XML的相关基础知识分享(二)
前面我们讲了一下XML相关的基础知识(一),下面我们在加深一下,看一下XML高级方面。
一、命名空间
1、命名冲突
XML命名空间提供避免元素冲突的方法。
命名冲突:在XML中,元素名称是由开发者定义的,当两个不同的文档使用相同的原俗名时,就会发生命名冲突。例如:下面这个XML文档携带者某个表格中的信息:
1 <table>
2 <tr>
3 <td>Apples</td>
4 <td>Bananas</td>
5 </tr>
6 </table>
这个XML文档携带有关桌子的信息(一件家具):
1 <table>
2 <name>African Coffee Table</name>
3 <width>80</width>
4 <length>120</length>
5 </table>
假如这两个XML文档被一起使用,由于两个文档都包含带有不同内容和定义的<table>元素,就会发生命名冲突。XML解析器无法确定如何处理这类冲突。
2、使用前缀来避免命名冲突
此文档带有某个表格的信息:
<table>
<name>African Coffee Table</name>
<width>80</width>
<length>120</length>
</table>
此XML文档携带着有关一件家具的信息:
<f:table>
<f:name>African Coffee Table</f:name>
<f:width>80</f:width>
<f:length>120</f:length>
</f:table>
现在,命名冲突不存在了,这是由于两个文档都使用了不同的名称来命名他们<table>元素(<h:table>和<f:table>),通过使用前缀,我们创建了两种不同类型的<table>元素。
2、使用命名空间
这个XML文档携带着某个表格的信息:
<h:table xmlns:h="http://www.w3.org/TR/html4/">
<h:tr>
<h:td>Apples</h:td>
<h:td>Bananas</h:td>
</h:tr>
</h:table>
此XML文档携带着有关一件家具的信息:
<f:table xmlns:f="http://www.w3school.com.cn/furniture">
<f:name>African Coffee Table</f:name>
<f:width>80</f:width>
<f:length>120</f:length>
</f:table>
与仅仅使用前缀不同,我们为<table>标间添加了一个xmlns属性,这样就为前缀赋予了一个与某个命名控件相关联的限定名称。
3、XML Namespace(xmlns)属性
XML命名空间属性被放置于元素的开始标间之中,并使用语法:xmlns:namespace-prefix="namespaceURI"
当命名空间被定义在元素的开始标签中时,所有带有相同前缀的子元素都会与同一个命名空间关联。
注释:用于标示命名空间的地址不会被解析器用于查找信息,其唯一的作用是赋予命名空间一个唯一的名称,不过,很多公司常会作为指针来使用命名空间指向实际存在的网页,这个网页包含命名空间的信息。
4、统一资源标识符(Uniform Resource Identifier(URL))
统一资源标识符是一串可以标识因特网资源的字符。最常用的URI是用来标识因特网域名地址的统一资源定位器(URL),另一个不那么常用的URI是统一资源命名(URN)。在我们的例子中,我们仅使用URL。
5、默认的命名空间(Default Namespace)
为元素定义默认的命名空间可以让我们省去在所有子元素中使用前缀的工作。语法:xmlns="namespaceURI"
这个XML文档携带着某个表格中的信息:
<table xmlns="http://www.w3.org/TR/html4/">
<tr>
<td>Apples</td>
<td>Bananas</td>
</tr>
</table>
此XML文档携带着有关一件家具的信息:
<table xmlns="http://www.w3school.com.cn/furniture">
<name>African Coffee Table</name>
<width>80</width>
<length>120</length>
</table>
6、命名空间的实际应用
当开始使用XSL时,您不久就会看到实际使用中的命名空间。XSL样式表用于将XML文档转换为其他格式,比如HTML。如果您仔细观察下面这个XSL文档,就会看到大多数的标签都是HTML标签。非HTML的标签都有前缀xsl,并由此命名空间标示:“http://www.w3.org/1999/XSL/Transform”:
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<html>
<body>
<h2>My CD Collection</h2>
<table border="1">
<tr>
<th align="left">Title</th>
<th align="left">Artist</th>
</tr>
<xsl:for-each select="catalog/cd">
<tr>
<td><xsl:value-of select="title"/></td>
<td><xsl:value-of select="artist"/></td>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
二、CDATA区段
所有XML文档中的文本均会被解析器解析,只有CDATA区段(CDATA section)中的文本会被解析器忽略。
1、PCDATA
PCDATA指的是被解析的字符数据(Parsed Character Data)。XML解析器通常会解析XML文档中所有的文本,当某个XML元素被解析时,其标签之间的文本也会被解析,如:<message>此文本也会被解析</message>
解析器之所以这么做是因为XML元素可以包含其他元素,就像下面例子中<name>元素包含着另外的两个元素first和last:<name><first>Bill</first><last>Gates</last></name>
而解析器会把它分解为像这样的子元素:
<name>
<first>Bill</first>
<last>Gates</last>
</name>
2、转义字符
非法的XML字符必须被替换为实体引用(entity reference)
假如您在XML文档中放置了一个类似“<”的字符,那么这个文档会产生一个错误,这是因为解析器会把它解释为新元素的开始,因此你不能这样写:<message>if salary < 1000 then</message>。为了避免此类错误,需要把字符“<”替换为实体引用,就像这样:<message>if salary < 1000 then</message>。
在XML中,有5个预定义的实体引用:
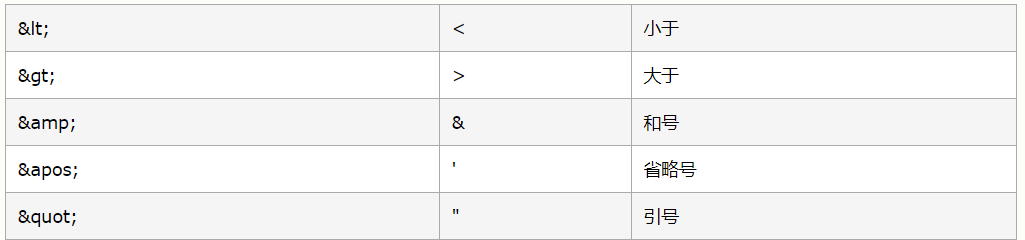
注释:严格的讲,在XML中仅有字符“<”和“&”是非法的,省略号,引号和大于号是合法的,但是把他们替换为实体引用是个好习惯。
3、CDATA
术语CDATA指的是不应由XML解析器进行解析的文本数据(Unparsed Character Data)。在XML元素中,“<”和“&”是非法的。"<"会产生错误,因为解析器会把该字符解释为新元素的开始。"&"也会产生错误,因为解析器会把该字符解析为字符实体的开始。某些文本,比如JavaScript代码,包含大量的“<"和“&”字符,为了避免错误,可以将脚本代码定义为CDATA。CDATA部分中的所有内容都会被解析器忽略。CDATA部分由"<![CDATA["开始,由“]]>”结束:
<script>
<![CDATA[
function matchwo(a,b)
{
if (a < b && a < 0) then
{
return 1;
}
else
{
return 0;
}
}
]]>
</script>
在上面的例子中,解析器会忽略CDATA部分中的所有内容。
注意:CDATA部分不能包含字符串”]]>“,也不允许嵌套的CDATA部分。标记CDATA部分结尾的”]]>“不能包含空格或折行。
好了,关于这次的XML相关知识分享,本次就先到这里。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号