1);
}
删除
//删除
@Test
public void testDelete(){
ArrayList list=new ArrayList();
list.add("java1");
list.add("java2");
list.add("java3");
list.add("java4");
list.add("java5");
list.add("java6");
list.add("java7");
list.add("java8");
list.add("java9");
list.add("java10");
list.remove("java03");//根据内容移除.找不到就不删,也不会报错。。。
list.remove(0);//根据下标移除
System.out.println(list);
ArrayList list1=new ArrayList();
list1.add("java10");
list1.add("java");
list.removeAll(list1);//根据内容移除.找不到就不删,也不会报错,集合中删集合所有此集合都删完,有几个删几个。
System.out.println(list);
}
查询
@Test
public void testSelect(){
ArrayList list=new ArrayList();
list.add("java1");
list.add("java2");
list.add("java3");
list.add("java4");
list.add("java5");
list.add("java6");
list.add("java7");
list.add("java8");
System.out.println(list.get(1));
System.out.println(list.size());
Object[] objects=list.toArray();//将集合转化为数组
System.out.println(list.contains(10));//查询是否在数组中存在
System.out.println(list);
}
遍历
@Test
public void test(){
ArrayList list=new ArrayList();
list.add("java1");
list.add("java2");
list.add("java3");
list.add("java4");
list.add("java5");
list.add("java6");
list.add("java7");
list.add("java8");
System.out.println("下标遍历");
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
System.out.println("增强for循环");
for(Object o:list){
System.out.println(o);
}
}
ArrayList集合底层源码
1.我们先从ArrayList的构造函数看;
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
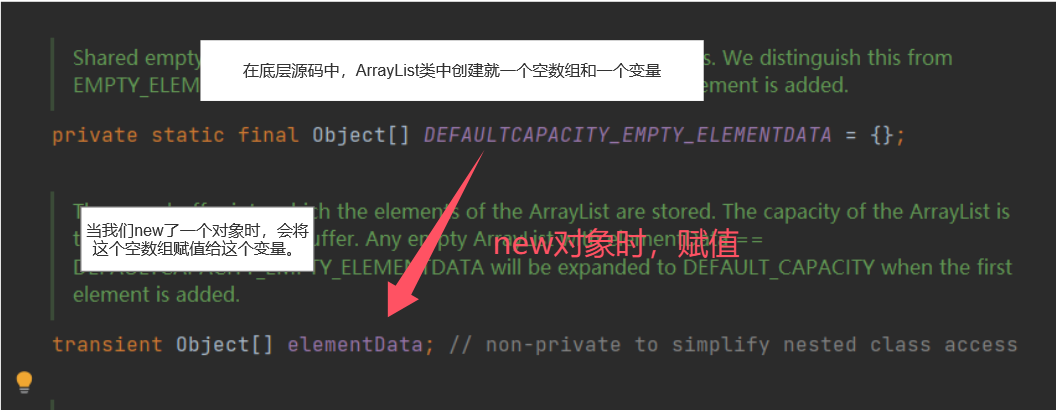
从上面的代码我们分析出来: elementData={}; 创建了一个长度为0的空数组。
2.分析添加的源码
如;arrayList.add("java");
add底层源码如下:
//其中的E指的是:泛型,我们可以先把它理解为Object类型
public boolean add(E e) {
ensureCapacityInternal(size + 1); //判断数组是否已满,并进行扩容
elementData[size++] = e;//将元素赋值给集合的size++位置
return true;
}
// 扩容代码:ensureCapacityInternal();
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// 当最小容量-elementData.length>0,说明存储空间满了,需要扩容了。
if (minCapacity - elementData.length > 0)
grow(minCapacity);//调用扩容方法
}
//grow()核心内容
private void grow(int minCapacity) {
// 老数组的长度
int oldCapacity = elementData.length;
//>>表示位运算符:这里表示*0.5倍,所以新数组的长度为老数组的1.5倍。
int newCapacity = oldCapacity + (oldCapacity >> 1);
//判断新数组长度见最小数组长度是否小于0.
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;//成立将最小数组长度赋给新数组。
if (newCapacity - MAX_ARRAY_SIZE > 0)//MAX_ARRAY_SIZE=Integer.MAX_VALUE - 8
newCapacity = hugeCapacity(minCapacity);//在去调方法
//将老数组内容赋给新数组并扩容1.5倍,最后回来赋值给老数组名。
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // 判断是否数据溢出
throw new OutOfMemoryError();//溢出显示异常
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;//没有溢出现象就返回新数组长度
}
从上面的源码我们分析出ArrayList底层使用的数组结构【特点: 查询效率块。中间删除和添加效率慢】,而且数组在进行扩容时,是原来的1.5倍。并且使用Arrays.copyof方法进行扩容并把原数组的内容赋值过来。
LinkedList
它的底层使用链表结构,特点:便以删除和添加操作。但是它的查询效率慢
@Test
//使用LinkedList
public void test02(){
LinkedList list=new LinkedList();
//添加
list.add("java02");
list.addLast("不痞");//最后位置添加
list.addFirst("java01");//第一个位置添加
list.add(2,"小木");//指定位置添加
System.out.println(list);
list.set(0,"java1");
list.add(2,"java03");
list.add(3,"java04");
list.add(4,"java05");
list.add(5,"java06");
System.out.println("list = " + list);
//查询
System.out.println("list.get(1) = " + list.get(1));//指定位置内容
System.out.println("list.isEmpty() = " + list.isEmpty());//判断集合是否为空。
System.out.println("list.getFirst() = " + list.getFirst());//集合第一个元素内容
System.out.println("list.getLast() = " + list.getLast());//集合最后一个元素内容。
System.out.println("list.contains(\"java01\") = " + list.contains("java01"));//查询内容是否存在
System.out.println("list.indexOf(\"xiaomu\") = " + list.indexOf("xiaomu"));//查询数据下标,不存在返回-1
//删除
list.remove();//默认删除第一个数
list.removeFirst();//和remove默认功能一样
System.out.println(list);
list.remove("小木");
list.removeLast();//删除最后一个内容
list.clear();//清空
System.out.println(list);
}
LinkedList底层源码
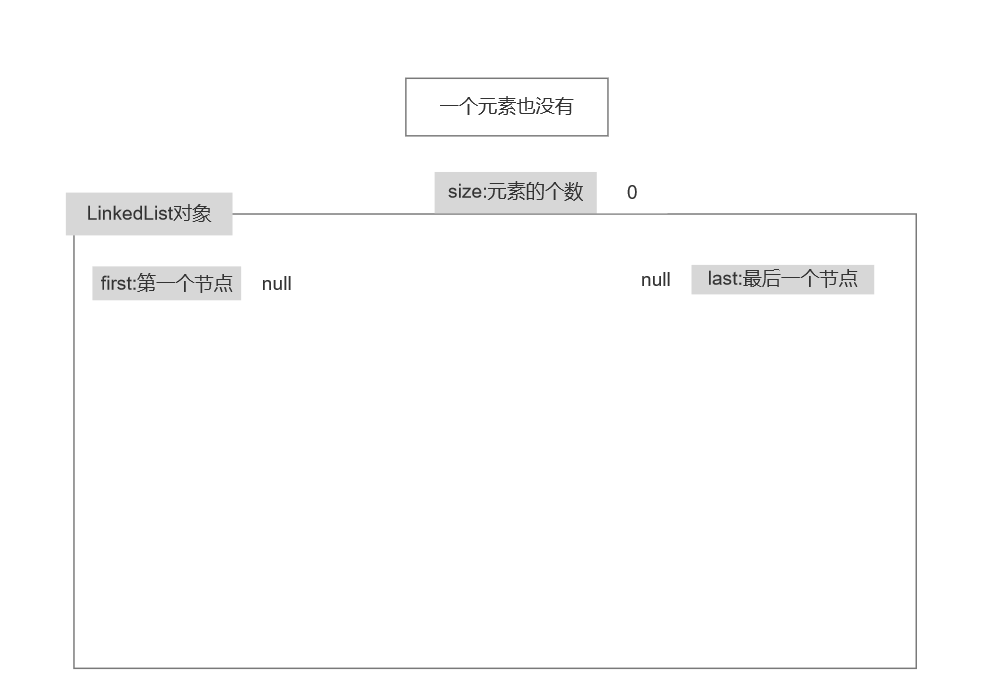
//构造方法:
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
public LinkedList() {
}
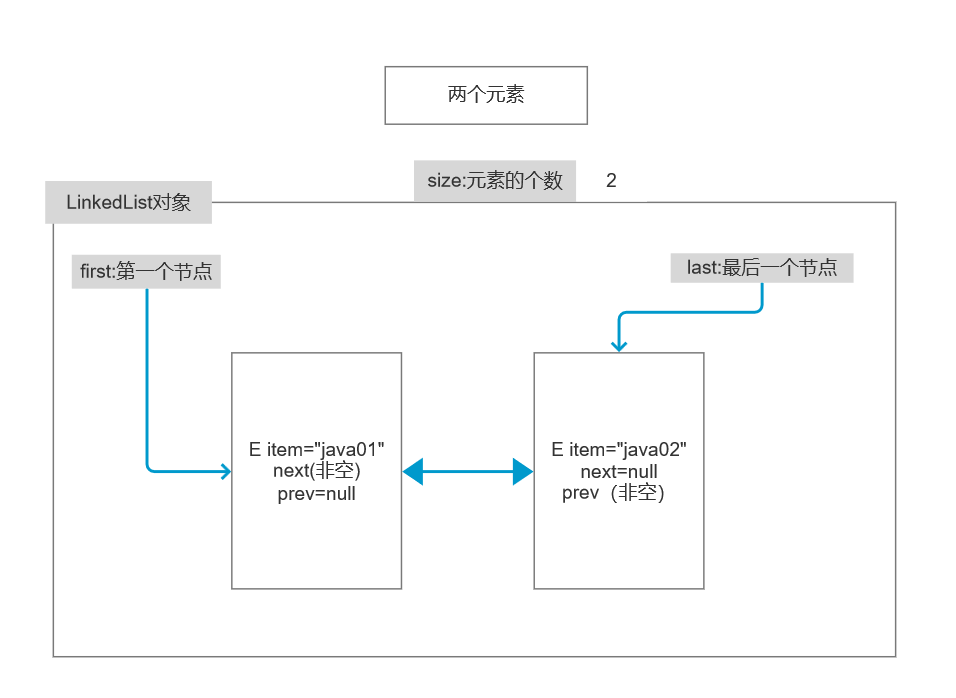
//发现: LinkedList类中存在三个属性: size:元素的个数 first:表示第一个节点 last:最后一个节点
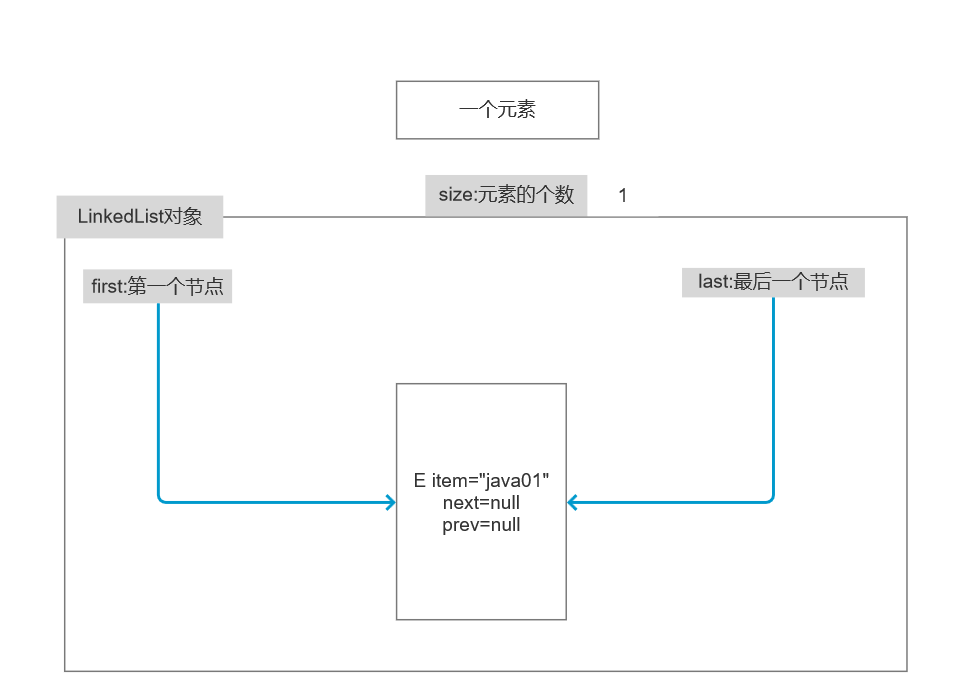
//其中的Node类
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}// E item;当前元素的内容
// Node<E> next;下一个节点
// Node<E> prev;上一个节点
添加属性原理

查询原理
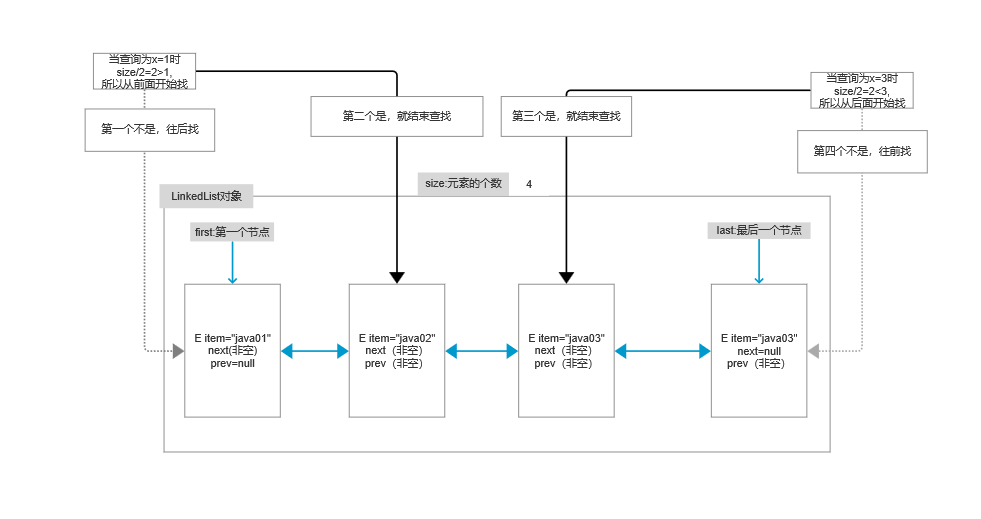
get(index):
public E get(int index) {
checkElementIndex(index);//检查传入的下标是否和否
return node(index).item;
}
//--------------------------------------------------------------------------------
Node<E> node(int index) {
// 判断你传入的下标是否超过元素的一半。
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
ArrayList和LinkedList区别
1.ArrayList:底层使用的数组,查询效率高。中间位置增加和删除元素效率低,因为设计到数组元素的位移。
扩容机制,按照老数组的1.5倍扩展并把老数组的内容复制过去。 Arrays.copyof方法扩容。
2.LinkedList底层使用的链表结构,增加和删除效率高。查询效率低,从前往后或从后往前依次遍历。
HashSet集合
特点: 里面元素无序【添加元素的顺序无关】,而且里面的元素不可重复。
@Test
public void test03(){
HashSet hashSet=new HashSet();//创建一个HashSet对象
//添加元素---发现:set和添加的顺序无关而且没有下标。set中不允许出现重复的内容。允许添加null值。
hashSet.add("java01");
hashSet.add("java02");
hashSet.add("java03");
hashSet.add("java04");
hashSet.add("java05");
hashSet.add("java06");
hashSet.add(null);
System.out.println(hashSet);
//判断元素是否在set集合中
System.out.println("hashSet.contains(\"java\") = " + hashSet.contains("java"));
//遍历---因为该集合没有下标。 所以我们不能使用下标循环遍历。 foreach循环遍历jdk1.5后。
for (Object o :
hashSet) {
System.out.println(o);
}
System.out.println("~~~~~~~~~~~~~~~~~~~~");
//迭代器遍历
Iterator iterator=hashSet.iterator();//获取set集合的迭代器对象。
while (iterator.hasNext()){//判断当前指针是否可以移动到下一位。
Object next= iterator.next();//指针移到下一位,并获取该位上的内容。
System.out.println("next = " + next);
}
//删除只能根据内容删除
hashSet.remove("java06");
hashSet.clear();
}
HashSet底层原理
import java.util.Objects;
public class Student {
private String name;
private int age;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
hashset判断元素是否重复的底层使用的是Hashcode方法和equals方法。
原理:如果对象的中的equals为false,则将值放进集合中,如果为true,则判断hash值是否相同,如果不相同,则将值放进集合中,如果相同则不将元素放进集合中。
TreeSet集合
我们知道HashSet是没有顺序的,而TreeSet最大的特点就是一个有顺序的去重集合容器。
- 集合中的元素没有重复
- 集合中的元素不保证插入顺序,而是默认使用元素的自然排序,不过可以自定义排序器
- jdk8以后,集合中的元素不可以是null
- 集合不是线程安全
- 相对于HashSet, 性能更差。
使用TreeSet
package lx;
import org.junit.Test;
import java.util.Iterator;
import java.util.TreeSet;
public class Demo02 {
@Test
public void test01(){
TreeSet set=new TreeSet();
//添加元素: 元素有序而且不能重复,而这里的有序并不是按照你的添加顺序。而且默认按照元素的自然排序执行。 JDK1.8后不允许添加null值
set.add(1);
set.add(3);
set.add(2);
set.add(1);
set.add(6);
set.add(5);
set.add(4);
System.out.println(set);
System.out.println("set.size() = " + set.size());//求元素的个数。
System.out.println("set.remove(1) = " + set.remove(1));//移除:只能按照内容移除无法使用下标移除
//set.clear();//清空
System.out.println("set.isEmpty() = " + set.isEmpty());//是否为空
System.out.println("set.contains(1) = " + set.contains(1));//判断是否在集合中
Iterator iterator = set.iterator();
while (iterator.hasNext()){//遍历只能使用foreach或迭代
Object o = iterator.next();
System.out.println(o);
}
}
}
TreeSet中添加自定义类时实现自然排序接口
自定义类
package lx01;
public class Animals implements Comparable<Animals>{
private String name;
private int age;
private String Species;
public Animals() {
}
public Animals(String name, int age, String species) {
this.name = name;
this.age = age;
Species = species;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getSpecies() {
return Species;
}
public void setSpecies(String species) {
Species = species;
}
@Override
public String toString() {
return "Animals{" +
"name='" + name + '\'' +
", age=" + age +
", Species='" + Species + '\'' +
'}';
}
@Override
public int compareTo(Animals o) {
if (!(this.age==o.age)){
return this.age-o.age;
}
return 0;
}
}
测试类
package lx01;
import org.junit.Test;
import java.util.TreeSet;
public class Demo01 {
@Test
public void test01(){
//里面的元素---具备排序功能【因为TreeSet元素有序==要求里面的元素具有排序规则。1.自然排序comparable 2. 指定定制排序 】
//自定义类里面没有排序规则,而TreeSet需要根据排序规则排序,所以我们要实现Comparable<Animals>接口,重写里面的compareTo()方法定义规则
TreeSet treeSet=new TreeSet();
treeSet.add(new Animals("团子",2,"猫"));
treeSet.add(new Animals("旺财",3,"狗"));
System.out.println(treeSet);
}
}
定制排序
如果后期往TreeSet中添加的元素类型为系统定义的类对象,而系统定义的类没有实现Comparable接口,如何往TreeSet中添加该类型。 这时就需要定制排序。
实体类
package lx01;
public class Animals{
private String name;
private int age;
private String Species;
public Animals() {
}
public Animals(String name, int age, String species) {
this.name = name;
this.age = age;
Species = species;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getSpecies() {
return Species;
}
public void setSpecies(String species) {
Species = species;
}
@Override
public String toString() {
return "Animals{" +
"name='" + name + '\'' +
", age=" + age +
", Species='" + Species + '\'' +
'}';
}
}
创建定制排序类
package lx01;
import java.util.Comparator;
public class MyCompare implements Comparator<Animals> {
@Override
public int compare(Animals o1, Animals o2) {
return o1.getAge()- o2.getAge();
}
}
测试类
package lx01;
import org.junit.Test;
import java.util.TreeSet;
public class Demo01 {
@Test
public void test01(){
//Comparator comparator=new MyCompare()
//Comparator<? super E> comparator: 它是一个定制排序接口。 多态
TreeSet treeSet=new TreeSet(new MyCompare());//TreeSet中的元素会按照指定的定制排序排序了。
treeSet.add(new Animals("团子",2,"猫"));
treeSet.add(new Animals("旺财",3,"狗"));
System.out.println(treeSet);
}
}
HashMap
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable基于哈希表的实现的Map接口。它是一种key-value映射集合。
此实现提供了所有可选的Map操作,并允许null的值和null键。 ( HashMap类大致相当于Hashtable ,除了它是不同步的,并允许null)。这个类不能保证Map的顺序; 特别是,它不能保证排序在一段时间内保持不变。
使用HashMap===必须会
@Test
public void tese02(){
//创建了一个HashMap对象: 特点:1.key不允许重复 但是value允许重复 2. key和value都可以为null.
HashMap map=new HashMap();
//存放元素 put(key,value).
map.put("name","小木");
map.put("age",18);
map.put("sex","男");
map.put("major","java");
map.put("school","北大");
map.put("name","小木不痞");//出现重复key时,后者把前置覆盖value值。
System.out.println(map);
map.remove("school");//移除---根据key移除。
System.out.println(map);
Object age= map.get("age");//查找--根据key查询
System.out.println(age);
//1.获取map中所有的key.
Set keys = map.keySet();
System.out.println(keys);
//2. 获取map中所有的值
Collection values = map.values();
System.out.println(values);
//3.遍历map.
//遍历map中所有的key
for(Object k:keys){
Object o = map.get(k);//根据key获取对应的值
System.out.println(k+"=============>"+o);
}
map.clear();
map.size();
map.isEmpty();
map.containsKey("");//判断map中是否包含指定的key
}
底层源码
底层按照数组+链表 数组+红黑树实现。
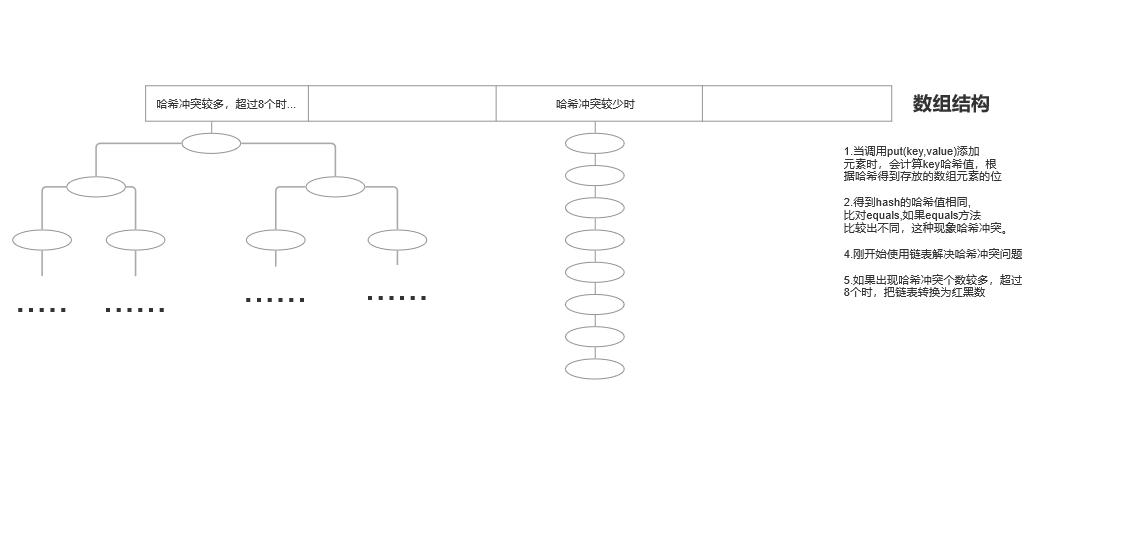
集合的架构图。

泛型.
什么是泛型
限制集合中元素的类型。 集合中
集合的工具类.Collections
概述
该类所有的方法都是static静态方法,提供的这些静态方法都是用来操作集合对象。
常用的方法
@Test
public void test01(){
//我们在创建List接口对象时,指定了<>中类型。表示这个集合对象中只能添加字符串类型的元素.
// 当遍历时拿到的类型一定时泛型指定的类型,无需进行强制转换。避免数据安全问题。
List<String> list=new ArrayList();//创建对象,规定泛型
list.add("小木");//规定过泛型之后,不能使用别的类型;
list.add("不痞");
list.add("19");
System.out.println(list);
Collections. reverse(list);//翻转
System.out.println(list);
Collections.sort(list);//排序
System.out.println(list);
Collections.shuffle(list);//打乱
System.out.println(list);
}


