python3脚本调整歌词文件时间戳
场景:截取部分音乐文件,对应歌词的时间要做相应调整。
例如:下方歌词文件,只需要 [00:28] 及以后的内容,而且将第一句 ( [00:28]月光 把天空照亮 )的时间改成 [00:01],那么第二句的时间应该是 [00:06],第三句的时间应该是 [00:12],以此类推
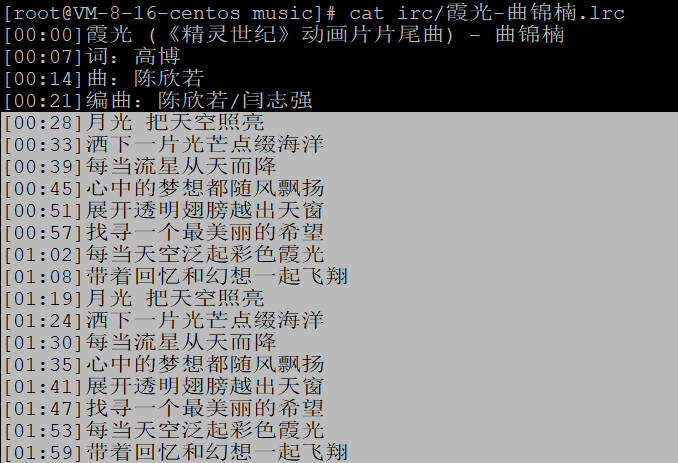
歌词文件中,时间的格式有 [mm:ss] 、[mm:ss:xx] 、[mm:ss:xxx]
[mm:ss] :这是最基本的时间戳格式,只包含分钟和秒。例如:[03:25] 表示第3分钟25秒。
[mm:ss:xx] :这个格式在分钟和秒的基础上增加了十进制的十分之一秒(即百分之一秒或10毫秒的精度)。例如:[03:25:45] 表示第3分钟25秒450毫秒。
[mm:ss:xxx] :这个格式提供了更高的精度,即毫秒级别的精度。xxx 的取值范围是 000 到 999,直接代表毫秒数。例如:[03:25:450] 也表示第3分钟25秒450毫秒。
脚本需要能兼容处理这3种时间格式,处理后的时间统一格式(我统一为[mm:ss:xx])


1 import re 2 import argparse 3 4 def adjust_lrc_from_starting_line(lrc_content, starting_line_index, new_starting_time, remove_pre_data=False): 5 lines = lrc_content.split('\n') 6 7 if starting_line_index < len(lines): 8 # 编译正则表达式以匹配时间戳 9 time_stamp_pattern = re.compile(r"^\[(\d+):(\d+(\.\d+)?)\s*\]") 10 11 # 查找起始行 计算时间差 12 start_match = time_stamp_pattern.search(lines[starting_line_index]) 13 if start_match: 14 start_minutes, start_seconds_str = start_match.groups()[:2] 15 start_seconds = float(start_seconds_str) if '.' in start_seconds_str else float(start_seconds_str) + 0.00 # 确保秒数有小数部分 16 new_minutes, new_seconds = map(float, new_starting_time.split(':')) 17 18 time_difference = (new_minutes * 60 + new_seconds) - (float(start_minutes) * 60 + start_seconds) 19 20 # 更新后续行的时间戳 21 for i in range(starting_line_index, len(lines)): 22 match = time_stamp_pattern.search(lines[i]) 23 if match: 24 minutes, seconds = match.groups()[:2] 25 total_seconds = float(minutes) * 60 + float(seconds) 26 adjusted_seconds = total_seconds + time_difference 27 adjusted_minutes, adjusted_seconds = divmod(adjusted_seconds, 60) 28 adjusted_time_str = f"[{adjusted_minutes:02.0f}:{adjusted_seconds:05.2f}]" 29 30 # 只替换时间戳部分,而不是整行 31 prefix, content = lines[i].split(']', 1) 32 lines[i] = adjusted_time_str + content 33 34 # 在处理完所有行后,根据remove_pre_data的值决定是否移除起始行之前的数据 35 if remove_pre_data: 36 lines = lines[starting_line_index:] 37 return '\n'.join(lines) 38 39 def main(): 40 parser = argparse.ArgumentParser(description="Adjust the timestamps in an LRC file starting from a given line.") 41 parser.add_argument("lrc_file", help="Path to the LRC file.") 42 parser.add_argument("starting_line_index", type=int, help="The starting line index (0-based) for adjustment.") 43 parser.add_argument("new_starting_time", help="New timestamp for the starting line, format 'mm:ss.xx'.") 44 parser.add_argument("--remove-pre-data", "-r", action="store_true", help="Remove data before the starting line index.", default=False) 45 46 args = parser.parse_args() 47 48 with open(args.lrc_file, 'r', encoding='utf-8') as file: 49 lrc_content = file.read() 50 51 new_lrc_content = adjust_lrc_from_starting_line(lrc_content, args.starting_line_index, args.new_starting_time, args.remove_pre_data) 52 print(new_lrc_content) 53 54 if __name__ == "__main__": 55 main()
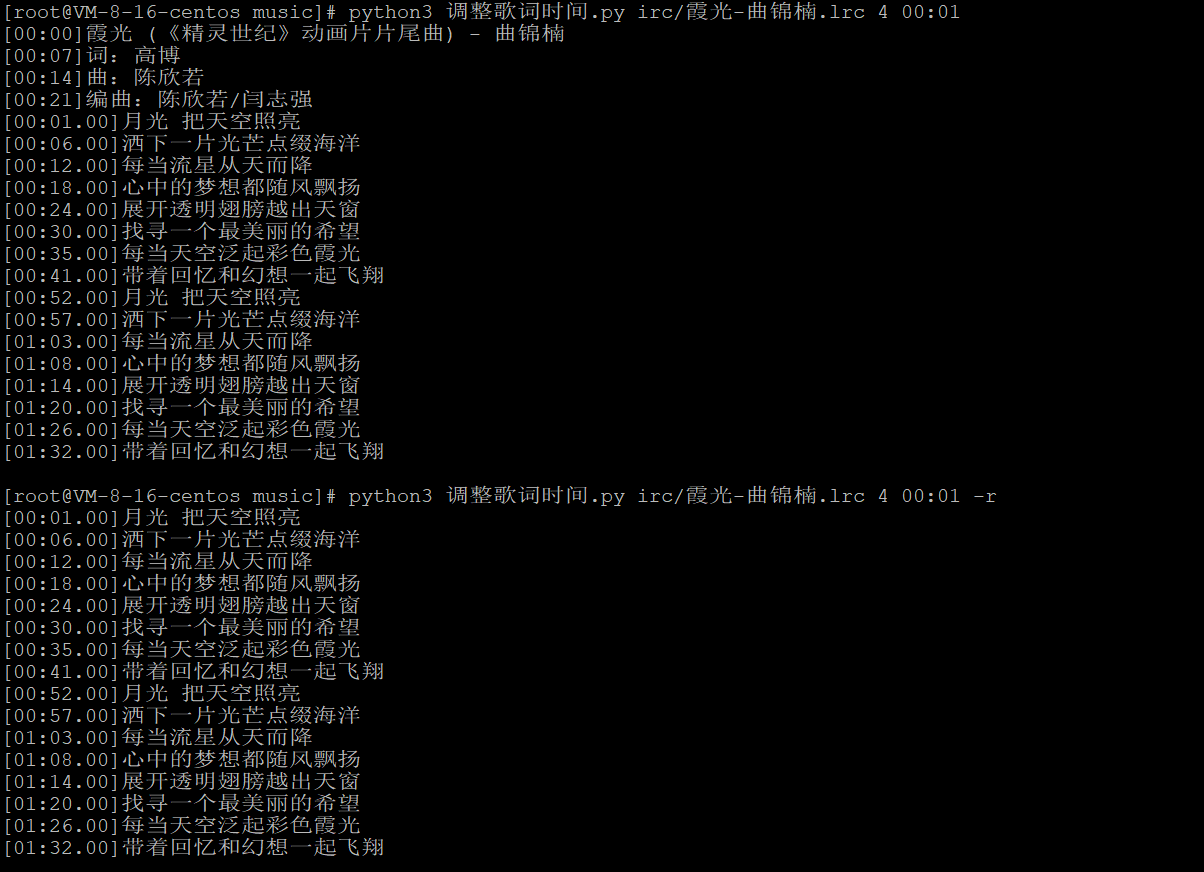
脚本的参数:歌词文件路径、起始调整行索引、调整后的时间、是否移除起始调整行之前的数据
使用效果如下:
以下为2026.02.05优化后脚本
import re import argparse def adjust_lrc_from_starting_line(lrc_content, starting_line_index, new_starting_time, remove_pre_data=False): lines = lrc_content.split('\n') if starting_line_index < len(lines): # 编译正则表达式以匹配时间戳 time_stamp_pattern = re.compile(r"^\[(\d+):(\d+(\.\d+)?)\s*\]") # 查找起始行 计算时间差 start_match = time_stamp_pattern.search(lines[starting_line_index]) if start_match: start_minutes, start_seconds_str = start_match.groups()[:2] start_seconds = float(start_seconds_str) if '.' in start_seconds_str else float(start_seconds_str) + 0.00 # 确保秒数有小数部分 new_minutes, new_seconds = map(float, new_starting_time.split(':')) time_difference = (new_minutes * 60 + new_seconds) - (float(start_minutes) * 60 + start_seconds) # 更新后续行的时间戳 for i in range(starting_line_index, len(lines)): match = time_stamp_pattern.search(lines[i]) if match: minutes, seconds = match.groups()[:2] total_seconds = float(minutes) * 60 + float(seconds) adjusted_seconds = total_seconds + time_difference adjusted_minutes, adjusted_seconds = divmod(adjusted_seconds, 60) adjusted_time_str = f"[{adjusted_minutes:02.0f}:{adjusted_seconds:05.2f}]" # 只替换时间戳部分,而不是整行 prefix, content = lines[i].split(']', 1) lines[i] = adjusted_time_str + content # 在处理完所有行后,根据remove_pre_data的值决定是否移除起始行之前的数据 if remove_pre_data: lines = lines[starting_line_index:] return '\n'.join(lines) def get_input_with_validation(prompt, validation_func=None, error_message=None): """获取用户输入,可选验证""" while True: try: value = input(prompt) if validation_func: value = validation_func(value) return value except Exception as e: if error_message: print(f"错误: {error_message}") else: print(f"输入无效,请重新输入。错误: {e}") def validate_line_number(value, max_line): """验证行号是否在 1 到 max_line 之间,返回 1-based 行号""" try: num = int(value) except (ValueError, TypeError): raise ValueError("不是有效整数") if num < 1 or num > max_line: raise ValueError(f"行号必须在 1 到 {max_line} 之间") return num # 返回 1-based 行号 def validate_time_format(value): """验证时间格式 mm:ss.xx""" if not re.match(r'^\d+:\d+(\.\d+)?$', value): raise ValueError("时间格式应为 'mm:ss.xx',例如 '01:23.45'") parts = value.split(':') minutes = int(parts[0]) seconds = float(parts[1]) if minutes < 0: raise ValueError("分钟数不能为负数") if seconds < 0 or seconds >= 60: raise ValueError("秒数必须在 0 到 59.99 之间") return value def main(): # 1. 文件路径 parser = argparse.ArgumentParser(description="Adjust LRC timestamps from a specified line.") parser.add_argument("lrc_file", help="Path to the LRC file to process.") parser.add_argument("--remove-pre-data", "-r", action="store_true", help="Remove data before the starting line index.", default=False) args = parser.parse_args() with open(args.lrc_file, 'r', encoding='utf-8') as file: lrc_content = file.read() lines = lrc_content.split('\n') total_lines = len(lines) # 2. 起始行号 (1-based) starting_line = get_input_with_validation( prompt=f"\n请输入起始行号 (1-{total_lines}): ", validation_func=lambda x: validate_line_number(x, total_lines), error_message=f"请输入 1 到 {total_lines} 之间的整数" ) starting_line_index = starting_line - 1 # 转为 0-based 索引 # 3. 新的起始时间 new_starting_time = get_input_with_validation( "\n请输入新的起始时间 (格式: mm:ss.xx): ", validate_time_format, "时间格式应为 'mm:ss.xx',例如 '01:23.45'" ) new_lrc_content = adjust_lrc_from_starting_line(lrc_content, starting_line_index, new_starting_time, args.remove_pre_data) print(new_lrc_content) if __name__ == "__main__": main()
效果如下


 浙公网安备 33010602011771号
浙公网安备 33010602011771号