
.NET中 kafka消息队列、环境搭建与使用
前面几篇文章中讲了一些关于消息队列的知识,就每中消息队列中间件,我们并没有做详细的讲解,那么,今天我们就来详细的讲解一下消息队列之一kafka的一些基本的使用与操作。
一、kafka介绍
kafka:是一种高吞吐量的分布式发布订阅的消息队列系统,具有高性能和高吞吐率。
1.1术语介绍
Broker
kafka集群包括一个或多个服务器,这种服务器被称为Broker
Topic
主题:每条发布到kafka集群的消息都有一个类别,这个类别被称为Topic,(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker,但用户是需要指定消息的Topic即可生产或消费数据,而不必关心数据存于何处)
Partition
分区:Partition是物理上的概念,每个Topic包含一个或多个Partition,(一般kafka节点数cpu的总核数)
Producter
生产者:负责发布消息到kafka broder
Consumer
消费者:从kafka broker读取消息的客户端
Consumer Group
消费者组:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name,则属于默认的group)。
1.2基本特性
可扩展性
在不需要下线的情况下进行扩展,数据流分区(partition)存储在多个机器上
高性能
单个broker就能服务上千客户端,单个broker每秒读/写可达美国几百兆字节,多个brokers组成的集群将达到非常强大的吞吐能力。
性能稳定
无论数据多大,kafka在底层采用了操作系统级别的页缓存,同时将随机于操作改为顺序写,再结合Zero-Copy的特性集答的改善了IO性能。
1.3消息格式
一个topic对应一种消息格式,因此消息用topic分类,一个topic代表的消息有一个或多个partition组成,一个partition应该存放在多个servier上,如果只有一个server,就没有冗余备份,是单机而不是集群;如果有多个server,一个server为leader(领导者),其他server为follower(跟随者),leader需要接收读写请求,follower仅作冗余备份,leader出现故障,会自动选举一个follower作为leader,保证服务不中断,每个server都可能扮演一些partition的leader核其partition的follower角色,这样整个集群就会打到负载均衡的效果。
消息按顺序存放,消息顺序不可改变,智能追加消息,不能插入,每个消息都有一个offset,用作消息ID,在每个partition中唯一,offset由consumer保存和管理,因此读取顺序实际上是完全由consumer决定的,不一定是线性的,消息有超时日期,过期则删除。
1.4原理解析
producer创建一个topic时,可以指定topic为几个partition(默认是1,配置num.partitions),然后会把partition分配到每个broker上,分配的算法是:a个broker,第b个partition分配到b%a的broker上,可以指定由每个partition有几份副本Replication,副本的分配策略为:第c个副本存储在第(b+c)%a的broder上,一个partition在每个broker上是一个文件夹,文件夹中的文件命名方式为:topic名称+有序序号。每个partition中文件是一个个的segment,segment file由.index和.log文件组成,两个文件的命名规则是,上一个segment file的最后一个offset,这样,可以快速删除old文件。
producer向kafka里push数据,会自动的push到所有的分区上,消息是否push成功有几种情况:1、接受到partition的ack就算成功,2、全部副本都写成功才算成功;数据可以存储多久,默认是两天;producer的数据会先存到缓存中,等大小活时间到达阈值时,flush到磁盘,consumer只能读到磁盘中的数据。
二、win10下kafka简单安装以及使用。
http://kafka.apache.org/quickstart#quickstart_multibroker kafka使用文档说明
kafka依赖于zookeeper,官网下的kafka内置了zookeeper依赖,
1、进入kafka官网,下载页面: http://kafka.apache.org/downloads 进行下载,选择二进制文件,在选择任意镜像文件下载。


下载成功后解压到本地文件夹,我这里解压到了D盘

2、配置关键文件
只需要关注bin目录和config目录
在kafka根目录下,新建data和kafka-logs文件夹,后面要用到,作为kafka快照和日志的存放文件夹

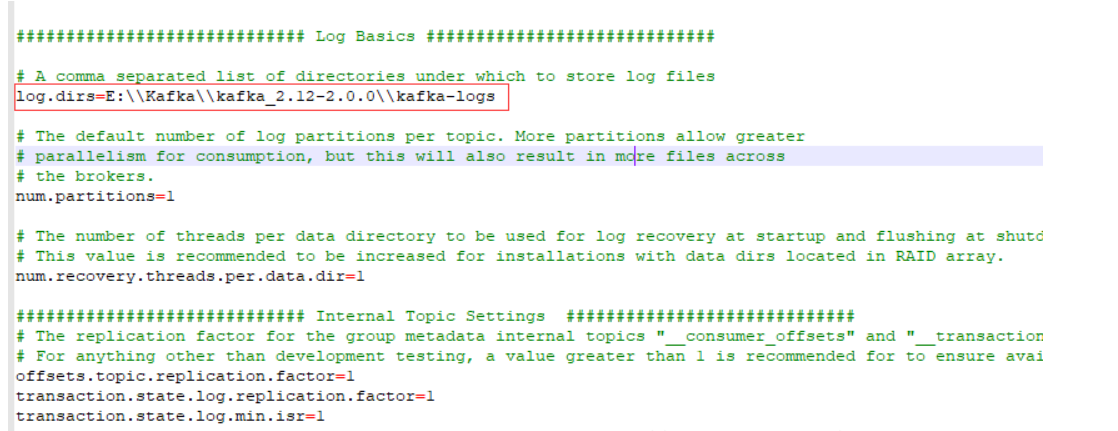
进入到config目录,修改service.properties里面log.dirs路径为log.dirs=E:\\Kafka\\kafka_2.12-2.0.0\\kafka-logs(注意:文件夹分隔符一定是“\\”)
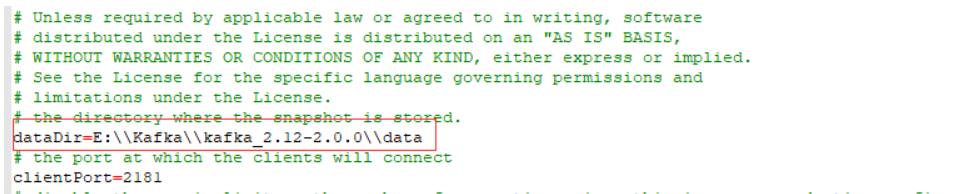
修改zookeeper.properties里面dataDir路径为dataDir=E:\\Kafka\\kafka_2.12-2.0.00\\data
【service.properties】
【zookeeper.properties】
3、进行单及实例测试简单使用
我这里观景是windows,使用的是路径E:\\Kafka\kafka_2.12-2.0.0\bin\windows下批处理命令,如果有问题,参见步骤:、
1)启动kafka内置的zookeeper
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
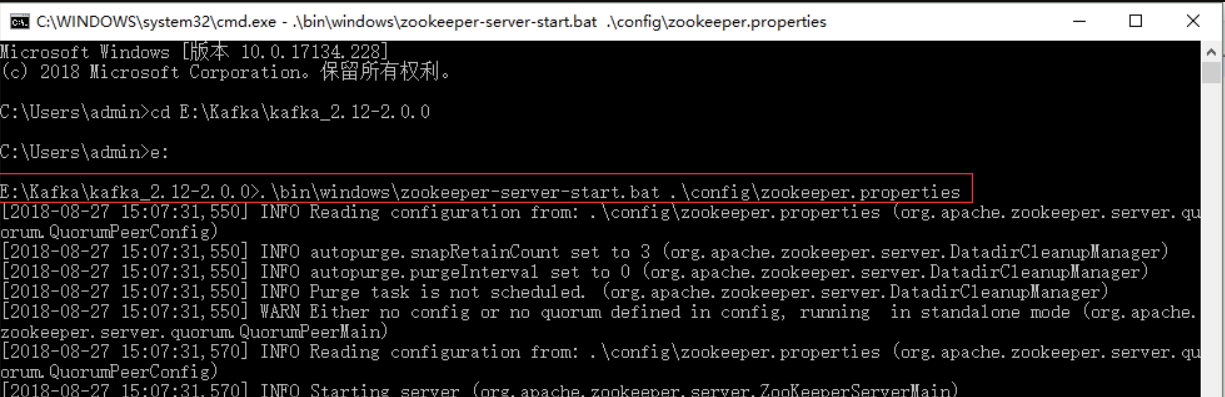
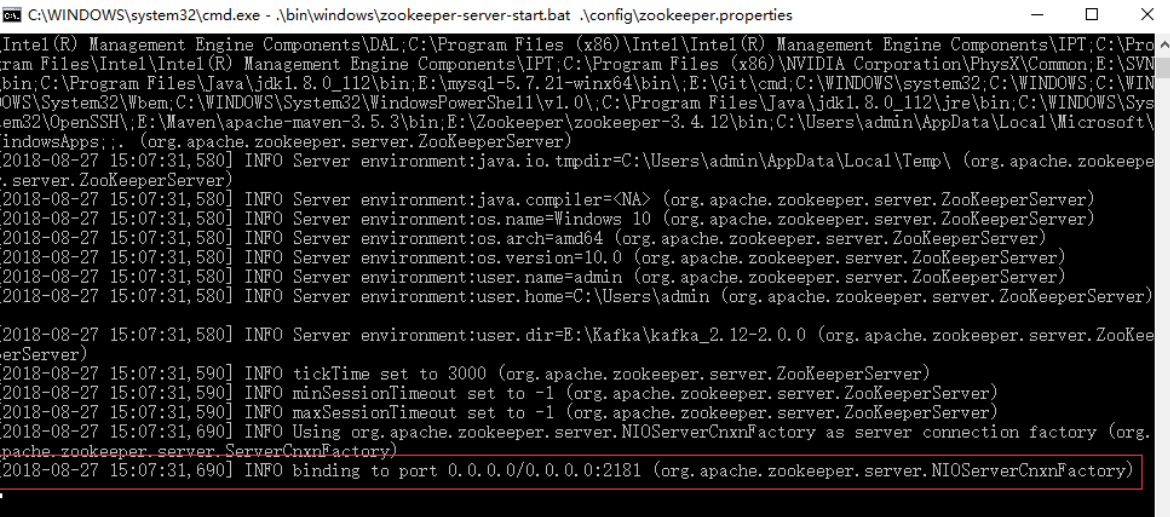
出现binding to port…… 标识zookeeper启动成功,不关闭页面
2)kafka服务启动,成功不关闭页面
.\bin\windows\kafka-server-start.bat .\config\server.properties

3)创建topic测试主题kafka,成功不关闭页面
.\bin\windows\kafka-topic.bat --create --zookeeper localhost:2181 --replication-factor 1 --partition 1 --topic test

4)创建生产者生产消息,不关闭页面
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic test

5)创建消费者接收消息,不关闭页面
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning
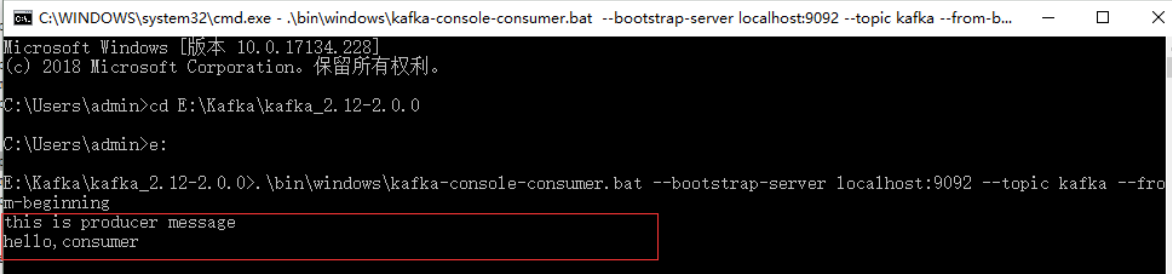
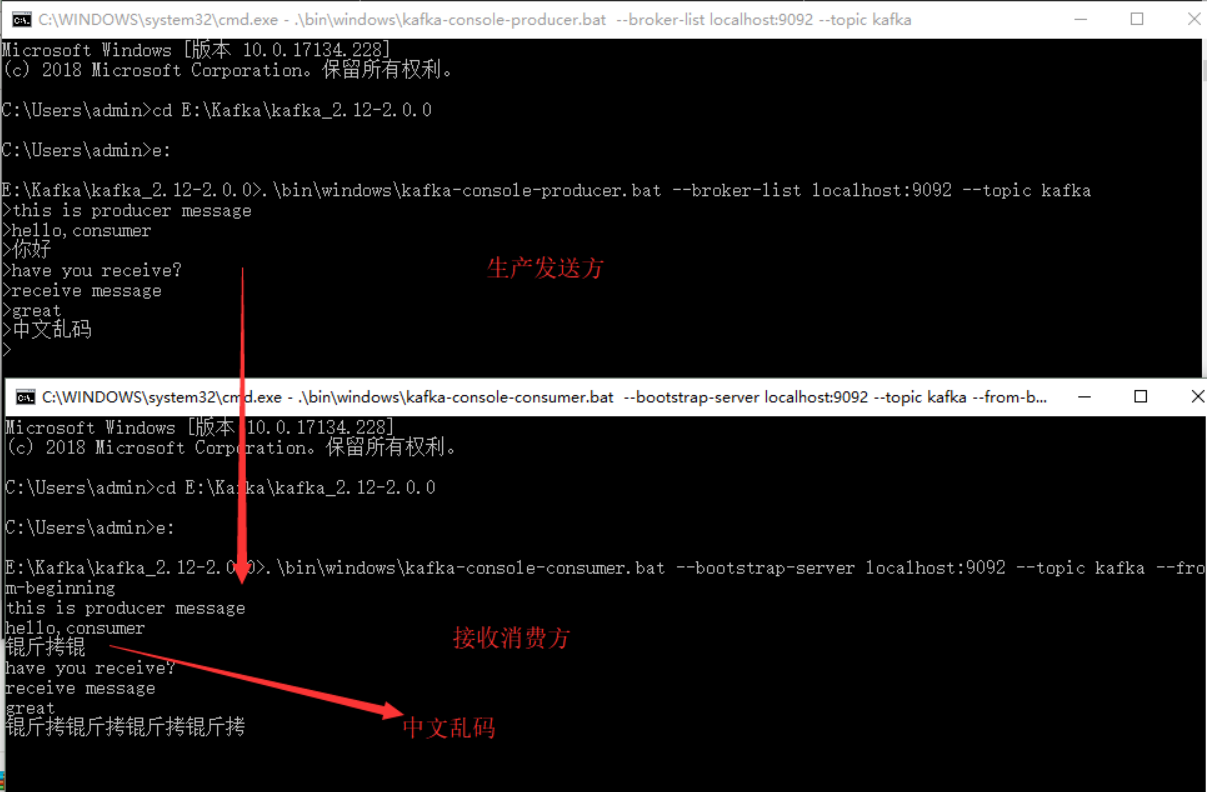
到此,测试结束。对于kafka的使用,本人还是菜鸟一枚,还请高手指点一二。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号