
论文阅读笔记-Understanding Road Layout from Videos as a Whole
Title:Understanding Road Layout from Videos as a Whole
题目:从视频整体理解道路布局
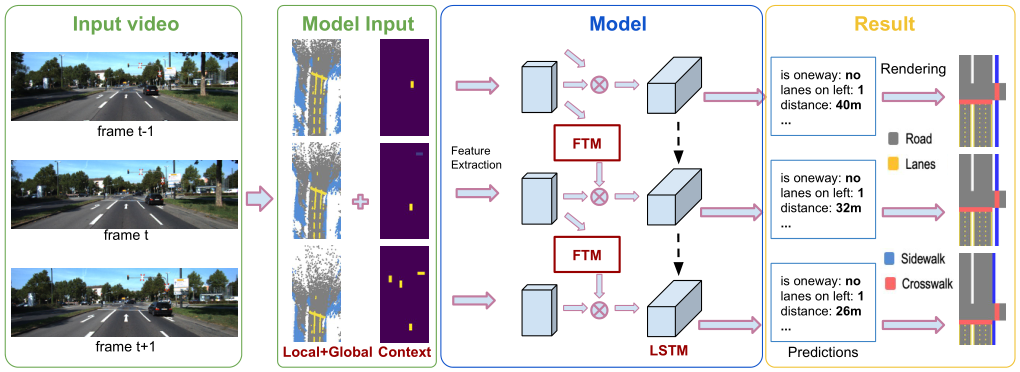
目标:给定一个视频序列,准确连贯的预测出每一帧的道路布局。主要估计俯视图。具体来说,对所有
输入:
- 局部的单个帧
- 整个视频序列
- 从上下文线索获得的信息
模型框架
模型:LSTM+FTM(Feature Transform Module)
- LSTM:结合长期预测的相干性。
- FTM:聚合有关估计的相机运动的信息并鼓励特征级别额一致性。
视频输入优于图像输入,但视频中的3D场景理解相对不足。
场景表示
参数化表示:三种不同的场景属性/参数,代表各种各样的道路场景布局。(遵循[38]中提出的参数表示)
某一视图下的道路场景表示为
基于 LSTM 的模型
整体模型定义:
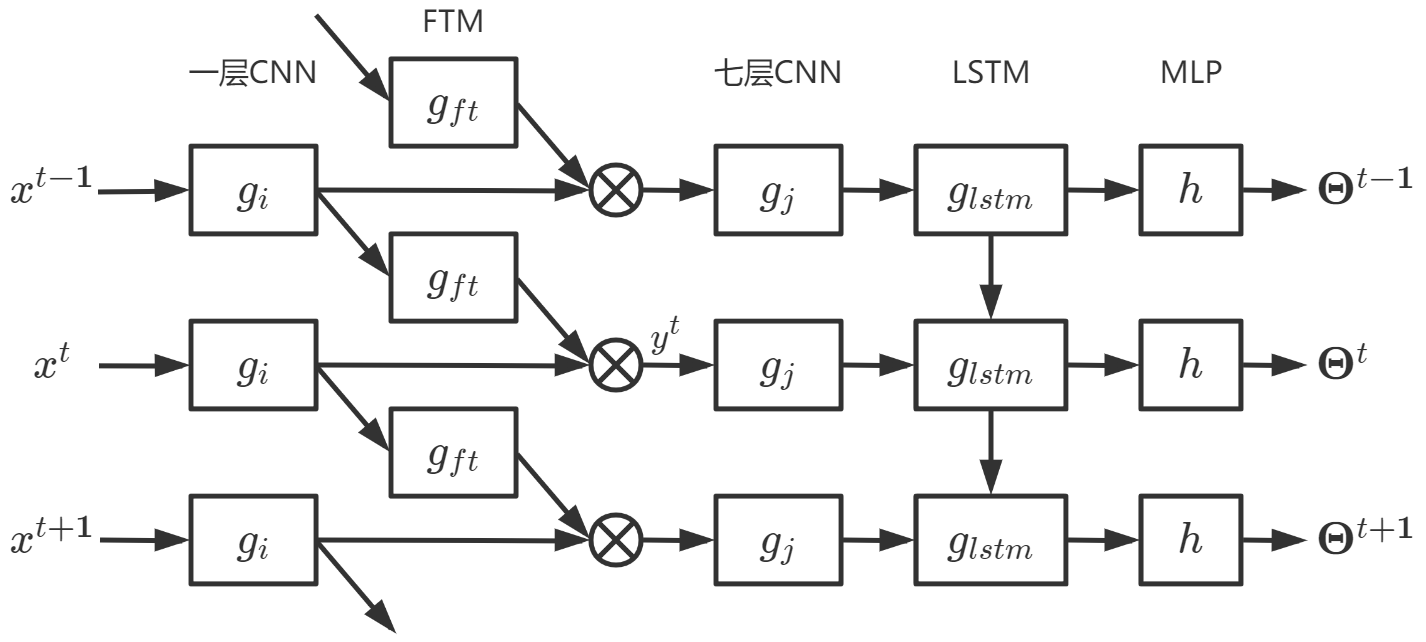
其中
FTM:
假设在
为聚合统一空间位置对应的特征,要在相邻帧中找到两个特征映射之间的对应关系,方法是计算相邻透视图之间的光流。
给定特征映射之间的对应关系,将时间步 t−1 的特征映射弯曲到当前时间步 t ,表示为:
其中
特征构成:
多种方式可以聚合特征映射
其中
对于 t=1 时的特殊情况,简单假设
损失函数:
给定由
其中 BEC 为 binary cross entropy , CE 为 cross entropy ,
将回归任务中的连续变量离散化——通过将以
模型输入
用视频中的上下文和全局信息来改进x的表示。
局部单帧信息
利用 bev 映射:
- (1)将所有道路像素反向投影到一个3D点云中
- (2)将所有3D点投影到x-y平面上
- (3)得到一幅道路的俯视图图像。
将每个像素的语义类概率分布从透视图转移到俯视图。
bev 表示为
上下文信息
本文中C=5类,道路,人行道,车道,人行横道,对象类(交通参与者,如:行人、汽车等)。
整合上下文线索的方法:
- 直接将对象的像素级概率映射到俯视图。
- 用边界框表示。
将现有的3D物体检测器应用到我们的视频中,并将检测结果映射到俯视图中。
为了减少角度预测的影响,进一步将角度分为两种类型,正面和侧面。只要预测的偏转角相对于相机 z 轴(向前方向)在
来自视频序列的全局信息
我们利用COLMAP中最先进的SfM和MVS算法,以及二维图像中的语义分割,从视频中生成顶视图地图(表示为bev-col)。
步骤:
- 我们首先对COLAMP返回的密集点云进行三维语义分割。
- 我们根据可见性映射将每个三维点投影到图像中,从二维语义分割中获得候选语义;
- 采用简单的赢者通吃策略来确定每个点的最终语义标签。
- 通过三维语义分割,我们可以提取道路部分的三维点,并通过RANSAC将其拟合为二维平面。
- 最后,我们可以根据相机姿态和我们预先定义的俯视图图像大小和分辨率,在2D道路平面上裁剪一个矩形框来生成bev-col;将平面上的三维点转换为图像中的像素点。
- 在获得全局平面参数后,利用摄像机姿态将全局平面参数转换为相对于摄像机的局部参数。
的三维重建的绝对规模可以从GPS或相机地面高度在驾驶场景中检索
最终的输入
- 1.来自单个帧的局部信息
- 2.来自视频的全局信息
- 3.对象级别的上下文信息
1 和 2 可以相互提供信息。
我们提出的俯视图语义地图bev-final在
[38] Ziyan Wang, Buyu Liu, Samuel Schulter, and Manmohan Chandraker. A parametric top-view representation of complex road scenes. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律