文献阅读笔记-3D-LaneNet+: Anchor Free Lane Detection using a Semi-Local Representation
3D-LaneNet+: Anchor Free Lane Detection using a Semi-Local Representation
3D-LaneNet+:使用半局部表示的无锚车道检测
Abstract
3D-LaneNet+ 是一种基于摄像头的 DNN 方法,用于无锚定 3D 车道检测,能够检测任意拓扑的 3D 车道,例如分割、合并,以及短车道和垂直车道。我们遵循最近提出的 3D-LaneNet,并对其进行扩展,以检测这些以前不受支持的车道拓扑。我们的输出表示是一种无锚、半本地瓦片表示,它将车道分解成简单的车道段,其参数可以学习。此外,我们学习,每个车道实例,特征嵌入是局部检测到的分段的全局连通性的原因,以形成完整的 3d 车道。这种组合允许 3D-LaneNet+ 避免使用原始 3D-LaneNet 中的车道锚、非最大抑制和车道模型拟合。我们使用合成数据和真实世界数据展示了 3D-LaneNet+ 的功效。结果显示,相对于原始 3D-LaneNet 有显着改进,这可归因于对复杂车道拓扑、曲率和表面几何形状的更好概括。
1 Introduction
基于摄像头的 3D 车道检测是许多自动驾驶相关任务的重要组成部分,例如轨迹规划、车辆定位和地图生成等等。
最近,加内特等人。 [3] 提出了 3D-LaneNet,一种基于摄像头的 3D 车道检测方法,它提出了两个用于车道检测的新概念。第一个是具有集成逆透视映射 (IPM) 的 CNN 架构,用于将特征图投影到鸟瞰图 (BEV),第二个是基于锚点的表示,它允许将车道检测问题转换为单阶段目标检测问题。遵循与 SSD [14] 或 RetinaNet [13] 中类似的概念,每个 BEV 列都用作将整个车道回归为折线的锚点。这对检测到的车道几何形状和拓扑施加了强大的约束,从而限制了该方法检测与自我车辆行驶方向不大致平行的车道的能力。更靠前的车道,以及其他重要的非平凡拓扑(例如路口)无法表示,因此此方法无法检测到。
在这项工作中,我们遵循最近提出的无锚检测器,如 FCOS [17] 和 CenterNet [23],并建议对 3D-LaneNet 进行无锚扩展,我们称之为 3D-LaneNet+。与 3D-LaneNet 使用基于列的锚来封装有关车道结构(长且连续)的先验信息不同,无锚检测器不引入此类先验。他们的基本范式是将输入划分为非重叠单元,其中每个单元学习检测占据该单元的对象并估计对象的属性(例如中心、尺寸、方向)。然而,车道不是具有容易定义中心的紧凑对象。因此,我们不是预测整个车道,而是检测位于单元格内的小车道段及其属性(位置、方向、高度)。此外,我们为每个单元学习了一个全局嵌入,该嵌入允许将小车道段聚集在一起形成完整的 3D 车道。我们建议的解决方案减轻了所有车道都应表示为折线的假设。这可以检测任意拓扑的车道,包括分割、合并、短车道和垂直于车辆行驶方向的车道。支持这些额外的车道拓扑可以提高 3D-LaneNet+ 的检测召回率,从而相对于原始 3D-LaneNet 带来显着的性能提升。
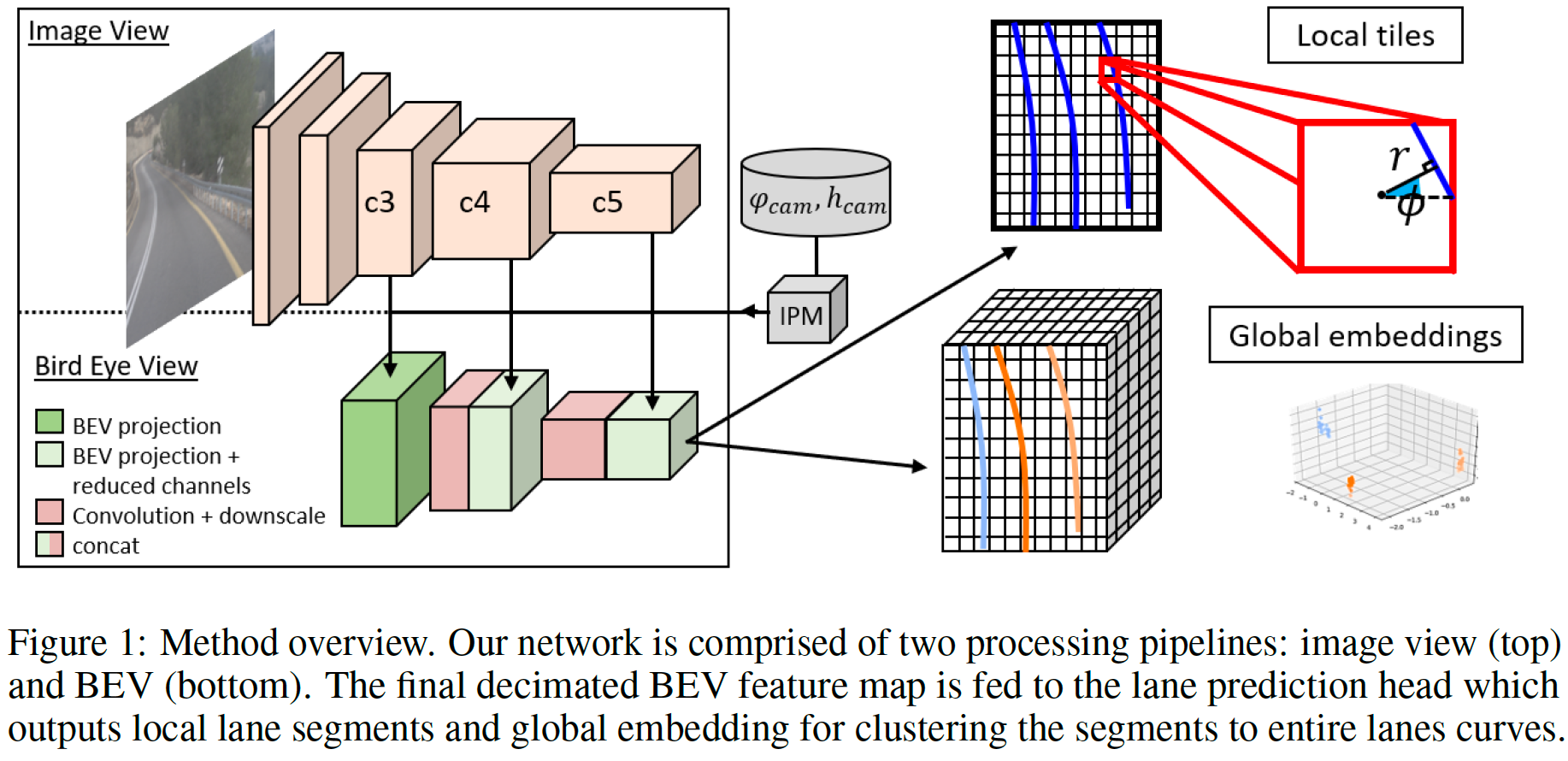
我们的无锚表示可以被认为是紧凑的半局部表示,它能够捕捉局部拓扑—不变的车道结构和路面几何形状。车道检测是在鸟瞰图中使用非重叠粗瓷砖网格完成的,如图 1 所示。我们假设穿过瓷砖的车道段很简单,可以用低维参数模型表示。具体来说,每个瓦片都包含一条线段,该线段由距瓦片中心的偏移量、方向和距 BEV 平面的高度偏移量参数化。这种半局部瓦片表示位于全局表示(整个车道)与局部表示(像素级)之间的连续统一体上。每个图块输出比基于分割的解决方案中的单个像素提供更多信息,因为它能够对局部车道结构进行推理,但它不像基于全局锚的解决方案那样受限,后者必须一起捕获整个车道拓扑的复杂性,曲率和表面几何。
我们使用合成数据集和真实世界数据集进行实验,结果表明 3D-LaneNet+ 大幅提高了 3D-LaneNet 的平均精度 (MAP)。我们定性和定量地证明了我们的表示的有效性及其对新车道曲率和表面几何形状的推广。
2 Related work
2D车道检测 大多数现有的车道检测方法都集中在图像平面上的车道检测,并且大多局限于检测与车辆行驶方向平行的车道。文献非常丰富,包括通过使用自我注意 [9]、使用 GANs [5]、使用新的卷积层 [19]、利用消失点来指导训练 [12] 或使用可微分最小来执行 2D 车道检测的方法正方形拟合 [18]。与我们最相关的是 [10] 的方法,该方法在图像平面中使用基于网格的表示,具有用于高速公路车道检测的线参数化和基于密度的空间聚类。我们的方法在 BEV 角度执行 3D 车道检测,以及基于学习的聚类以及与 [10] 不同的参数化。与我们相关的另一项工作是 [16],它使用学习嵌入来执行车道聚类。虽然 [16] 在图像像素级别执行分割,但我们在半局部瓦片尺度上对 BEV 中的车道段进行聚类,这在计算上要少得多。
3D 车道检测 在 3D 中检测车道是一项具有挑战性的任务,近年来越来越受到关注。一些方法使用 LiDAR 或相机和 LiDAR 组合来完成此任务。例如,白等人。 [1] 在 LiDAR 点上使用 CNN 来估计路面高度,然后将相机相应地重新投影到 BEV。该网络不会端到端地检测车道实例,而是输出需要进一步处理和聚类的密集检测概率图。与我们的工作更相关的是基于相机的方法。 DeepLanes [6] 使用 BEV 表示,但与仅检测车辆周围的车道而不提供高度信息的顶视摄像头一起使用。
最近,Gen-LaneNet [22] 建议使用与 3D-LaneNet [3] 中相同的基于列的锚表示,但改变了预测 3d 车道点的坐标系。尽管 Gen-LaneNet 的这种新的几何引导车道锚更适用于未观察到的场景,但它仍然仅限于与自我车辆行驶方向大致平行的长车道。我们提出的无锚表示是对这个新坐标系的补充,因此预计在 Gen-LaneNet 的上下文中也很有用(尽管在我们的工作中没有测试)。
无锚探测器 基于锚点的方法通过使用一组参数表示整个对象并将这些参数相对于预定义的锚点回归[14, 13],以一次性全局方式检测对象。在车道检测的上下文中,这个问题公式将车道限制为由折线以全局方式表示,这限制了可以预测的车道拓扑的多样性。最近的无锚检测工作减轻了对全局锚的需求,并实现了对象参数或对象的子部分参数的直接回归,就像我们的例子一样。这些方法包括 Corner Net [11],它将对象检测为与边界框角位置相对应的成对关键点,CenterNet [23] 和 FCOS [17],它预测对象的中心和尺寸。 AFDet [4] 是一种基于 LiDAR 的检测器,应用了类似的方法,并相对于常规顶视图网格预测对象的中心、方向和尺寸。 RepPoints [20] 和 Dense RepPoints [21] 通过预测代表对象的点集来检测对象,朝着更适合车道的非刚性对象表示迈出了一步。然而,它们预测相对于对象中心的点集,而车道没有明确定义的中心。在 3D-LaneNet+ 中,我们使用一组线段而不是点来表示车道,从而结合了车道线结构的信息,并且我们不是预测相对于全局车道中心的线段,而是相对于网格单元中心预测它们.为了推理片段的连通性,我们还学习了 [16] 中的实例嵌入。
3 Method
我们现在描述我们提出的 3D 车道检测框架 3D-LaneNet+。示意图如图 1 所示。我们首先介绍半局部瓦片表示和车道段参数化(第 3.1 节),然后介绍如何使用学习嵌入将车道段聚集在一起(第 3.2 节)。
3.1 Learning 3D lane segments with Semi-local tile representation 使用半局部瓦片表示学习 3D 车道段
车道曲线具有许多不同的全局拓扑结构,并且位于具有复杂几何形状的路面上。这使得推理整个 3D 车道曲线成为一项具有挑战性的任务。我们的主要观察结果是,尽管存在这种全局复杂性,但在局部层面上,车道段可以用低维参数模型表示。利用这一观察,我们提出了一种半局部表示,它允许我们的网络学习局部车道段,从而很好地推广到看不见的车道拓扑、曲率和表面几何形状。
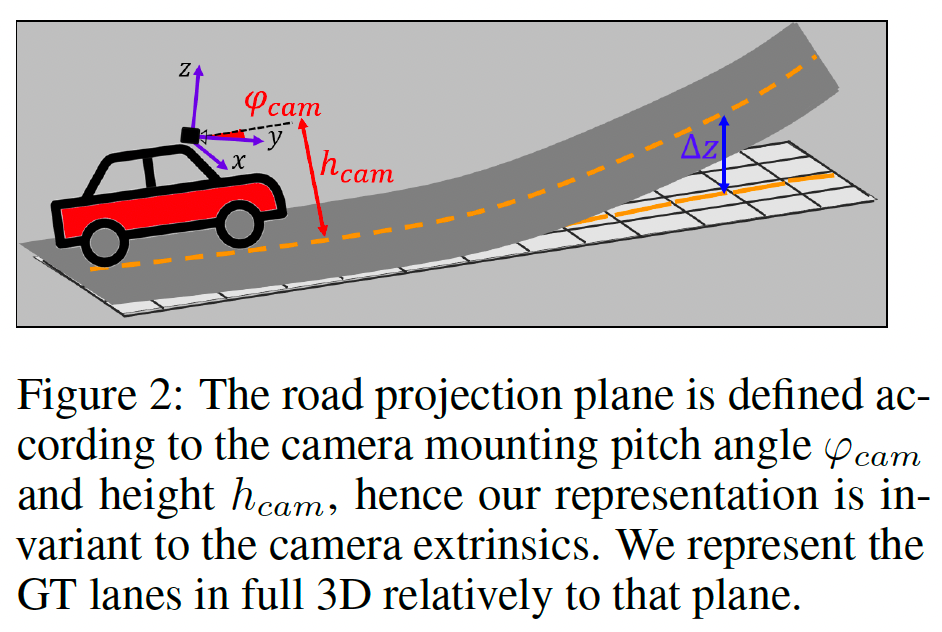
继加内特等人之后。 [3],我们的网络被给定一个相机图像,该图像被馈送到双通路主干,该主干使用编码器和逆透视映射 (IPM) 模块将特征图投影到 BEV。投影应用由摄像机俯仰角 \(φ _{cam}\) 和高度 \(h _{cam}\) 定义的单应性,将图像平面映射到道路平面(见图 2)。最终抽取的 BEV 特征图在空间上划分为由 \(W × H\) 非重叠图块组成的网格 \(G _{W × H}\)。该投影确保 BEV 特征图中的每个像素对应于道路上的预定义位置,独立于相机内在函数和姿势。
我们假设通过每个图块(tile) \(g _{ij} \in G _{W×H}\) 可以通过一条可以近似为直线的线段。具体来说,网络对每个图块 \(g _{ij}\) 回归三个参数:相对于图块中心的横向偏移距离 \(\tilde{r} _{ij}\) ,线角 \(\tilde{\phi} _{ij}\) ,(参见图 1 中的局部图块)和高度偏移 \(\widetilde{\Delta z} _{ij}\) (参见图 2) .除了这些线参数之外,网络还预测二进制分类分数 \(\tilde{c} _{ij}\) ,指示车道与特定图块相交的概率。
使用 L1 损失训练位置和 z 偏移:$$\mathcal{L} ^{Offsets} _{ij} = ‖\tilde{r} _{ij} − r _{ij} ‖ _1 + ‖ \widetilde{\Delta z} _{ij} − \Delta z _{ij} ‖ _1 \tag{1}$$
预测线角 \(\tilde{\phi} _{ij}\) 是使用 [15] 的混合分类 - 回归框架完成的,在该框架中,我们将角度 \(\phi\)(为简洁起见省略平铺索引)分类为 \(N _α\) 个 bin 之一,以 \(α = \{ \frac{2π} {N _α} · i \} ^{Nα} _{i=1}\) 为中心。此外,我们回归一个向量 \(\rm{Δ} ^α\),对应于相对于每个 bin 中心的残差偏移。我们的角度箱估计使用软多标签目标进行了优化,GT 概率计算为 \(p ^α = [1 - | \frac{2π} {N _α} · i − φ|/ \frac{2π} {N _α} ] _+\) 。
角度损失是分类和偏移回归损失的总和:$$\mathcal{L} ^{angle} _{ij} = \sum ^{N_α} _{α=1} [ p ^α _{ij} · \log \tilde{p} ^α _{ij} + (1 −p ^α _{ij}) · \log (1 −\tilde{p} ^α _{ij} ) + δ^α _{ij} · ‖ \tilde{∆}^α _{ij} − ∆^α _{ij} ‖ _1] \tag{2}$$其中 \(δ^α _{ij}\) 是为偏移学习掩蔽相关 bin 的指示函数。
车道平铺概率 \(\tilde{c} _{ij}\) 使用二元交叉熵损失进行训练:$$\mathcal{L} ^{score} _{ij} = c _{ij} · \log \tilde{c} _{ij} + (1 − c _{ij}) · \log(1- \tilde{c} _{ij}) \tag{3}$$
最后,整体图块(tile)损失是 BEV 网格中所有图块(tile)的总和:$$mathcal{L} ^{tiles} = \sum _{i,j \in W×H} (\mathcal{L} ^{score} _{ij} + c _{ij} · \mathcal{L} ^{angle} _{ij} + c _{ij} · \mathcal{L} ^{Offsets} _{ij}) \tag{4}$$
在推理时,我们通过将偏移量 \((\tilde{r} _{ij} ,\widetilde{\Delta z} _{ij})\) 和角度 \(\tilde{\phi} _{ij}\) 从极坐标转换为笛卡尔坐标,将它们转换回点,并通过减去 \(h _{cam}\) 和旋转将点从 BEV 平面转换到相机坐标系通过 \(-\varphi _{cam}\)(图2)。
3.2 Global embedding for lane curve clustering 车道曲线聚类的全局嵌入
一旦获得车道图块(tiles),我们仍然承担从这些小段中产生完整的3D车道曲线的任务。为此,我们建议使用基于学习的功能嵌入的聚类方法。该技术消除了在原始3D LANENET中使用车道锚和多线拟合的需求,这又允许 3D-LaneNet+ 支持以前不支持的车道,例如垂直于旅行的自我车辆方向和短路,该车道在距车辆很长一段距离。
具体而言,我们学习了每个图块(tile)的嵌入向量 \(f _{ij}\) ,以便代表同一车道的图块(tile)的向量将位于嵌入式空间中,而代表不同车道的图块(tile)的矢量将位于较远的位置。为此,我们采用了[16,2]的方法,并使用了 discriminative push-pull loss 。与以前的工作不同,我们在删除的图块(tile)网格上使用判别性损失,这比在像素级别上操作要有效得多。
discriminative push-pull loss 是两种损失的组合:$$\mathcal{L} ^{embedding} = \mathcal{L} ^{pull} + \mathcal{L} ^{push} \tag{5}$$旨在将同一车道图块(tile)的嵌入更加靠近的 pull loss :$$\mathcal{L} ^{pull} = \frac{1}{C} \sum ^C _{c=1} \frac{1}{N _c} \sum _{ij \in W×H } [δ ^c _{ij} · ‖μ _c − f _{ij}‖ − ∆pull] ^2 _+ \tag{6}$$以及旨在将属于不同车道的瓷砖嵌入的 push loss :$$\mathcal{L} ^{push} = \frac{1}{C(C − 1)} \sum ^C _{c _A =1} \sum ^C _{c _B=1,c _B \neq c _A} [∆ _{push} − ‖ μ _{c _A} − μ _{c _B} ‖] ^2 _+$$
其中 C 是车道的数量(可以变化),\(N_c\) 是属于车道 C 的图块的数量,\(δ ^c _{ij}\) 表示图块(tile) \(i,j\) 是否属于车道 c ,\(μ _c = \frac{1}{Nc} \sum _{ij \in W×H}δ ^c _{ij} · f _{ij}\) 是属于车道 C 的 \(f _{ij}\) 的平均值,\(∆ _{pull}\) 约束最大的集群内距离,并且 \(∆ _{push}\) 是集群间最小所需的距离。
鉴于学习的功能嵌入,我们可以使用简单的聚类算法来提取属于单个车道的图块。我们采用了Neven等人[16]的聚类方法。 使用均值移位来找到簇中心并在每个中心设置一个阈值以获取群集成员。我们将阈值设置为 \(\frac{∆ _{push}}{2}\) 。
4 Experimental Setup
我们使用两个 3D 车道数据集研究了 3D-LaneNet+ 的性能,并将其与Garnett等人的原始 3D-LaneNet 进行了比较。我们展示了我们的无锚方法在检测远离宿主车辆的短车道和车道方面的优势,这些车道和车道表明了检测不同车道拓扑并推广到复杂表面几何形状的方法的能力。
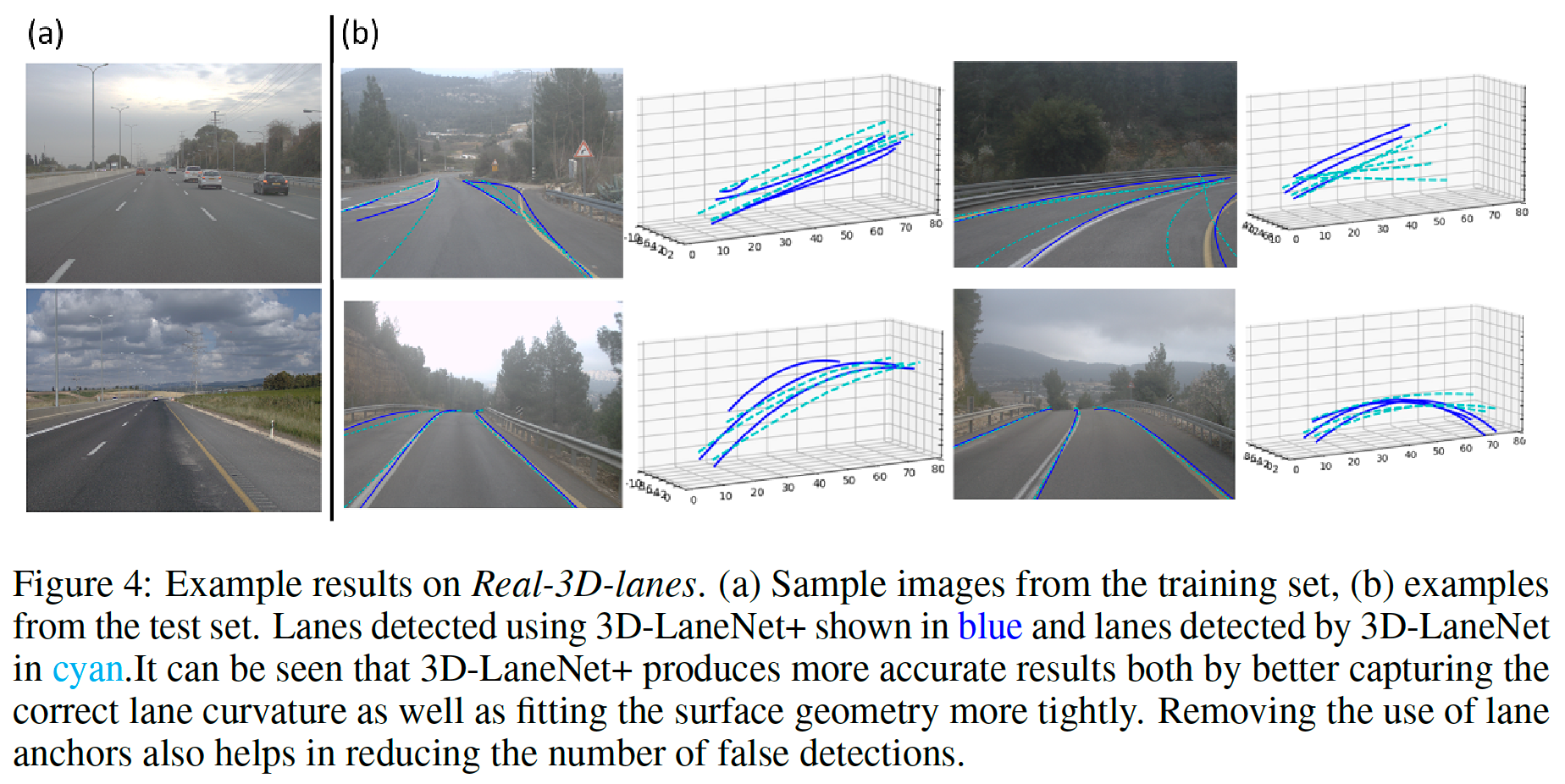
Datasets 使用两个 3D 车道数据集进行评估。第一个是 synthetic-3D-lanes [3],包含复杂道路几何形状的合成图像和 3D 地面真实车道注释。第二个是我们收集和注释的数据集,称为 Real-3D-lanes。该数据集(如 [3] 中注释)包含来自 19 个不同记录(不同地理位置,跨越 250 公里区域,在不同时间)的 327 K 张图像,以 20 fps 拍摄。数据被拆分,训练集(298 K 图像)主要由高速公路场景组成,而测试集由具有复杂曲率和路面几何形状的农村场景组成,拍摄地点不在训练集中。为了减少时间相关性,我们每 30 帧采样一次,为我们提供了 1000 张图像的测试集。图 4 中可以看到来自训练集和测试集的示例。
Evaluation 我们采用了原始 3D-LaneNet 中使用的相同评估协议,该协议建议将检测准确性与几何估计精度分开。检测精度是通过常用的平均平均精度(MAP)度量计算的。与[8]类似,我们采用了 IOU 度量,以在检测到的曲线和 GT 曲线之间相关联,该曲线是一般的,可以解释不经过预定义 y-value 的短车道或非平行车道。通过测量每个车道点相对于其相关的 GT 曲线的横向误差来评估几何精度。我们将整个数据集划分为接近范围(0-30m)和远距离(30-80m)的车道点,并计算每个范围的平均绝对侧向误差。
Implementation details 我们使用 ResNet34 骨干的双道路体系结构。我们的 BEV 投影覆盖了20.4m x 80m在最后一个删除的特征图中分配给我们的瓷砖网格 \(G _{W×H}\) ,W = 16,H = 26,因此每个图块(tile)代表 1.28m×3m 的路面。我们发现,与使用 Real-3D-Lanes 上的固定安装参数相比,预测相机角度 \(φ_{cam}\) 和高度 \(h _{cam}\) 的性能可以忽略不计,但是,在合成 3D-Lanes 上,我们遵循 [3] 的方法,并训练了网络以输出\(φ_{cam}\) 和 \(h _{cam}\)。我们的平均运行时间是使用单个 GPU(NVIDIA Quadro P5000)的 85.3 毫秒。
网络使用 ADAM 优化器以 16 的批大小进行训练,初始 lr 为 1e-5 进行 80K 次迭代,然后减少到 1e-6 进行另外 50K 次迭代。我们将 \(∆ _{pull}\) 和 \(∆ _{push}\)(方程 6、7)分别设置为 0.1 和 3,并在聚类之前对输出段分数 \(\tilde{c} _{ij}\) 使用粗略的 0.3 阈值。
5 Results
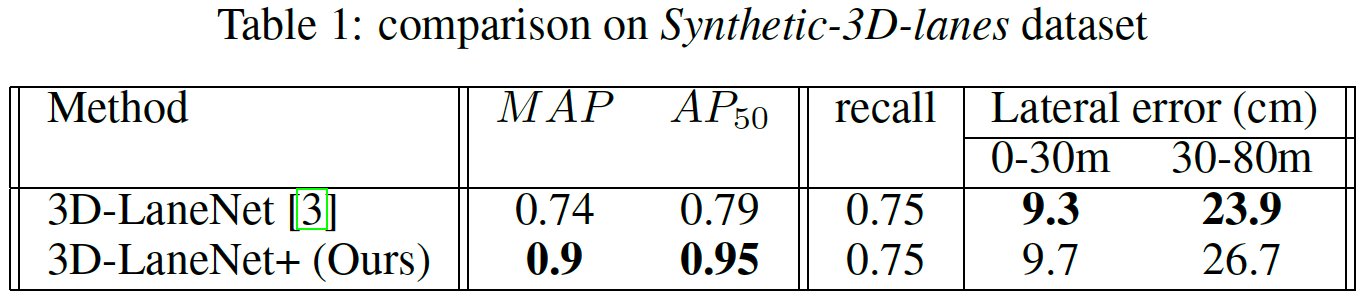
Synthetic-3D-lanes dataset 我们将 3D-LaneNet+ 方法与原始的 3D-LaneNet 进行了比较。结果显示在表1中。可以看出,我们的 MAP(在IOU阈值0.1:0.1:0.9处的 \(AP_{IOU%}\) 的平均值)和 \(AP _{50}\) 优于 3D-LaneNet 的MAP,同时显示出可比的侧向误差(对于IOU = 0.5和 recall= 0.75)。我们认为,主要原因是我们的半本地表示,我们的方法可以支持许多不同的车道拓扑,例如短道,分裂和合并仅在距离自我车辆的一定距离处出现的合并。这在图 3 中很明显,显示了 3D-LaneNet 未检测到的拆分和短车道,而是由 3D-LaneNet+ 检测到的示例。

Real world data 我们使用 Real-3D-lanes 数据集来证明我们的方法处理现实世界数据的能力,同时良好地推广到不同的车道拓扑,曲率和表面几何形状。表2总结了在同一训练集组上进行训练的 3D-LaneNet+ 与 3D-LaneNet 的结果。
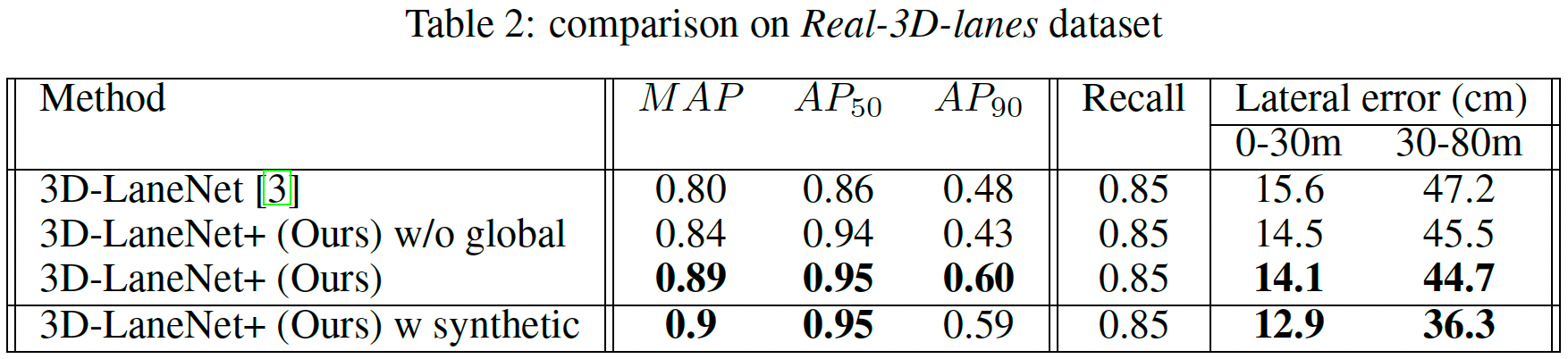
可以看出,3D-LaneNet+ 在整体 MAP 中比 3D-LaneNet 提高了 9 个点,并且降低了 3D 车道点的横向误差,取得了更好的效果。与训练集和测试集具有相同分布的 synthetic-3D-lanes 实验相比,该实验具有挑战性。在 Real-3D-lanes 的情况下,火车和测试集记录在不同的地理位置,并且具有不同的分布,即测试集表现出更复杂的曲率和表面几何形状。为了支持这一说法,我们检查了车道曲率和路面曲率的分布。在测试集上,车道曲线的曲率分数平均比训练集高一个数量级。测试集的路面曲率比火车集高两个数量级(示例图像见图 4b)。我们推广到这个测试集的能力证明了使用所提出的半局部瓦片表示的优势。
为了展示我们使用全局特征嵌入的聚类方法的重要性,我们将其与一个朴素的聚类替代方案进行了比较(表 2 ‘3D-LaneNet+ w/o global’)。该替代方案使用基于连续性和相似性启发式的简单贪心算法连接段。我们发现,当使用朴素聚类时,我们在整体 MAP 中损失了 5 个点,在 \(AP_{90}\) 中损失了 17 个点,这表明检测到的具有贪婪聚类的车道要短得多。此外,我们看到通过特征嵌入,我们获得了较低的横向误差。这可能表明特征嵌入学习也有助于预测更准确的片段。
我们还将仅在 Real-3D-lanes 上训练的模型与在 Real-3D-lanes 和 synthetic-3D-lanes 上训练的模型进行比较(表 2‘3D-LaneNet+ w synthetic’)。我们发现,复杂曲率和几何形状的额外 3D 训练数据有助于泛化,尽管它是合成的并且没有使用任何域适应技术。

Generalization to new cameras 我们现在检查我们的方法对新的看不见的相机的推广。为此,我们对未用于训练的内部评估数据集进行定性评估。从图 5 可以看出,我们的方法成功地从看不见的摄像头检测车道,而无需任何适应。图 5 中的示例显示了我们支持不同拓扑以及泛化到新场景的表示能力。从左上角顺时针可以看到垂直车道、分割车道、短车道,它们仅从交叉路口开始,而郊区场景则只有在火车组中根本不存在的道路边缘。请注意,在这些示例上训练我们的模型,包括具有交叉路口和垂直车道的城市场景,显然会取得更好的结果,而前一种方法 3D-LaneNet [3] 和 Gen-LaneNet [22] 不会从这种训练中受益数据,因为它们的受限表示。
6 Conclusions
在这项工作中,我们介绍了 3D-LaneNet+ ,一个 3D 车道检测框架,该框架基于并改进了最近发布的 3D-LaneNet。我们的主要目标是扩展 3D-LaneNet,使其能够检测以前不支持的车道拓扑,包括短车道、垂直于本车的车道、分叉、合并等。为了在这些具有挑战性的情况下提高性能,我们开发了一种无锚方法,方法是引入一种捕获拓扑不变的车道段的半局部表示,然后使用学习的全局嵌入将这些车道段聚集在一起到完整的车道曲线中。无需使用车道锚和车道模型拟合(如在 3D-LaneNet 中)允许 3D-LaneNet+ 支持和推广到不同的车道拓扑、曲率和表面几何形状。与 3D-LaneNet 相比,3D-LaneNet+ 的功效在合成数据和真实世界数据上都得到了证明,在 3D 车道检测方面产生了显着的改进。对结果的定性检查表明,该方法确实能够更好地成功检测任意拓扑的车道,包括拆分、合并、短车道等。通过这样做,我们朝着满足高速公路和城市场景中自动驾驶中 3D 车道检测的要求又迈出了一步。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号