Apache Kylin快速入门并结合zeppelin做可视化展示
Kylin简介
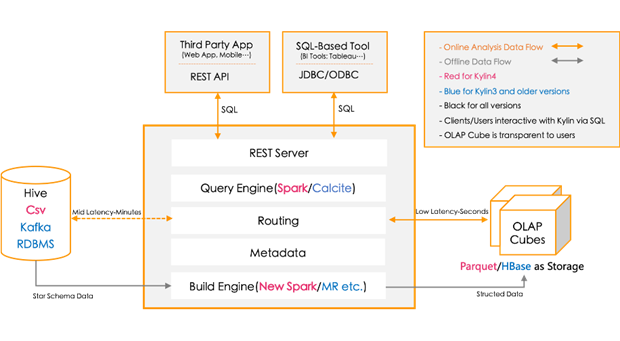
Apache Kylin™是一个开源的、分布式的分析型数据仓库,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献至开源社区。它能在亚秒内查询巨大的表。
Apache Kylin™ 令使用者仅需三步,即可实现超大数据集上的亚秒级查询。
- 定义数据集上的一个星形或雪花形模型
- 在定义的数据表上构建cube
- 使用标准 SQL 通过 ODBC、JDBC 或 RESTFUL API 进行查询,仅需亚秒级响应时间即可获得查询结果
Kylin 提供与多种数据可视化工具的整合能力,如 Tableau,PowerBI 等,令用户可以使用 BI 工具对 Hadoop 数据进行分析。
样例 Cube 快速入门样例 Cube 快速入门
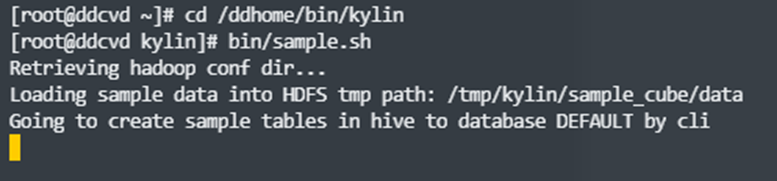
Kylin 提供了一个创建样例 Cube 脚本;脚本会创建五个样例 hive 表:
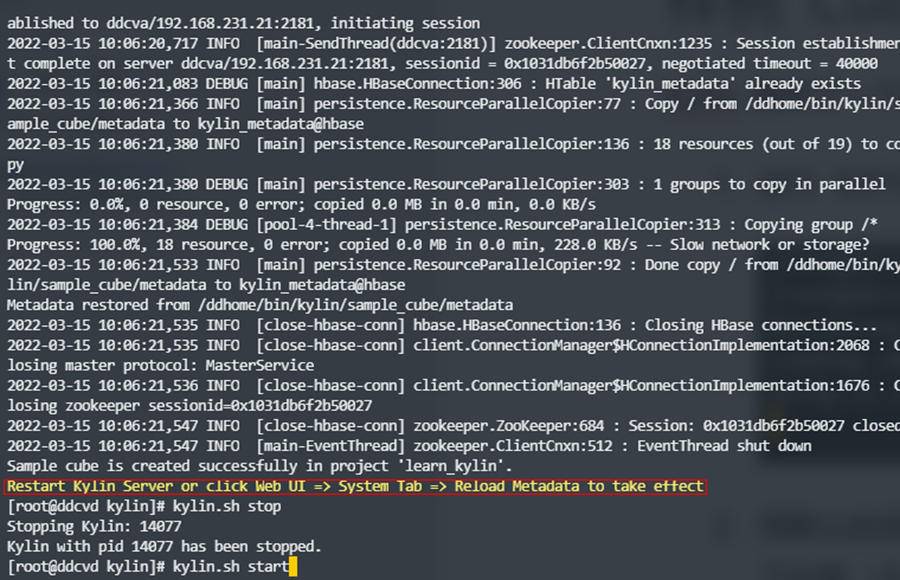
- 运行 ${KYLIN_HOME}/bin/sample.sh ;重启 kylin 服务器刷新缓存;
- 用默认的用户名和密码 ADMIN/KYLIN 登陆 Kylin 网站,选择 project 下拉框(左上角)中的 “learn_kylin” 工程;
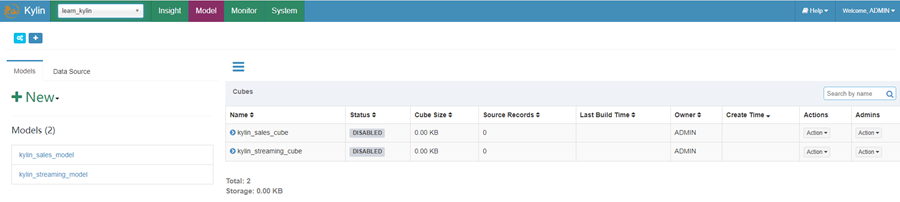
- 选择名为 “kylin_sales_cube” 的样例 cube,点击 “Actions” -> “Build”,选择一个在 2014-01-01 之后的日期(覆盖所有的 10000 样例记录);
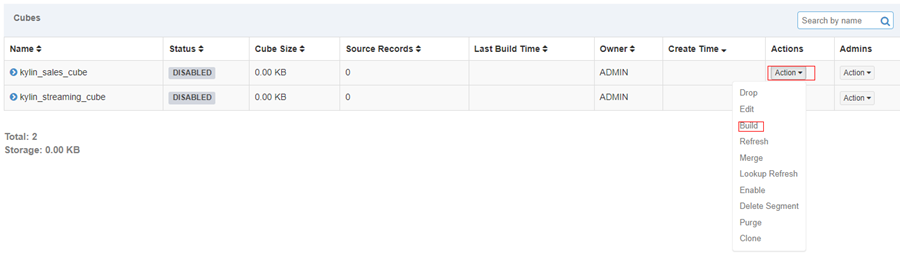
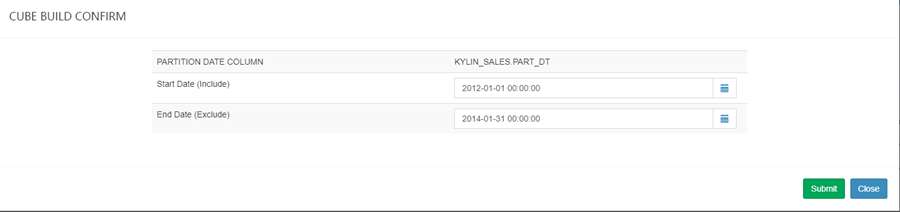
-
点击 “Monitor” 标签,查看 build 进度直至 100%;
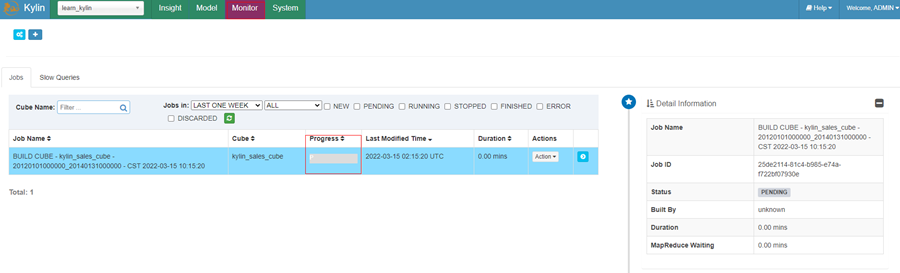
-
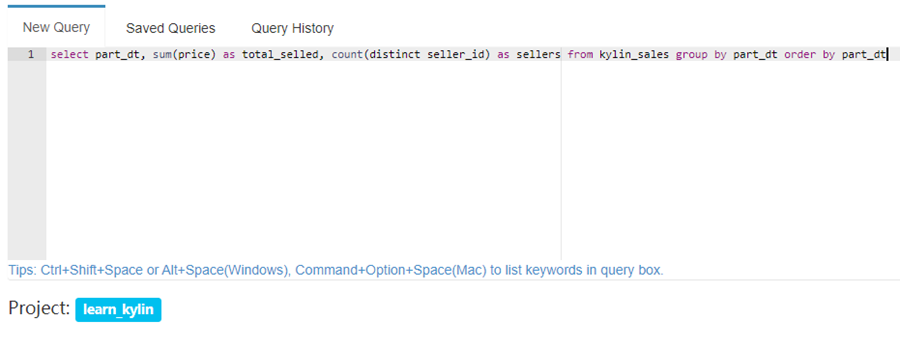
点击 “Insight” 标签,执行 SQLs,例如:
select part_dt, sum(price) as total_selled, count(distinct seller_id) as sellers from kylin_sales group by part_dt order by part_dt
Streaming 样例 Cube 快速入门
Kylin 也提供了 streaming 样例 cube 脚本。该脚本将会创建 Kafka topic 且不断的向生成的 topic 发送随机 messages。
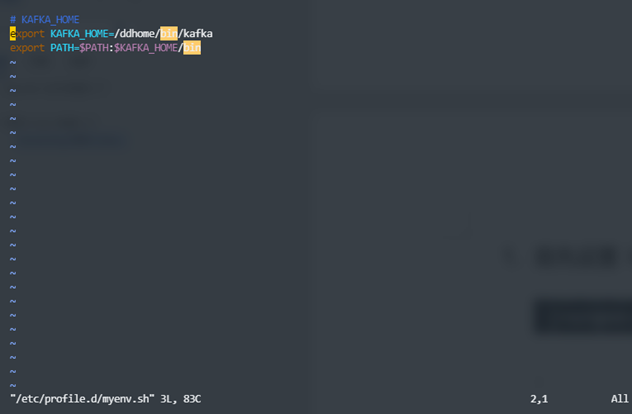
- 首先设置 KAFKA_HOME,然后启动 Kylin。

-
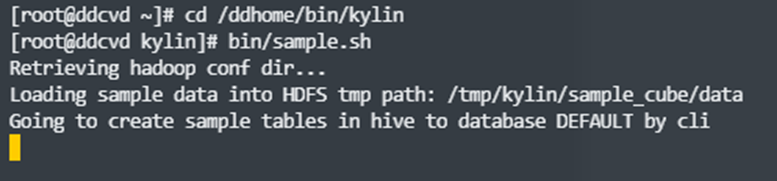
运行 ${KYLIN_HOME}/bin/sample.sh,它会在 learn_kylin 工程中生成 DEFAULT.KYLIN_STREAMING_TABLE 表,kylin_streaming_model 模型,Cube kylin_streaming_cube。
-
运行 ${KYLIN_HOME}/bin/sample-streaming.sh,它会在 localhost:9092 broker 中创建名为 kylin_streaming_topic 的 Kafka Topic。它也会每秒随机发送 100 条 messages 到 kylin_streaming_topic。+

-
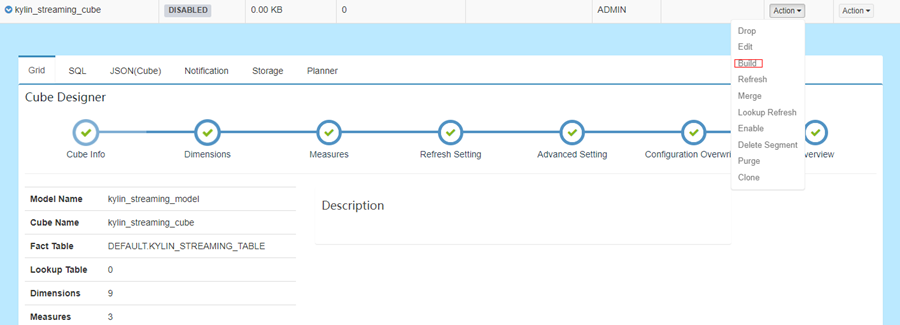
遵循标准 cube build 过程,并触发 Cube kylin_streaming_cube build。
-
点击 “Monitor” 标签,查看 build 进度直至至少有一个 job 达到 100%。
-
点击 “Insight” 标签,执行 SQLs,例如:
点击查看代码
- 验证查询结果。
Kylin简单例子演示
官方的案例虽然只有几张表,但是对于初学者来说还是有点复杂,接下来我将演示一个简单易懂的例子
首先我们需要创建两张表,并将一些数据载入进去(两张表已经创建完成,可以直接载入)
点击data source 再点击load table按钮
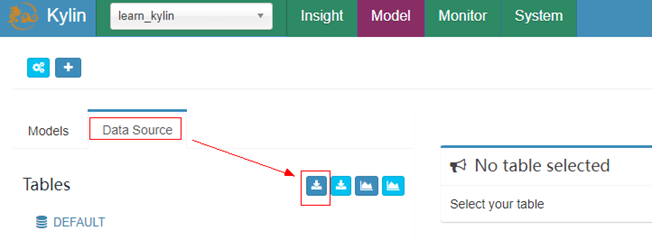
添加emp、dept两张表

我们来看一下这两张表的字段吧
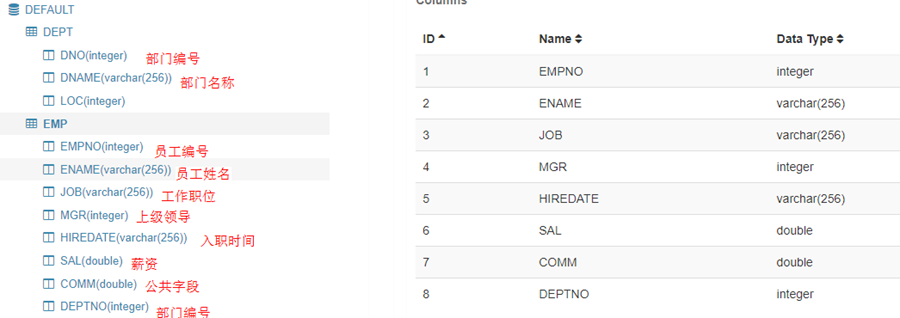
需求:求出各个部门的薪资总和
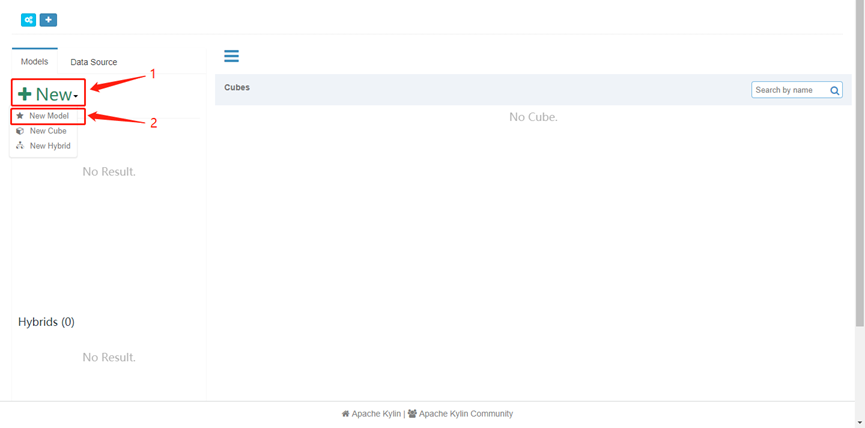
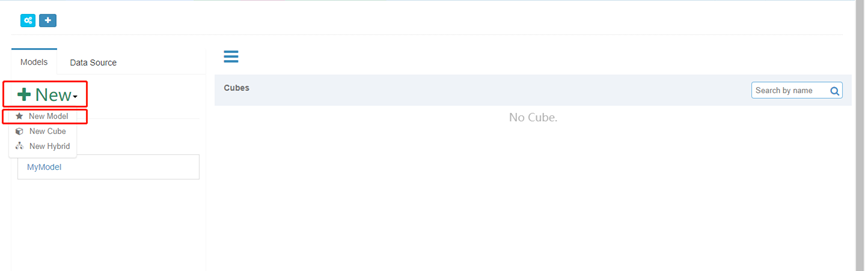
1. 首先新建一个model
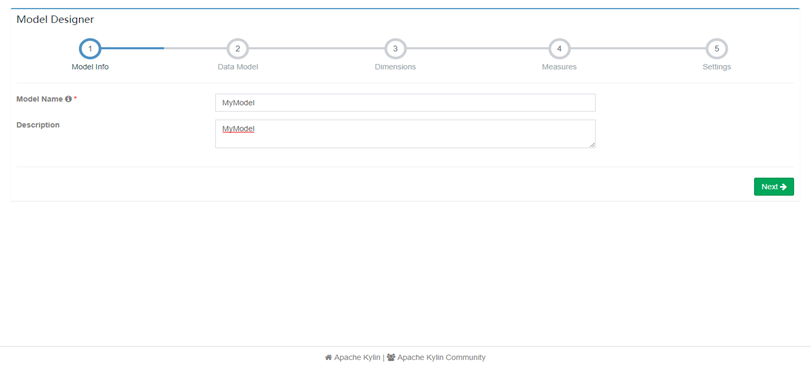
2. 填写Model名称及描述后Next
3. 选择事实表
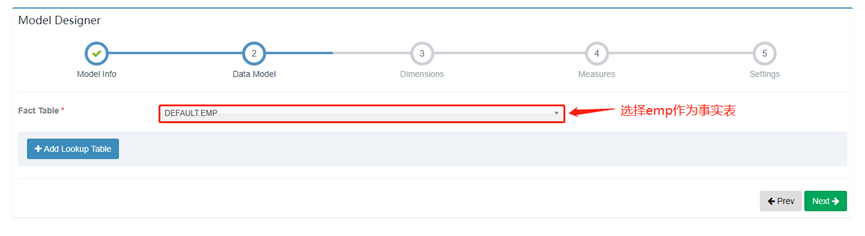
4. 添加维度表
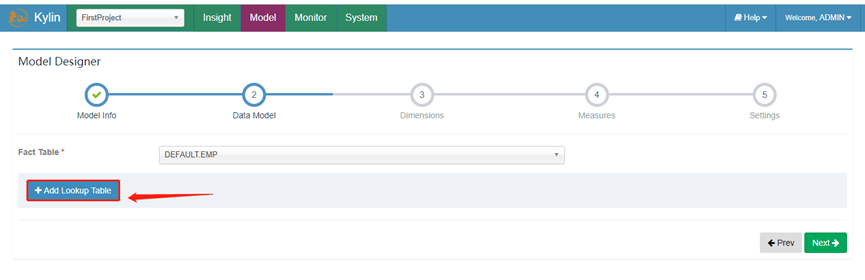
5. 选择inner join
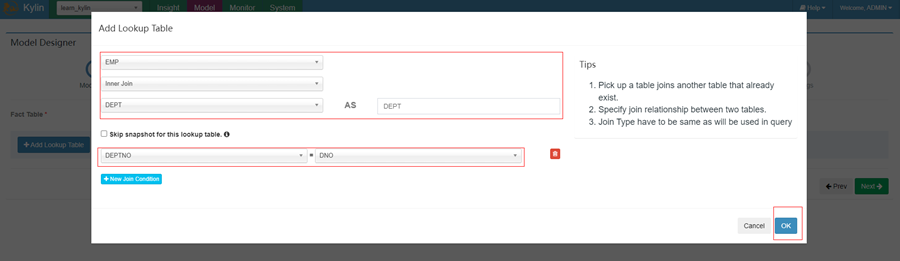
6. 选择需要的查询的字段
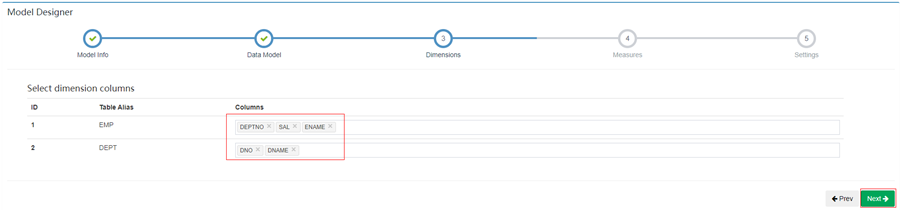
7. 选择需要统计的字段
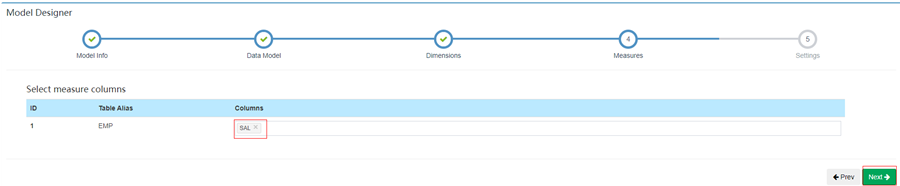
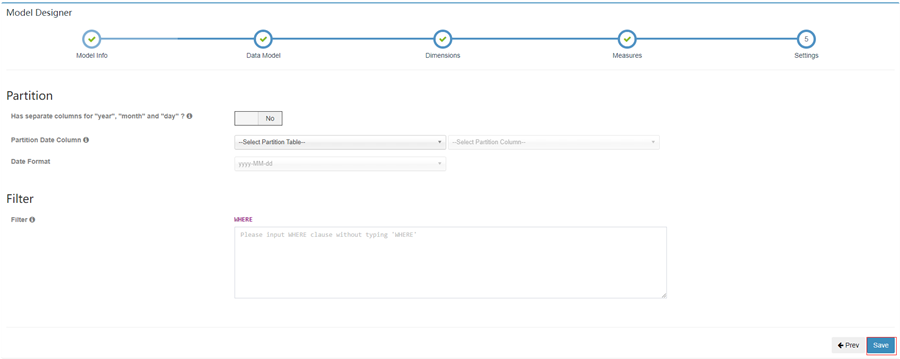
8. 最后一步分区这块不需要修改
9. 构建cube
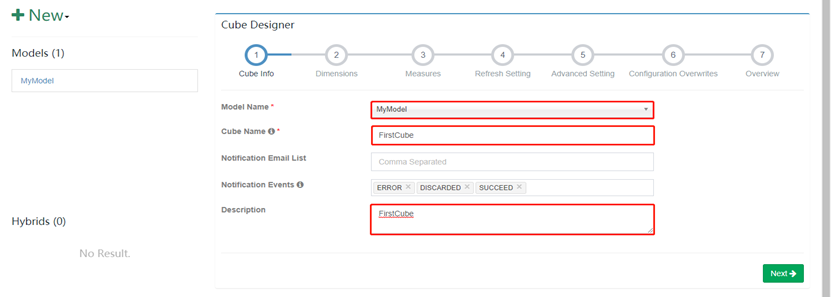
10. 选择Model及填写Cube Name
11. 添加维度
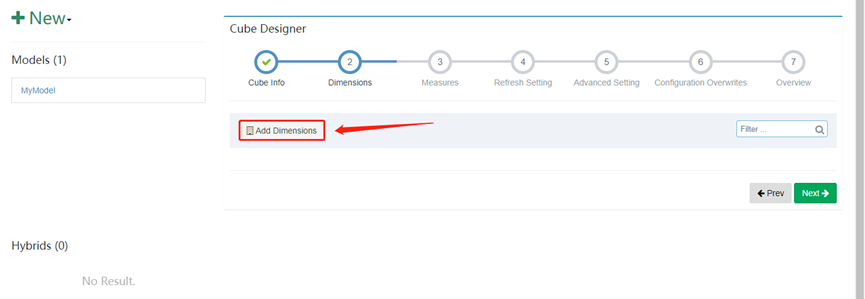
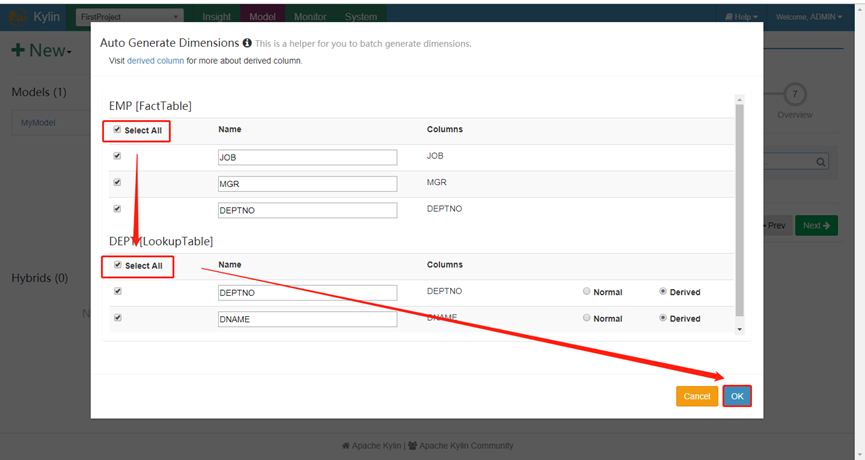
12. 添加需要预计算的内容
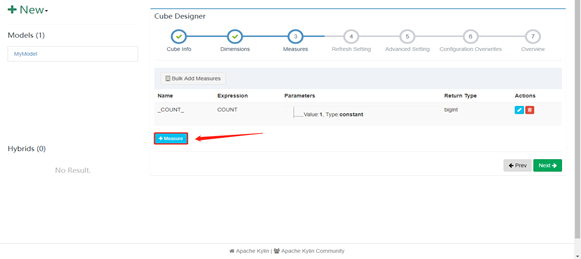
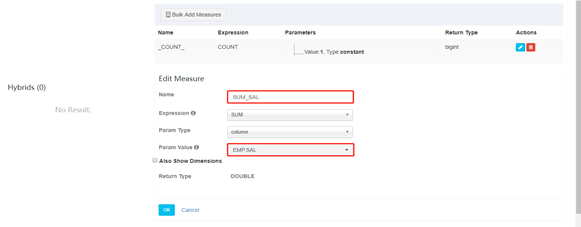
13. 接下来的配置全部选择next,最后点击save
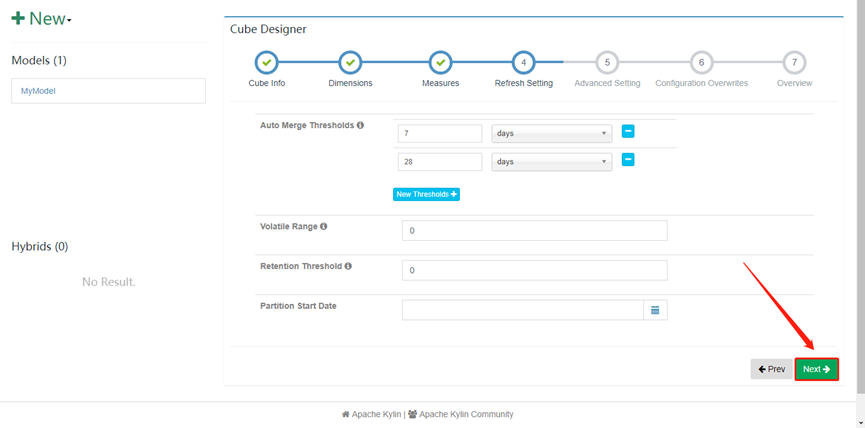
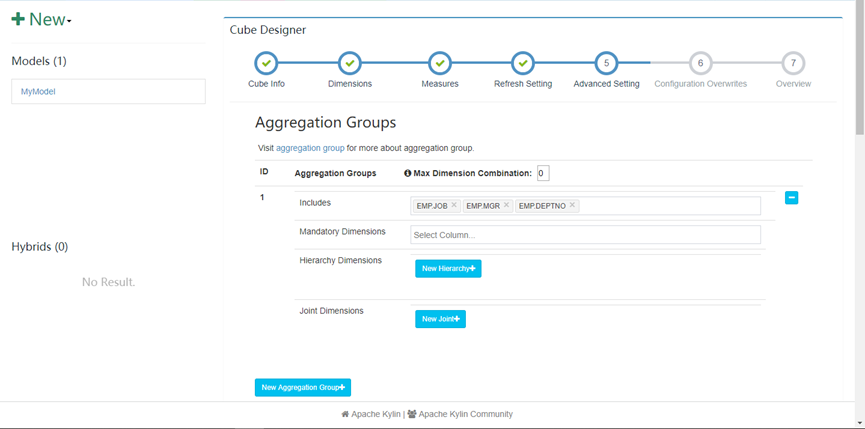
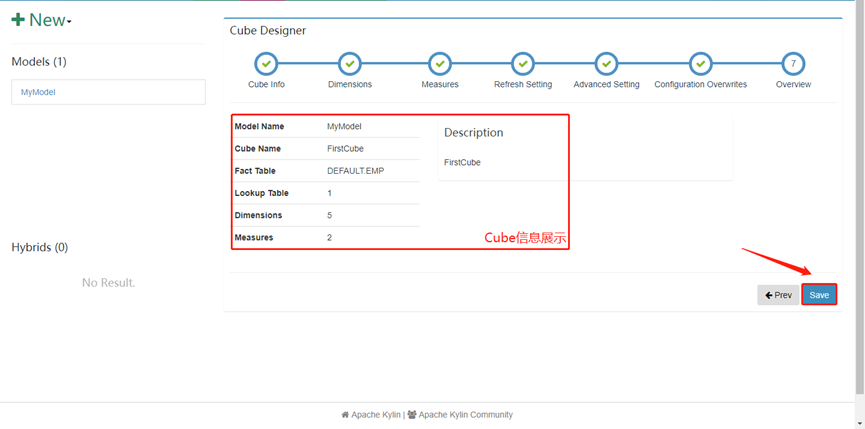
14. Cube配置完成,开始build
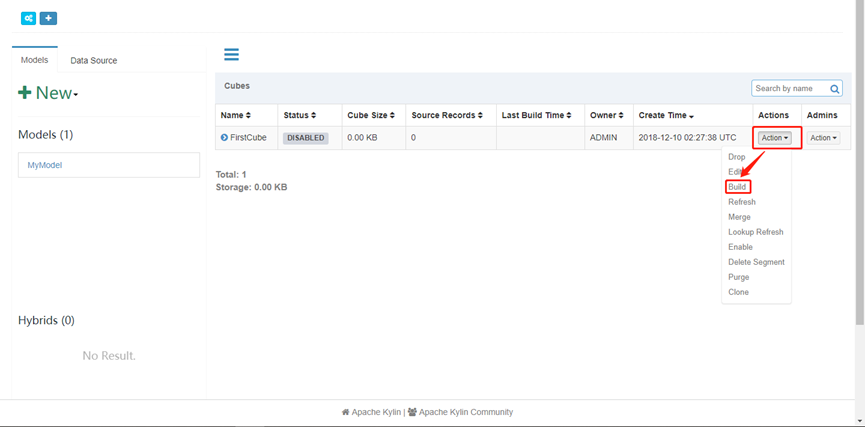
15. 查看build进度(第一次build可能会有点慢)
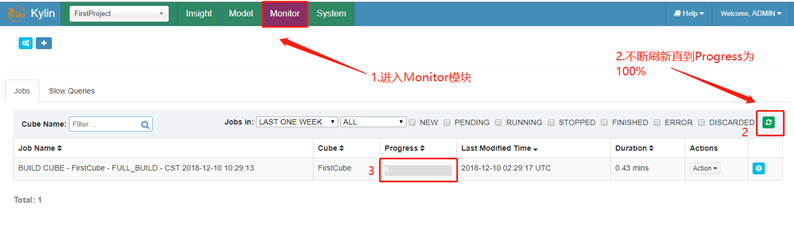
Build中的操作简单概括:创建hive临时表,用于将事实表数据暂时存储,然后根据model进行join操作,维度的多少影响cube build完成的时间,最后的数据都将在hive的临时表上,将这张表导出成Hfile(写入HBASE的文件类型),将Hfile导入HBASE,HBASE按照文件载入预计算结果,清理hive中的临时表,最后将结果落盘到hdfs。
16. 现在去完成我们的需求
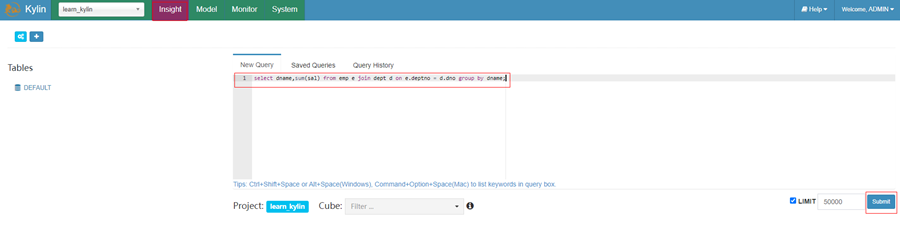
输入sql:select dname,sum(sal) from emp e join dept d on e.deptno = d.deptno group by dname;
就可以得出各个部门的薪资总和了
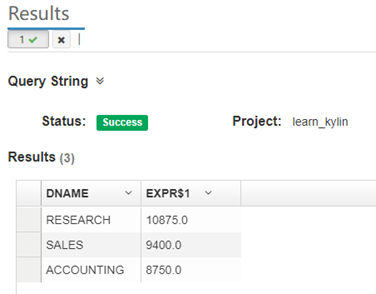
Zeppelin结合kylin演示
1. 进入zeppelin页面
2. 配置Zeppelin支持Kylin
搜索kylin插件
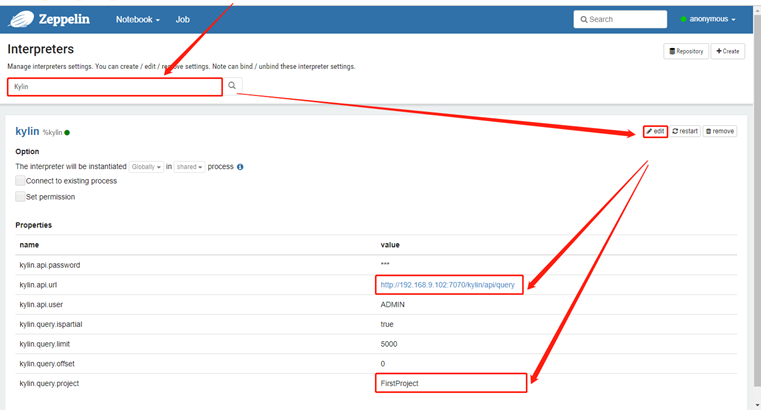
修改完成点击Save完成(这里按照实际情况填写)
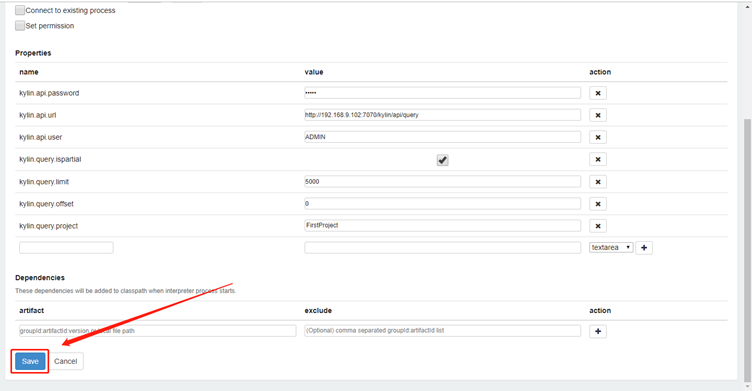
3. 案例实操
需求:查询员工的详细信息,并可视化展示
1)点击Notebook创建新的note
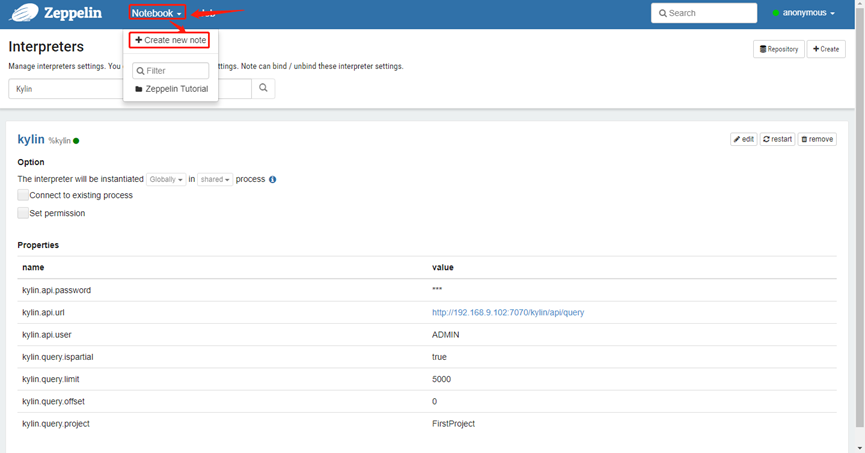
2) 填写Note Name点击Create
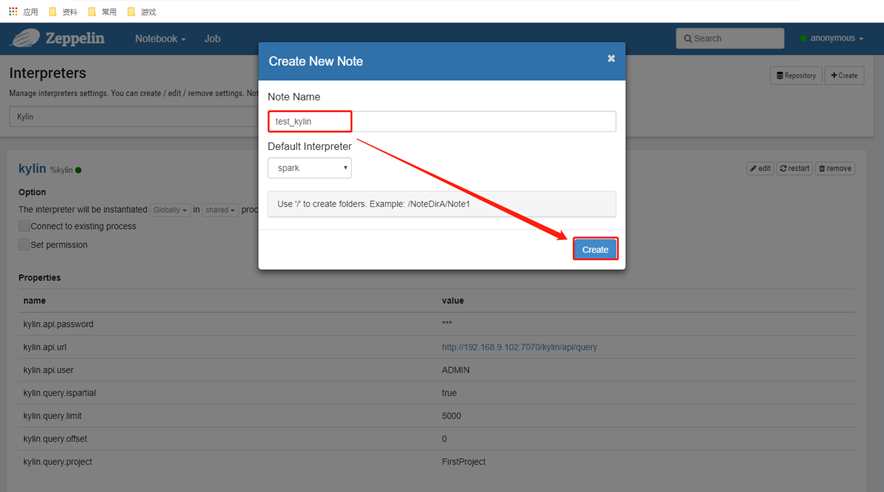
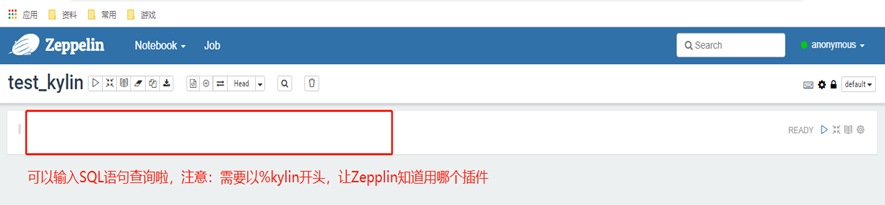
3)执行查询

4)结果展示
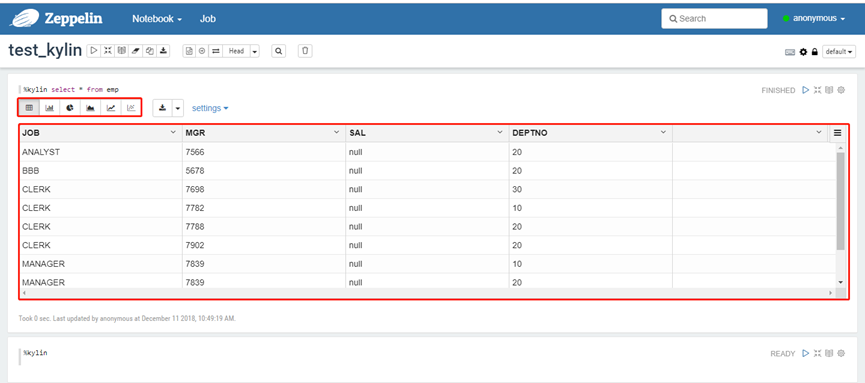
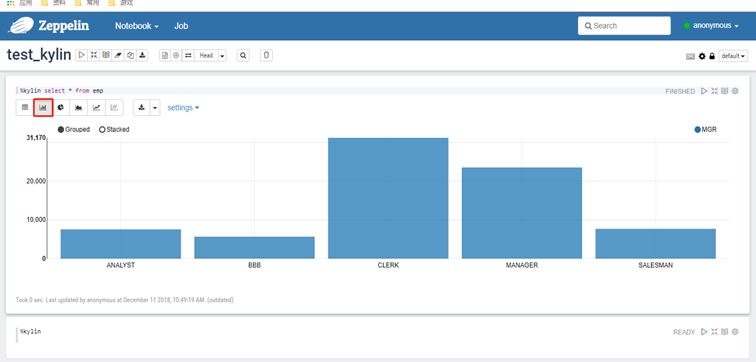
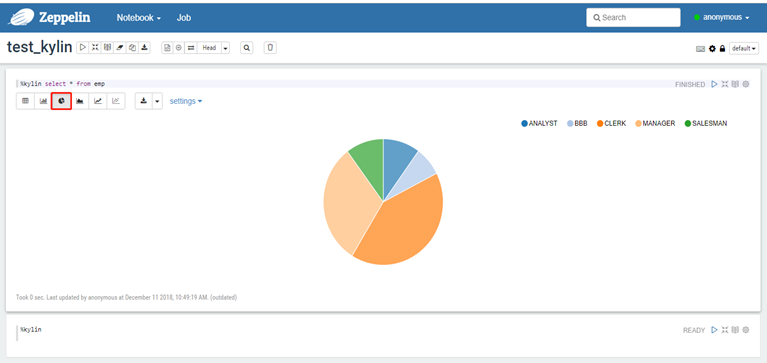
5)其他图表格式
__EOF__

本文链接:https://www.cnblogs.com/xiaolongbaoxiangfei/p/16135485.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通