

jmeter常见配置介绍
任一配置修改以后,重启才能生效
临时修改
菜单栏: options(选项) > choose language > chinese
永久修改中文
bin目录下.properties,属性配置language=zh_CN
Jmeter文件结构
/*
bin:
+ 启动、配置参数
+ jmeter中,所有以.properties结尾的文件,都是jmeter的**属性**配置文件
jmeter的堆栈信息配置
+ windows: jmeter.bat HEAP=
+ linux\mac: jmeter
+ 默认为:Defaults to '-Xms1g -Xmx1g -XX:MaxMetaspaceSize=256m'
docs:文档 api 对jmeter进行二次开发,需要去阅读api文档
extras: 扩展 额外的 在CICD 使用
lib(library): meter工具代码打成的jar文件
ext:存放第三方插件
printable_docs: jmeter的**离线**帮助文档
*/jmeter面版
-
00:00:00
-
脚本总共运行的时间
-
-
三角形图标 + 后面数字
-
开启jmeter工具运行的日志, 数字,工具运行过程中错误数量
-
不代表,脚本请求过程中是否有错误
-
如果有红色数字,说明jmeter工具运行过程中,工具出错了。
-
-
0/0
-
前面数字: 当前我们在做性能测试时运行中的线程数
-
后面的数字:总共启动的线程数(你性能场景设计时,设置的线程数,并且系统产生的数量)
-
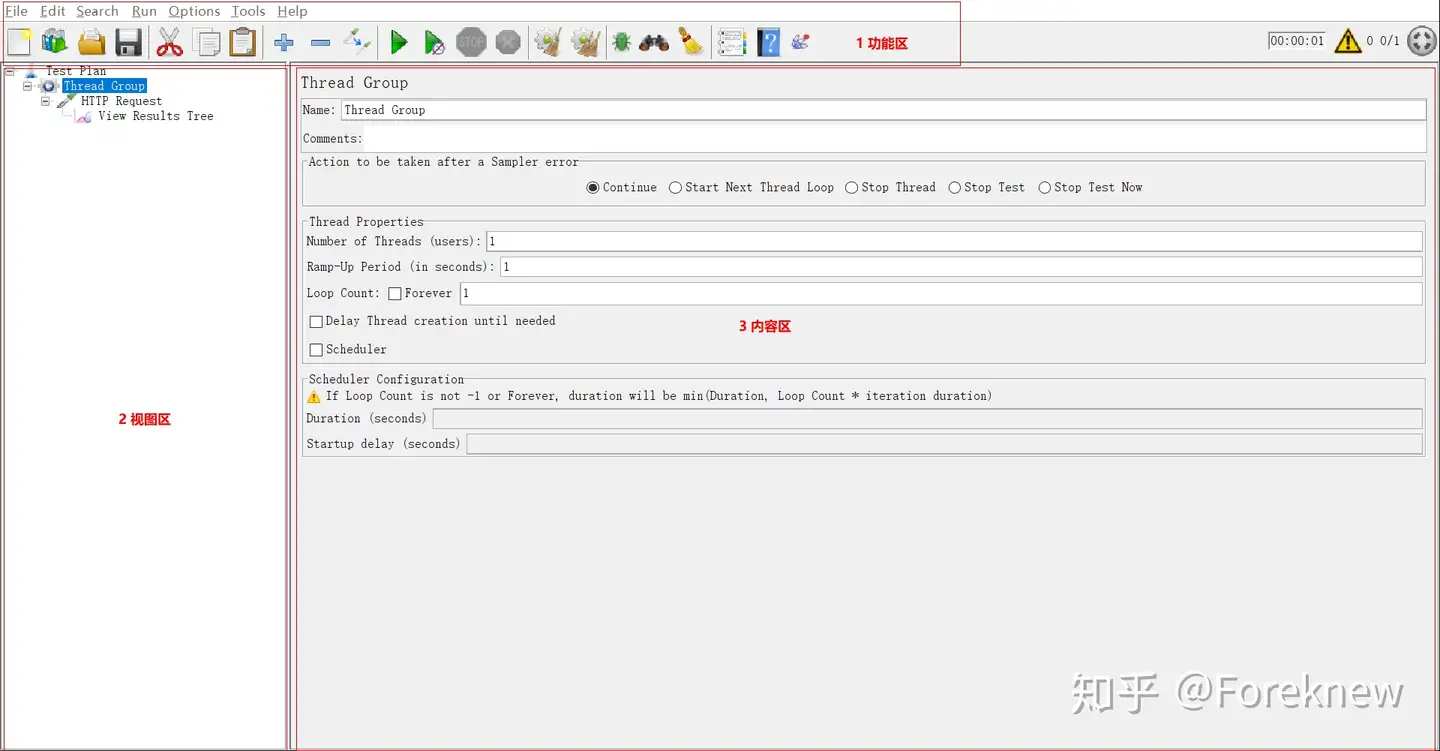
jmeter测试计划
-
测试计划( Testplan)
-
脚本根目录,树的根节点
-
-
配置元件
-
在脚本之前要准备的一些事情
-
配置元件,在脚本中,优先级是最高的,最先被执行
-
如果配置元件出错,会导致整个脚本不运行
-
如:用户定义变量、 csv数据文件设置
-
-
监听器
-
进行脚本开发阶段,需要使用监听器,但是,在性能测试执行时,建议不要使用监听器(禁用)
-
因为,监听器是要分析响应的结果,这个分析是要消耗资源(消耗的是发起方的资源)
-
-
定时器
-
定时设置
- 同步定时器,用于做狭义并发,可以控制取样器达到多少用户数的时候同时并发
-
配置元件和前置处理器
用户参数,是前置处理器元件,
户定义变量,是配置元件
# 配置元件的 优先级最高,最先被执行,也就是说,用户定义变量 优先级比用户参数要高,用户定义变量会比用户参数先执行。配置元件优先级
/*
配置元件: 优先级是最高的
1、如果放在线程组下,它作用域整个线程组
2、如果是放在某个取样器下面,它就作用于当前这个取样器
如果线程组中取样器有自己的值,才使用自己的值
*/取样器
-
作用域
-
只作用自身
-
-
优先级
-
根据不同的协议,编写脚本------脚本的执行体,是我们的先后顺序的判断点
-
-
取样器的执行顺序:
-
在没有逻辑控制时,执行顺序从上往下执行。
-
-
查看结果树
-
查看结果树,显示的顺序:收到响应的先后顺序
-
前置处理器
-
优先级
-
在取样器执行之前被执行
-
-
作用域
-
如果它挂在某一个取样器上,那么它的作业域,在当前这个取样器上,以及取样器之后的取样器上。
-
如果它放线程组下面,不在任何一个取样器下面,它作用于整个线程组
-
后置处理器
-
优先级
-
在取样器执行之后被执行
-
-
作用域
-
如果挂载在某一个取样器上面,就是对当前取样器的结果来进行处理
-
如果放在线程组下面呢?----要么报错,要么结果不可空,所以,不要把后置处理器直接挂在线程组下面。
-
定时器
-
作用域
-
作用域于取样器上面
-
用户定义变量
1、在测试计划中定义
2、配置元件中定义
如果是在测试计划中定义,就是全局变量
如果是取样器-配置元件定义,则作用域该取样器
# 用户定义变量:是全局变量,在整个jmeter脚本中,都可以被使用。
# 用户参数:是局部变量,只能在当前的线程组中被使用关于用户自定义变量/用户参数
用户定义变量:可以跨线程组传参的值
用户参数不可以直接跨线程组传参,可使用
_setproperty函数
# 用户定义变量:配置元件
# 用户参数:前置处理器
## **用户定义变量,是全局变量,在启动运行时,获取一次值,在运行过程中,不再获取值。**
## **用户参数,是局部变量,再启动运行时,获取一次值,再运行过程中,还会动态获取值前置处理器-用户参数
/*
每次迭代更新一次-选项:
每次迭代:一轮迭代执行完,是表示:线程组下面所有的取样器执行完一轮,算一个迭代,只有所有的取样器都执行一轮,这个值,才会重新获取
*//*
Jmeter中多个线程组:默认,多线程组是并行执行
可以通过勾选测试计划中,“独立运行每个线程组” 让并行,变成串行。
注意:在性能测试中,不建议去勾选。
*/监听器
保存响应到文本
- Don't add number to prefix 是否要加数字前缀
- Don't add content type suffix 是否要加类型为后缀
- 如果不勾选以上两个,生成的文件就不是想要的文件了,生成的是 test_file_01.txt.plain 这样的测试计划,就不是对应的文件格式文件了
- 注意:
-
-
聚合报告
每一行是一种事务
-
样本数 vs 并发数
-
样本数:一定量的并发用户数,执行一段时间之后的总的请求数量
-
样本数 = 一定量的并发用户数 * 运行时长 * tps
-
单独看样本,并不知道并发用户数是多少
-
-
时间: 平均数、中位数、90% 95% 99% 最小值 最大值
-
单位: 毫秒 ms
-
90% 95% 99%
-
90%: 在所有的样本时间中,有90%的样本时间是小于等于这个时间的
-
-
最小值、最大值
-
-
异常率: 在总的请求次数中,有多少的请求失败的
-
没有断言时,发起方到服务器,服务器处理失败的数量 / 总样本数
-
如果有断言, 要加上断言/总样本数
-
企业中一般的标准 0.1% 0.01%
-
-
吞吐量:等价于tps?的两个条件
-
1、在没有网络瓶颈的时候,我们才能看吞吐量
-
性能测试时,并发用户数不变的时候,才能看吞吐量。
-
如果并发用户数,是变化的,就不能看这个值。
-
因为,这个值,是一个平均值
-
这两个条件,有任何一个不满足,都不能用这个吞吐量来衡量服务器处理能力。
-
-
-
吞吐量=总样本数 / 时间 得到的一个平均值
-
并发用户数 * 时间 * 频率(tps)/时间
-
吞吐量 = 并发用户数 * 频率TPS
-
-
接收KB/S 发送KB/s =====吞吐率
-
用带宽 ----这个值,若与带宽比较近,很可能网络已经成为瓶颈了。
-
吞吐率的值,可以大概估算出我们带宽是否成为网络瓶颈
-
-
APDEX 用户满意度指数标准
-
时间标准 1.5s 低于500ms是满意的,500~1.5s能接受的,超过1.5s是不能接受
-
企业的一般标准: 平均响应时间小于1.5s,错误率<0.1%
-
也有企业,90%的时间作为参考
-
-
-
内容编码注意事项
在写get请求的时候,参数值,建议: 不管是什么类型的值,都勾选“编码”
-
请求体的编码控制有3个地方
-
1、内容编码: utf-8 utf8
-
2、json格式,请求头Content-Type:application/json;charset=utf8
-
3、get请求参数: 参数值勾选“编码”
-
get请求的参数,如果有中文,你填写了内容编码utf-8,还必须勾选“编码”,但是,如果只勾选“编码” 可以不填内容编码
-
-
-
post请求json: 内容中如果有中文,需要去写内容编码为utf-8
取样器中的重定向
-
跟随重定向:3xx 在查看结果树中,可以看到请求的过程,也可以提取重定向过程中的信息。 默认勾选
-
自动重定向: 3xx 在查看结果树中,看不到中间跳转过程,也无法提取中间过程的信息
长连接keep-alive
-
默认勾选,表示长连接
/* 出现连接被拒,端口数量不够用时,取消勾选; java.net.BindException: Address already in use: connect 注意:去掉 http请求中 keepalive的勾选 ------ 会导致测试出来的响应时间,会比真实的情况要长一些。 */ -
不勾选,表示短链接
跨线程组传递的两种方式
setproperty
-
使用
__setproperty函数,然后使用_p函数引用属性
文件转接法
一个线程组运行结果,存储到文件,另一个线程组,通过 CSV 读取文件,然后再提取文件中需要的值,作为变量输入
第一个线程组中,调用接口,然后添加监视器-> 保存响应到文件,设置保存文件的路径和文件名前缀
# 响应体中中文乱码的原因:
# 因为jmeter使用的是我们系统的编码,默认是gbk编码,响应编码可能不是gbk,与gbk不兼容
# 解决:通常jmeter.properties配置文件 搜索 encoding 找到 sampleresult.default.encoding= ""把这个的值,修改为 UTF-8


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下