在Ubuntu上搭建hive环境
一、准备软件

二、安装虚拟机
1.新建虚拟机向导

2.安装客户机操作系统

3.用户名密码设置
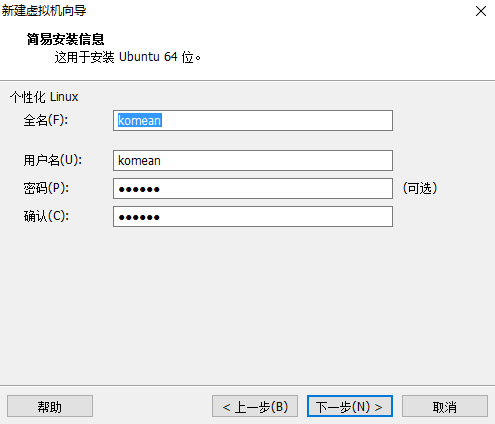
4.设置虚拟机名称和保存位置
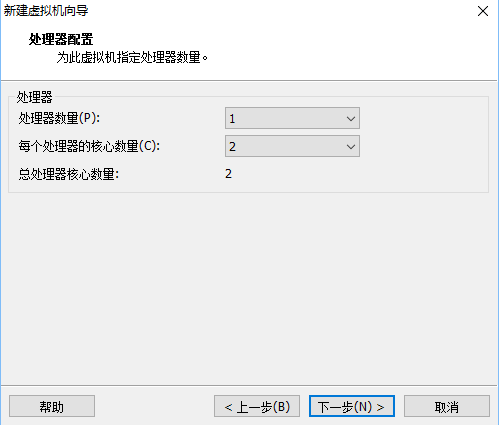
5.处理器设置
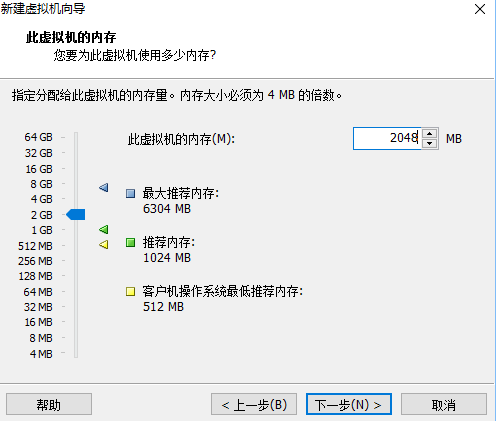
6.设置虚拟机内存
7.然后一直next下去(有的根据自己的意识改一下有些命名,其他的按照推荐)
三、安装 Hadoop
1.先将下载好的软件放入Ubuntu的home/Downloads目录下
2.解压jdk

3.将 解压后的jdk1.7.0_79移动到/opt/java(注意在opt路径下创建java路径:mkdir java)路径下
注:有的用户不是root权限,需要先获得root权限
sudo su

移动文件的代码:
sudo mv /home/komean/Downloads/jdk1.7.0_79 .

4.对 jdk 的环境变量进行配置,打开系统环境变量配置文件
gedit /etc/profile

在文本最后添加配置如下
export JAVA_HOME=/opt/java/jdk1.7.0_79 export CLASSPATH=.:${JAVA_HOME}/lib:${JAVA_HOME}E/lib export PATH=${JAVA_HOME}/bin:$PATH
添加完环境变量后,需要使更改过的环境变量系统文件生效
source /etc/profile
5.检测java

6.安装 ssh (ssh 可直接 ubuntu 软件市场的 apt-get 命令进行下载)为了配合hadoop 的使用,需要将ssh 设置为无密码登录
sudo apt-get install openssh-server

在更目录(就是有opt,usr那个目录)
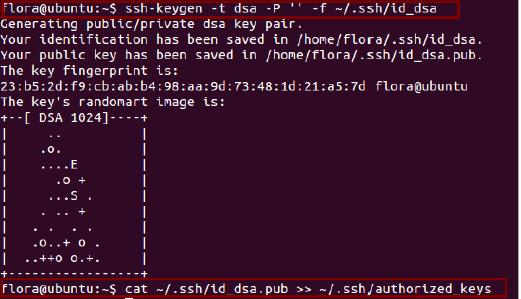
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
通过连接本地来测试安装与配置是否成功
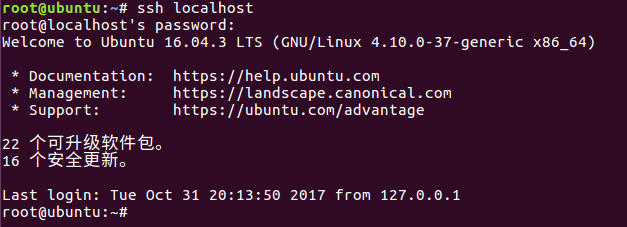
注释:有的root账号无法登录SSH问题-Permission denied, please try again.
在root权限下
gedit /etc/ssh/sshd_config

ctrl+f找到"# Authentication:"
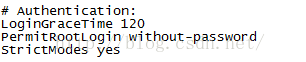
将下面三行内容替换成:
LoginGraceTime 120 #PermitRootLogin prohibit-password PermitRootLogin yes StrictModes yes
重启
7.安装 Hadoop
完成前两步的操作,接着安装 Hadoop。前两步都是Hadoop 运行时必不可少的软件,所以请勿忽略。同理,将hadoop-2.6.5.tar.gz 下载下来,对其进行解压缩。将解压缩的hadoop-2.6.4 存放到/usr/local/路径下,然后同样需要配置Hadoop的环境变量,这些过程与安装jdk 时使用的命令与过程相同,在此不再赘述。主要讨论如何将Hadoop 配置为本地模式。配置过程主要为对以下文件的修改。 注意:在配置前 /usr/local/下创建hadoop路径,在hadoop下创建 tmp路径,以及在tmp路径下创建dfs路径,以及在dfs路径下创建name和data
解压hadoop-2.6.5.tar.gz
sudo tar -zxf hadoop-2.6.5.tar.gz

sudo mv /home/komean/Downloads/hadoop-2.6.5 .

/usr/local/下创建hadoop路径,在hadoop下创建 tmp路径,以及在tmp路径下创建dfs路径,以及在dfs路径下创建name和data
没有root权限先获取root权限
sudo su





进入/usr/local/hadoop-2.6.5/etc/hadoop
cd /usr/local/hadoop-2.6.5/etc/hadoop

(1)配置文件core-site.xml
gedit core-site.xml

在文本后配置
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
(2)配置文件hdfs-site.xml
gedit hdfs-site.xml

在文本后配置
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
(3)配置文件mapred-site.xml.template
gedit mapred-site.xml.template

在文本后配置
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
(4)配置文件Hadoop-env.sh
gedit hadoop-env.sh

找到export JAVA_HOME,配置JAVA_HOME路径
export JAVA_HOME="/opt/java/jdk1.7.0_79"
(5)在/etc/profile 文件加入 Hadoop 的环境变量

export JAVA_HOME=/opt/java/jdk1.7.0_79 export CLASSPATH=.:${JAVA_HOME}/lib:${JAVA_HOME}E/lib export HADOOP_HOME=/usr/local/hadoop-2.6.5 export PATH=${JAVA_HOME}/bin:$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
(6)使用命令source /etc/profile 使环境变量更新起作用
source /etc/profile

(7)配置完成后,需要验证是否配置正确
初始化 HDFS 系统
进入 /usr/local/hadoop-2.6.5
cd /usr/local/hadoop-2.6.5

Hadoop初始化
bin/hdfs namenode -format

Hadoop启动
sbin/start-all.sh
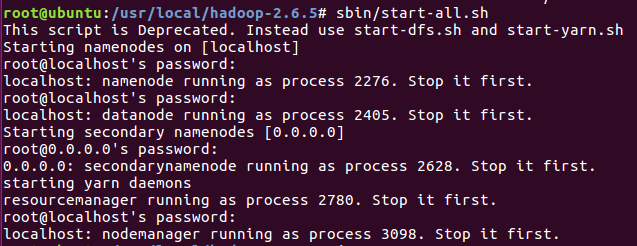
JPS 语句检测(注意:这里表示成功的信息必须含有除掉 JPS 的其他五个进程,缺一不可,如若出现缺少,如果是DataNode 以及 NameNode,那么就是 dfs 的配置不正确,重新配置然后删掉原来生成temp 文件,重新启动)
jps
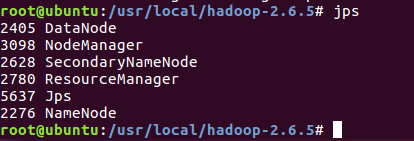
四。安装Hive
1.安装 MySQL
sudo apt-get install mysql-server

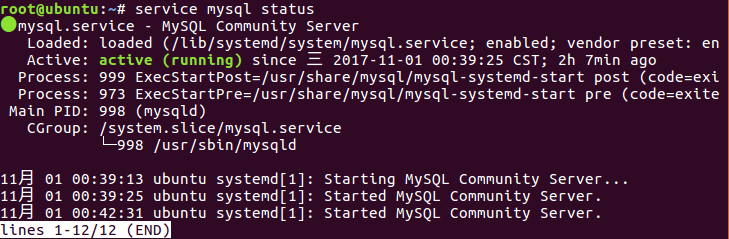
检查MySQL 进程是否已经启动
service mysql status
登录MySQL
mysql -u root -p

2.安装 Hive
解压apache-hive-1.2.1-bin.tar.gz
sudo tar -zxf apache-hive-1.2.1-bin.tar.gz

移动到/usr/local/hadoop-2.6.5/hive路径下
sudo mv /home/komean/Downloads/apache-hive-1.2.1-bin .

在/etc/profile 文件中,添加 HIVE_HOME和PATH
gedit /etc/profile
配置如下:
export JAVA_HOME=/opt/java/jdk1.7.0_79 export CLASSPATH=.:${JAVA_HOME}/lib:${JAVA_HOME}E/lib export HADOOP_HOME=/usr/local/hadoop-2.6.5 export HIVE_HOME=/usr/local/hadoop-2.6.5/hive/apache-hive-1.2.1-bin export PATH=${JAVA_HOME}/bin:$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH:${HIVE_HOME}/bin
保存
source /etc/profile
修改Hive 本身的配置文件(在/usr/local/hadoop-2.6.4/apache-hive-1.2.1-bin/conf 中复制一份 hive-default.xml.template ,并重命名为 hive-size.xml 文件。)
cp hive-default.xml.template hive-size.xml

编辑hive-size.xml
gedit hive-size.xml

(1)修改javax.jdo.option.ConnectionURL属性
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
(2)修改javax.jdo.option.ConnectionDriverName属性
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
(3)修改javax.jdo.option.ConnectionUserName属性。即数据库用户名
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
(4)修改javax.jdo.option.ConnectionPassword属性。即数据库密码
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
(5)添加如下属性hive.metastore.local
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
(6)修改hive.server2.logging.operation.log.location属性,因为默认的配置里没有指定具体的路径
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/usr/local/hadoop-2.6.5/hive/tmp/hive/operation_logs</value>
<description>Top level directory where operation logs are stored if logging functionality is enabled</description>
</property>
(7)修改hive.exec.local.scratchdir属性
<property>
<name>hive.exec.local.scratchdir</name>
<value>/usr/local/hadoop-2.6.5/hive/tmp/hive</value>
<description>Local scratch space for Hive jobs</description>
</property>
(8)修改hive.downloaded.resources.dir属性
<property>
<name>hive.downloaded.resources.dir</name>
<value>/usr/local/hadoop-2.6.5/hive/tmp/hive/resources</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
(9)修改属性hive.querylog.location属性
<property>
<name>hive.querylog.location</name>
<value>/usr/local/hadoop-2.6.5/hive/tmp/hive/querylog</value>
<description>Location of Hive run time structured log file</description>
</property>
注意,在
/usr/local/hadoop-2.6.5/hive 路径下新建tmp目录,tmp下新建hive目录,hive下新建
operation_logs、resources、querylog目录



注意:将/usr/local/hadoop-2.6.5/hive/apache-hive-1.2.1-bin/lib下的jline-2.12.jar替换掉/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib自带的包。不然会报错
最后,将下载的 mysql-connector-java-5.0.8-bin.jar复制到 /usr/local/hadoop-2.6.5/hive/apache-hive-1.2.1-bin/lib中
检验
进入
/usr/local/hadoop-2.6.5
cd /usr/local/hadoop-2.6.5

Hadoop初始化(第一次需要,以后不需要)
bin/hdfs namenode -format
Hadoop启动
sbin/start-all.sh
jps检验
jps
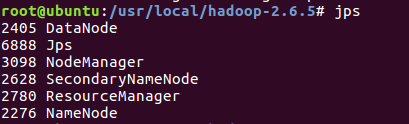
MySQL启动
service mysql start

重点hive启动:
1.如果我们在home下面进入hive,那么我们的metastore_db,就会产生在home目录下。
2.如果我们在/usr目录下进入hive,那么我们的metastore_db,就会产生在usr目录下。
这里我们选择在/usr/local/hadoop-2.6.5启动hive
hive

数据库设计:
# 0.创建库 CREATE DATABASE SW; # 使用sw USE SW; # 1.创建Time维度表 CREATE TABLE Time( Time_key BIGINT, year INT, month INT, day INT) row format delimited fields terminated by '\t'; # 导入time.txt LOAD DATA LOCAL INPATH '/home/komean/Downloads/data/time.txt' OVERWRITE INTO TABLE Time; # 2.创建Software维度 CREATE TABLE Software( Software_key STRING, software_name STRING) row format delimited fields terminated by '\t'; # 导入software.txt LOAD DATA LOCAL INPATH '/home/komean/Downloads/data/software.txt' OVERWRITE INTO TABLE Software; # 3.创建软件中心维度 CREATE TABLE Software_center( Software_center_key STRING, software_center_name STRING, software_center_site STRING) row format delimited fields terminated by '\t'; # 导入software_center.txt LOAD DATA LOCAL INPATH '/home/komean/Downloads/data/software_center.txt' OVERWRITE INTO TABLE Software_center; # 4.创建Area维度表 CREATE TABLE Area( Area_key STRING, area_name STRING) row format delimited fields terminated by '\t'; # 导入area.txt LOAD DATA LOCAL INPATH '/home/komean/Downloads/data/area.txt' OVERWRITE INTO TABLE Area; # 5.创建Fact表 CREATE TABLE Fact( Time_key BIGINT, Software_key STRING, Software_center_key STRING, Area_key STRING, Software_rate float, Software_download_count BIGINT, Software_download_site STRING) row format delimited fields terminated by '\t'; # 导入area.txt LOAD DATA LOCAL INPATH '/home/komean/Downloads/data/fact.txt' OVERWRITE INTO TABLE Fact;
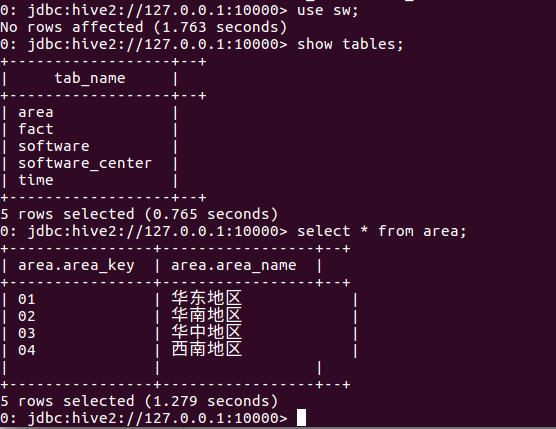
效果检测:
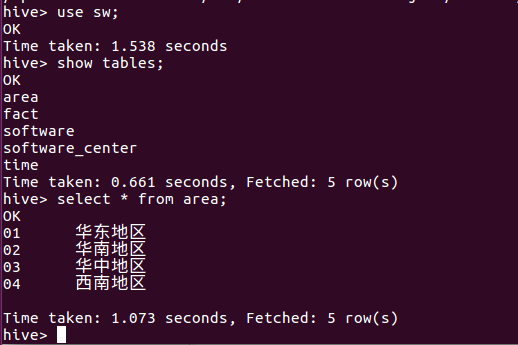
设置端口
gedit hive-size.xml

<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
<description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'.</description>
</property>
当我们要通过WEB连接驱动访问hive时,先必须开启hiveserver2服务(/usr/local/hadoop-2.6.5目录下开启)
hive --service hiveserver2

(在这个窗口不关闭的情况下)然后,在/usr/local/hadoop-2.6.5/hive/apache-hive-1.2.1-bin/bin路径下打开终端(通过终端进入一样)
beeline

连接
!connect jdbc:hive2://127.0.0.1:10000
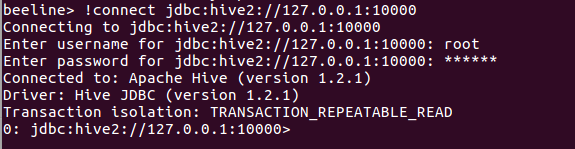
查询我们刚刚在hive中建立的信息