
论文阅读笔记-DAGMapper: Learning to Map by Discovering Lane Topology
Title:DAGMapper: Learning to Map by Discovering Lane Topology
题目:DAGMapper:通过发现车道拓扑学习制作地图
DAG:有向无环图
目标:通过车辆的一次通过获得的3D感官数据来绘制复杂高速公路的车道边界,这些车道由于分叉和合并而包含拓扑变化。
方法:首先利用安装在自动驾驶汽车上的激光雷达来构建一个鸟瞰世界的视图(BEV)。然后,我们利用一个深度网络提取下一车道网络的精确几何和拓扑。
输入:一个BEV聚合的激光雷达强度图像
输出:由深度神经网络参数化的车道边界的 DAG (与车道边界相对应的结构化折线的集合)。
难点:高速公路由于分叉和合并而包含复杂的拓扑变化
解决办法:通过在有向无环图模型 (DAG) 中构建推理问题来解决这些挑战,其中图的节点编码车道边界局部区域的几何和拓扑属性。由于我们事先不知道车道拓扑,我们也可以推断每个区域的 DAG 拓扑(即节点和边)。我们利用深度神经网络的力量来表示 DAG 中的条件概率。然后,我们设计了一个简单而有效的贪婪算法来增量估计图以及每个节点的状态。我们以端到端方式学习我们的深度神经网络的所有权重。我们称此方法为 DAGMapper 。
问题的制定和 DAG 的提取
标注道路:首先选取一个初始顶点,在车道边缘点击来跟踪车道边界,如果发生了拓扑变化(道路尽头、岔路)就进行相应的标注。
设
DAG 中每个节点
- 几何分量
- 几何分量
- 状态分量
- 1是否在不改变拓扑的情况下继续车道边界,
- 2在分叉处为新车道边界生成一个额外顶点,
- 0终止车道边界(在合并处)。


网络设计
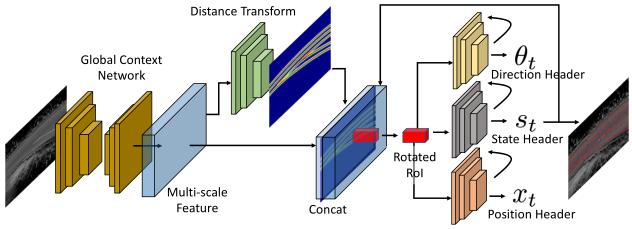
全局特征网络:该网络的目的是为头部网络构建特征以供使用。由于拓扑结构的变化通常是渐进的,如果特征仅捕捉局部的观测,或者网络的接收域很小,则很难推断出拓扑结构的变化。该网络的输入是鸟瞰图投影聚合 LiDAR 强度图像
距离变换网络:距离变换 (DT) (更确切地说,阈值逆距离变换)网络是一种有效的映射特征。它对图像中每一点到最近的车道边界的相对距离进行编码。
- 网络:采用了一个由一组残差层组成的 header
- 输入:以全局特征图F作为输入
- 输出:输出一个阈值化的逆 DT 图像
- 我们使用这个 DT 图像
- 将它作为一个额外的通道叠加到全局特征映射 F 中,并将其提供给其他 header 。我们的目标是使用
- 对
- 在使用 alg1 推断图之后,通过初始化图中没有覆盖的
- 将它作为一个额外的通道叠加到全局特征映射 F 中,并将其提供给其他 header 。我们的目标是使用
方向Header:该网络充当
- 网络:一个简单的卷积 RNN ,使用 RNN 来编码先前方向和状态的历史。
- 输入:一个双线性插值轴对齐的裁剪,来自于以
- 输出:下一个旋转RoI的方向向量。
位置Header:这个网络可以被视为
- 输入:前一个顶点的状态和位置
- 输出:
状态header:该 header 可以看作是
- 网络:利用卷积 RNN 对历史数据进行编码
- 输入:相同的位置标题的旋转 RoI
- 输出:三种状态的 softmax 概率
网络学习
采用多任务目标来监督模型的所有不同部分。 由于所有组件都是可区分的,我们可以端到端地学习我们的模型。 特别地,我们使用对称倒角距离将每条 GT 折线 Q 与其预测 P 匹配:
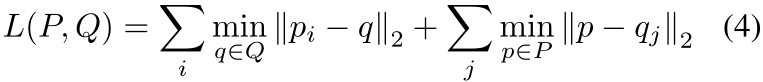
其中 p 和 q 分别是折线 P 和 Q 上的密集采样坐标。 为了学习拓扑状态,我们使用多标签焦点损失并稍作修改; 我们不是取所有个体损失的平均值,而是将它们相加并除以焦点权重的总和。 在这里,直觉是错误的预测被更多地强调并且不会被对应于正常状态的过采样类所抑制。 最后,我们使用余弦相似度损失和 l2 损失来学习方向和距离变换。
实验
数据集:我们的数据集由激光雷达点云组成,这些点云是通过驾驶一辆测绘车辆多次通过北美主要公路获得的。对于车辆的每次行驶,我们使用IMU里程数数据在一个任意原点的公共坐标系中聚合点云。在我们的离线地图设置中,局部区域点云的聚集来自过去以及未来的激光雷达扫描。接下来,我们将点云投影到鸟瞰图上,并通过取海拔最低的返回点的强度,以每像素5厘米的分辨率栅格化。由于我们对落在路面上的车道边界的高清映射很感兴趣,所以通过选取海拔最低的点,我们的目标是过滤掉来自其他移动车辆的激光雷达返回。
Baseline:由于文献中没有使用 BEV LiDAR 图像在高速公路上进行离线测绘的基线,我们基于 [6] 和 [21] 创建了两个基线。
- 基线:对于由 (DT 基线) 表示的基于 [6] 的第一个基线,我们使用具有额外上采样和残差层的全局特征网络的相同主干,仅在原始图像维度上预测逆阈值 DT 图像。我们在车道边界每侧的 32 个像素处对距离变换进行阈值处理。接下来,我们对 DT 图像进行二值化并进行骨架化以获得车道边界的密集表示。这是一个非常强大的基线,因为主干网络的整个容量都致力于预测 DT 图像。但是,我们的方法不同之处在于我们以端到端的方式以折线的形式输出车道边界的结构化表示,这适用于循环中的注释器以进行校正任务。
- 我们基于 (HRAN) 表示的 [21] 创建了第二个基线。 HRAN 架构的循环车道计数模块具有在图像底部从道路的左到右关注新车道边界的概念,这对于在分叉和合并处产生新车道边界的一般情况进行了分解。因此,我们通过在训练和推理过程中移除车道计数模块,而是为初始化提供地面实况起点,从而使该基线更加强大。请注意,我们的方法会自动从 DT 图像中推断出初始点。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端